关于递归监督
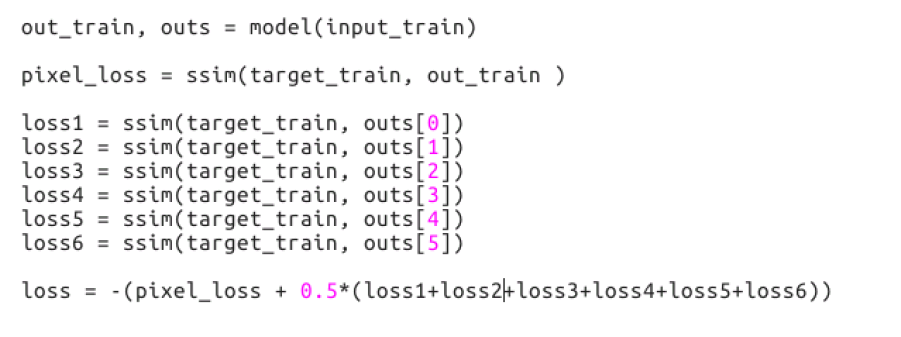
pixel_loss is ssim loss on the output of 6-th stage. out_train and outs[5] are same, the output of 6-th stage. So lambda_6=1.5 while all the other lambda=0.5
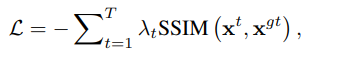
yes
Thank you for your contribution, I have a new question, so the final use of this article is not lambda_ 6 = 1.5 while all the other lambda = 0.5.in the final loss?
yes
Thank you for your contribution, I have a new question, so the final use of this article is not lambda_ 6 = 1.5 while all the other lambda = 0.5.in the final loss?
Yes. The final loss is only lambda_6 = 1
yes
Thank you for your contribution, I have a new question, so the final use of this article is not lambda_ 6 = 1.5 while all the other lambda = 0.5.in the final loss?
Yes. The final loss is only lambda_6 = 1 Thank you for your reply. Why do you only take lambda_ 1-5 = 0.5? lambda_ What about experiments where 1-5 equals 0.2 or 0.8? We look forward to your reply.
I did not try other settings, because I guess the final loss would ahieve best results.
Recursive loss makes the training more stable, while final loss may yield gradient vanish or explosion in few tries. Actually the results by final loss are better than recursive loss was surprising to me then.