Pod can not start anymore after scale down replica to zero
I have used Openshift and yester I found the problem about pod can not self-healing after I've for 2 week I have to uninstall cluster and reinstall to make it work again Now I found the step to make it crash by this step
- I setup follow by this url : https://github.com/cockroachdb/cockroach-operator/blob/master/openshift.md and it work find
- I try to scale down stateful set by change replicas from replicas: 3 to replicas: 0
- waiting for all pod terminated
- change replicas from replicas: 0 to replicas: 3
- then It won't be started anymore.. 6.This logs from container that try to start
Cockroach version : v20.1.5
Hi @pornpoi this actually appears to be a database bug and not an operator bug (but that's not to say we can't do something in the operator to prevent this condition from happening). I was told this may be fixed in the latest DB version (v20.2.7) - could you try that please? We might need to create an issue in github.com/cockroachdb/cockroach as well though
Hi @keith-mcclellan
Yes , I can try
However I have some problem when I try to use different version as default version.
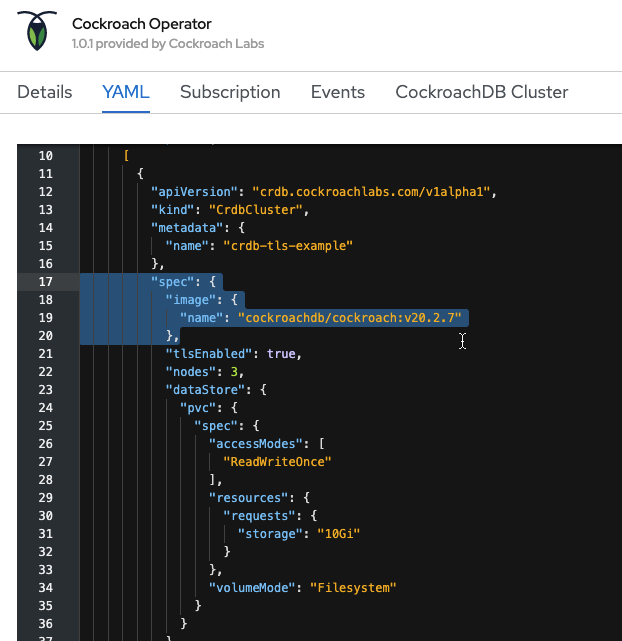 I found 1 of 3 pod still use default version (20.1.5)
Could you tell me about which is the correct practice to change version on operator?
I found 1 of 3 pod still use default version (20.1.5)
Could you tell me about which is the correct practice to change version on operator?
We discussed internally and we think the issue is that the default start pattern is one at a time, rather than all at once. We're looking into changing the default behavior of the SS to allow this to work. In the meantime, you could manually edit the StatefulSet and/or CR to manage the pods in parallel. See https://kubernetes.io/docs/tutorials/stateful-application/basic-stateful-set/#parallel-pod-management on how to do this.