ROMP support?
Hi @jinfagang, since SmoothNet can generalize well across backbones, we suggest you can simply use the pre-trained models to test the output poses from ROMP. Looking forward to your further feedback!
Actually, any pre-trained models can be used. Their differences are from the training dataset and backbones. For example, if you need to smooth on 3DPW, it will be better to use 3DPW-SPIN. 3D pre-trained models can be used for 6D rotations (avoid to use it on 3D angle or 4D quaterion). If you wonder the generalization ability of different checkpoints, please refer to Section 2.5 of the Appendix (https://arxiv.org/pdf/2112.13715.pdf page 26-27). Thanks!
I get it. I am trying use it on HybrIK, but it's output is quanternion, should I first convert quaternion back to rot mat, then apply to smoothnet, after that, back to quternion which I use?
Yes, make sure the input of SmoothNet is a continuous representation (e.g., 6d rotation matrix). The transformation function can be found here: https://github.com/cure-lab/SmoothNet/blob/main/lib/utils/geometry_utils.py#L35.
@ailingzengzzz thanks! I saw this function input is quat: size = [B, 4], is that ok I send it a frame pose (it's [24,4] in smpl), and then for all my frames? So that final output rotate mat could be [B, 24, 3, 3] ? B is frames num
First use quat_to_rotmat (size = [B*24, 4]->[B*24, 3, 3), then use rotmat_to_6d (output size = [B*24, 6]). Finally, you can reshape 6d rotation matrix to [B, 24, 6] via .reshape(-1, 24, 6).
@ailingzengzzz thanks for your adivce, am trying to load the model I got some weired error:
Unexpected key(s) in state_dict: "res_blocks.1.linear1.weight", "res_blocks.1.linear1.bias", "res_blocks.1.linear2.weight", "res_blocks.1.linear2.bias", "res_blocks.2.linear1.weight", "res_blocks.2.linear1.bias", "res_blocks.2.linear2.weight", "res_blocks.2.linear2.bias", "res_blocks.3.linear1.weight", "res_blocks.3.linear1.bias", "res_blocks.3.linear2.weight", "res_blocks.3.linear2.bias", "res_blocks.4.linear1.weight", "res_blocks.4.linear1.bias", "res_blocks.4.linear2.weight", "res_blocks.4.linear2.bias".
size mismatch for encoder.0.weight: copying a param with shape torch.Size([512, 32]) from checkpoint, the shape in current model is torch.Size([512, 100]).
What's difference between 3dpose pretrain model and SMPL pretrain model?
I downloaded SMPL PARE pretrained model, and define model wlikethis:
model = SmoothNet(
window_size=100,
output_size=100,
hidden_size=512,
res_hidden_size=16,
num_blocks=1,
dropout=0.5,
).to(device)
checkpoint = torch.load("checkpoint_32_smpl.pth.tar")
model.load_state_dict(checkpoint["state_dict"])
result not right. what's going wrong.
AssertionError: ('Input sequence length must be equal to the window size. ', 'Got x.shape[2]==6 and window_size==32')
torch.Size([1920, 24, 6])
can not send into model
Hi @jinfagang,
As shown in our paper, SmoothNet is a temporal-only model that shares weight across spatial dimensions (either 3d or 6d). We suggest simply using the 3d pre-trained models to smooth 6d rotation matrices (we comprehensively conduct these experiments across modalities, backbones, and datasets in Appendix).
SmoothNet needs to ensure the input and output length (window size), and hidden size are equal to the given configurations, which can be found in configs/ (https://github.com/cure-lab/SmoothNet/tree/main/configs).
The input of SmoothNet should be [N, T, C], where N can be any number, T is the sliding window size, and C is spatial dimensions (C is usually the Keypoints number * the keypoint dimension)
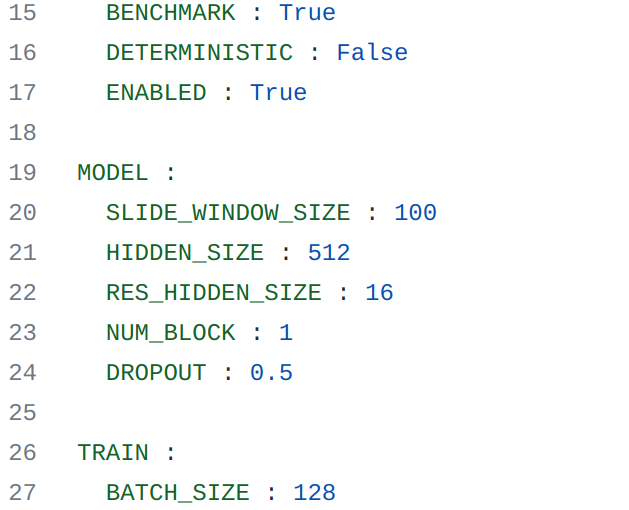
@ailingzengzzz Hi, your config provided, can not fit pretrain model you supply.
Please refer to our Evaluation part to set the corresponding window size.
python eval_smoothnet.py --cfg [config file] --checkpoint [pretrained checkpoint] --dataset_name [dataset name] --estimator [backbone estimator you use] --body_representation [smpl/3D/2D] --slide_window_size [slide window size]