Running out of memory trying to work with matrices
I am trying to work out the largest size matrices that I can multiply using my current gpu.
After getting a out of memory error I have not come up with any other solution than to restart r to keep working. Is there currently a solution to this?
Is there some easier way than trial and error to figure out how large matrices I can multiply together?
I have tried
chunk1:
rm(list = c("vclA","vclC","vclB")
gc()
for the code below (chunk2) which works as long as I don't run out of memory before calling the commands.
chunk2:
library(gpuR)
size <- 8100
A <- matrix(0.5, nrow=size, ncol=size)
B <- matrix(0.6, nrow=size, ncol=size)
vclA <- vclMatrix(A, type="float")
vclB <- vclMatrix(B, type="float")
vclC <- vclA %*% vclB
Running chunk2 one time does not give an error, running it two times in a row without running chunk1 in between gives the following error:
ViennaCL: FATAL ERROR: Kernel start failed for 'assign_cpu'.
ViennaCL: Smaller work sizes could not solve the problem.
Error in cpp_zero_vclMatrix(nrow, ncol, 6L, context_index - 1) :
ViennaCL: FATAL ERROR: CL_MEM_OBJECT_ALLOCATION_FAILURE
ViennaCL could not allocate memory on the device. Most likely the device simply ran out of memory.
If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
* Operating System
* Which OpenCL implementation (AMD, NVIDIA, etc.)
* ViennaCL version
Many thanks in advance!
My gpuInfo()
$deviceName
[1] "GeForce GTX 680"
$deviceVendor
[1] "NVIDIA Corporation"
$numberOfCores
[1] 8
$maxWorkGroupSize
[1] 1024
$maxWorkItemDim
[1] 3
$maxWorkItemSizes
[1] 1024 1024 64
$deviceMemory
[1] 2147483648
$clockFreq
[1] 1084
$localMem
[1] 49152
$maxAllocatableMem
[1] 536870912
$available
[1] "yes"
$deviceExtensions
[1] "cl_khr_global_int32_base_atomics" "cl_khr_global_int32_extended_atomics"
[3] "cl_khr_local_int32_base_atomics" "cl_khr_local_int32_extended_atomics"
[5] "cl_khr_fp64" "cl_khr_byte_addressable_store"
[7] "cl_khr_icd" "cl_khr_gl_sharing"
[9] "cl_nv_compiler_options" "cl_nv_device_attribute_query"
[11] "cl_nv_pragma_unroll" "cl_nv_d3d10_sharing"
[13] "cl_khr_d3d10_sharing" "cl_nv_d3d11_sharing"
[15] "cl_nv_copy_opts" "cl_nv_create_buffer"
$double_support
[1] TRUE
This is a problem I have encountered before and I'm still not sure how to resolve. I will need to try and look at it again to see if I can figure out how to clear memory without the need to manually do so.
Thanks for the reply!
I was also wondering: Once the error actually occurs, is there another solution to be able to keep working than to restart R Studio?
Simply calling gc() after the error occurred does not solve the problem.
Unfortunately not, I have been working on that as well. When the error is thrown somehow the initialized GPU objects are not cleaned up and become 'leaked' memory. I thought I had implemented sufficient smart pointers in the backend C++ but apparently still running in to the problem. I will need to go through the code some more and figure out why the memory ends up leaking.
Regarding your initial question, I believe the primary problem is that R internally calls gc() when it realizes it needs more memory. In this case, R is only seeing the small external pointers so it doesn't know to call gc(). Therefore, I think I will need to find a nice way of tracking how much GPU memory is in use (there is no OpenCL query to check the device unfortunately) and the internally calling gc() as needed so the user doesn't need to.
I don't know if this is helpful at all but I've been doing some more testing.
Running:
library(gpuR)
i<-3000
x<-matrix(rnorm(i^2),i,i)
y<-matrix(rnorm(i^2),i,i)
x1<-vclMatrix(x)
y1<-vclMatrix(y)
z1<-x1%*%y1
z<-as.matrix(z1)
rm(list=ls())
temp<-gc()
once works fine on my machine, running it twice in a row gives
Error in VCLtoMatSEXP(x@address, 8L) :
ViennaCL: FATAL ERROR: CL_OUT_OF_RESOURCES
ViennaCL tried to launch a compute kernel, but the device does not provide enough resources. Try changing the global and local work item sizes.
using gpuMatrix instead of vlcMatrix gives the same error.
Having the same issue, also a gtx 680 2gb Waiting for any workaround! Thanks! PD: The package is great, very intuitive!
To all concerned, please try the latest develop branch of gpuR and attempt your loops again. I have implemented some manual cleanup in the internal class finalizers that may help with this problem. I am unfortunately not in a position to completely reproduce problem at the moment.
Hello Charles and other gpuR users!
I can confirm that I can now multiply large matrices (3 GB x 3 GB) on a linux server on this gpu device:
context platform platform_index 1 1 NVIDIA Corporation: OpenCL 1.2 CUDA 9.1.98 0 device device_index device_type 1 Tesla P100-PCIE-12GB 0 gpu
Thanks so much for efforts - I'll be sure to give an acknowledgement and cite in our next work.
Hold the phone it looks like i'm still getting the error. sorry for the premature good news. I'll provide a working example soon
@andreasostling @martinguerrero89 @mjaniec2013 ping, did you happen to confirm if the changes in develop didn't solve the problem?
Hi @cdeterman!, I haven't tried the develop version yet. What I did previously was callining gc() at the end of each loop and that is working fine for the moment. Surely I will be trying the new version soon and will come back with results. Thank you very much for your effort!
Have CL_MEM_OBJECT_ALLOCATION_FAILURE error again :(
Have been trying to monitor GPU memory when the code is executed and after. Seems quite a bit more memory than required by the matrices to be multiplied is allocated. A question come to my mind: how much memory is actually needed by matrix multiplication algorithm?
gpuR v2.0.2, development version, freshly pulled R 3.4.3 x64 Win 10 GPU: GTX 1050 Ti 4GB
Maximum size of matrices I'm able to multiply: 8000x8000, 488 MB.
I get the error when I try to multiply for the second time. I clear memory at the beginning.
@mjaniec2013 how much memory are you seeing allocated? We need to keep in mind the 128 padding as well. Furthermore, to make sure, please be sure to note if you are using float or double precision. Essentially I would expect to see, for double precision 3 * 8064 * 8064 * 8 ~= 1.56 GB. At least when run the first time with vclMatrix objects. The key for me is if it is continuing to increase with successive iterations especially when you call gc().
Tested with smaller matrices (5k * 5k) and got error again at first test run.
Matrix size as reported by object.size is 190.7Mb.
GPU memory usage jumped to >1200 Mb and stays there. Will go down after rm & gc.
I use double.
Test code I use:
n <- 5000
A <- matrix( rnorm(n^2), nrow=n ) B <- matrix( rnorm(n^2), nrow=n )
vclA = vclMatrix(A, type="double") vclB = vclMatrix(B, type="double")
vclC = vclA %*% vclB
MJ
MJ
On Thu, Mar 15, 2018 at 3:59 PM, Charles Determan [email protected] wrote:
@mjaniec2013 https://github.com/mjaniec2013 how much memory are you seeing allocated? We need to keep in mind the 128 padding as well. Furthermore, to make sure, please be sure to note if you are using float or double precision. Essentially I would expect to see, for double precision 3 * 8064 * 8064 * 8 ~= 1.56 GB. At least when run the first time with vclMatrix objects. The key for me is if it is continuing to increase with successive iterations especially when you call gc().
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373405838, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlstybRR15-Nkcl-3p8J8bCWeAKRoks5teoHMgaJpZM4QNTQn .
@mjaniec2013 thank you, that helps. It looks like the memory is approximately doubling. As the internal matrix sizes would be 5120x5120. The math comes out for 3 matrices at double precision to 3 * 5120 * 5120 * 8 * 2 ~= 1.2GB. I have just made another commit to develop that I think should help. Please try the latest code at let me know if anything has improved.
5k * 5k matrix again.
Error in cpp_vclMatrix_gemm(A@address, B@address, C@address, 8L) : ViennaCL: FATAL ERROR: CL_INVALID_PROGRAM_EXECUTABLE. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance!
format(object.size(A), units = "MB")[1] "190.7 Mb"
vclA = vclMatrix(A, type="double")> vclB = vclMatrix(B, type="double")> > vclC = vclA %*% vclBBuild Status = -2 ( Err = -5 ) Log:
Sources: #pragma OPENCL EXTENSION cl_khr_fp64 : enable attribute((reqd_work_group_size(8,8,1))) __kernel void _prod_NN(unsigned int M, unsigned int N, unsigned int K, __global double* obj0_pointer,unsigned int obj0_ld,unsigned int obj0_start2,unsigned int obj0_start1,unsigned int obj0_stride2,unsigned int obj0_stride1,__global double* obj1_pointer,unsigned int obj1_ld,unsigned int obj1_start1,unsigned int obj1_start2,unsigned int obj1_stride1,unsigned int obj1_stride2,__global double* obj3_pointer,unsigned int obj3_ld,unsigned int obj3_start1,unsigned int obj3_start2,unsigned int obj3_stride1,unsigned int obj3_stride2,double obj4,double obj5) { obj0_pointer += (obj0_start1) * obj0_ld + ( obj0_start2); obj1_pointer += (obj1_start1) + ( obj1_start2) * obj1_ld; obj3_pointer += (obj3_start1) + ( obj3_start2) * obj3_ld; obj0_ld *= obj0_stride1; obj1_ld *= obj1_stride2; obj3_ld *= obj3_stride2; double rC[4][4] = {{(double)0}}; double rA[1][4]; double rB[1][4];__local double lA[264];__local double lB[264]; size_t gidx = get_group_id(0); size_t gidy = get_group_id(1); size_t idx = get_local_id(0); size_t idy = get_local_id(1);
size_t idt = 8*idy + idx;
size_t idxT = idt % 8;
size_t idyT = idt / 8;
bool in_bounds_m[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m[m] = gidx*32 + idx + m*8 < M;
bool in_bounds_m_local[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m_local[m] = gidx*32 + idxT + m*8 < M;
bool in_bounds_n[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n[n] = gidy*32 + idy + n*8 < N;
bool in_bounds_n_local[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n_local[n] = gidy*32 + idyT + n*8 < N;
obj1_pointer += (gidx*32 + idxT)*obj1_stride1 + idyT*obj1_ld;
obj3_pointer += idxT*obj3_stride1 + gidy*32*obj3_ld + idyT*obj3_ld;
size_t K_size_t = K;
for(size_t block_k=0; block_k < K_size_t; block_k+=8){
__local double* plA = lA + idyT*33 + 1*idxT;
__local double* plB = lB + idxT*33+ idyT;
barrier(CLK_LOCAL_MEM_FENCE);
(plA + 0)[0] = in_bounds_m_local[0]?obj1_pointer[0*obj1_ld +
0obj1_stride1]:0; (plA + 8)[0] = in_bounds_m_local[1]?obj1_pointer[0obj1_ld + 8obj1_stride1]:0; (plA + 16)[0] = in_bounds_m_local[2]?obj1_pointer[0obj1_ld + 16obj1_stride1]:0; (plA + 24)[0] = in_bounds_m_local[3]?obj1_pointer[0obj1_ld + 24obj1_stride1]:0; (plB + 0)[0] = in_bounds_n_local[0]?obj3_pointer[0obj3_ld + 0obj3_stride1]:0; (plB + 8)[0] = in_bounds_n_local[1]?obj3_pointer[8obj3_ld + 0obj3_stride1]:0; (plB + 16)[0] = in_bounds_n_local[2]?obj3_pointer[16obj3_ld + 0obj3_stride1]:0; (plB + 24)[0] = in_bounds_n_local[3]?obj3_pointer[24obj3_ld + 0obj3_stride1]:0; barrier(CLK_LOCAL_MEM_FENCE); size_t offA = 1idx; size_t offB = 1idy; for(size_t k = 0; k < 8 && (block_k + k < K_size_t); k+=1){ #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t mm = 0; mm < 4; mm++) { rA[kk][mm1+0] = lA[offA + mm8+0+ kk33]; } #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t nn = 0; nn < 4; nn++) { rB[kk][nn1+0] = lB[offB + nn8+0+ kk33]; } offA += 33; offB += 33; #pragma unroll 1 for(size_t kk = 0; kk <1; ++kk) { rC[0][0]=fma(rA[kk][0],rB[kk][0],rC[0][0]); rC[1][0]=fma(rA[kk][1],rB[kk][0],rC[1][0]); rC[2][0]=fma(rA[kk][2],rB[kk][0],rC[2][0]); rC[3][0]=fma(rA[kk][3],rB[kk][0],rC[3][0]); rC[0][1]=fma(rA[kk][0],rB[kk][1],rC[0][1]); rC[1][1]=fma(rA[kk][1],rB[kk][1],rC[1][1]); rC[2][1]=fma(rA[kk][2],rB[kk][1],rC[2][1]); rC[3][1]=fma(rA[kk][3],rB[kk][1],rC[3][1]); rC[0][2]=fma(rA[kk][0],rB[kk][2],rC[0][2]); rC[1][2]=fma(rA[kk][1],rB[kk][2],rC[1][2]); rC[2][2]=fma(rA[kk][2],rB[kk][2],rC[2][2]); rC[3][2]=fma(rA[kk][3],rB[kk][2],rC[3][2]); rC[0][3]=fma(rA[kk][0],rB[kk][3],rC[0][3]); rC[1][3]=fma(rA[kk][1],rB[kk][3],rC[1][3]); rC[2][3]=fma(rA[kk][2],rB[kk][3],rC[2][3]); rC[3][3]=fma(rA[kk][3],rB[kk][3],rC[3][3]); } } obj1_pointer += 8obj1_ld; obj3_pointer += 8obj3_stride1; } obj0_pointer += gidx32obj0_ld; obj0_pointer += idx1obj0_ld; obj0_pointer += gidy32obj0_stride2; obj0_pointer += idy1obj0_stride2; if (in_bounds_m[0] && in_bounds_n[0]) obj0_pointer[0obj0_ld] = rC[0][0]obj4+ obj0_pointer[0obj0_ld]obj5; if (in_bounds_m[1] && in_bounds_n[0]) obj0_pointer[8obj0_ld] = rC[1][0]obj4+ obj0_pointer[8obj0_ld]obj5; if (in_bounds_m[2] && in_bounds_n[0]) obj0_pointer[16obj0_ld] = rC[2][0]obj4+ obj0_pointer[16obj0_ld]obj5; if (in_bounds_m[3] && in_bounds_n[0]) obj0_pointer[24obj0_ld] = rC[3][0]obj4+ obj0_pointer[24obj0_ld]obj5; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[1]) obj0_pointer[0obj0_ld] = rC[0][1]obj4+ obj0_pointer[0obj0_ld]obj5; if (in_bounds_m[1] && in_bounds_n[1]) obj0_pointer[8obj0_ld] = rC[1][1]obj4+ obj0_pointer[8obj0_ld]obj5; if (in_bounds_m[2] && in_bounds_n[1]) obj0_pointer[16obj0_ld] = rC[2][1]obj4+ obj0_pointer[16obj0_ld]obj5; if (in_bounds_m[3] && in_bounds_n[1]) obj0_pointer[24obj0_ld] = rC[3][1]obj4+ obj0_pointer[24obj0_ld]obj5; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[2]) obj0_pointer[0obj0_ld] = rC[0][2]obj4+ obj0_pointer[0obj0_ld]obj5; if (in_bounds_m[1] && in_bounds_n[2]) obj0_pointer[8obj0_ld] = rC[1][2]obj4+ obj0_pointer[8obj0_ld]obj5; if (in_bounds_m[2] && in_bounds_n[2]) obj0_pointer[16obj0_ld] = rC[2][2]obj4+ obj0_pointer[16obj0_ld]obj5; if (in_bounds_m[3] && in_bounds_n[2]) obj0_pointer[24obj0_ld] = rC[3][2]obj4+ obj0_pointer[24obj0_ld]obj5; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[3]) obj0_pointer[0obj0_ld] = rC[0][3]obj4+ obj0_pointer[0obj0_ld]obj5; if (in_bounds_m[1] && in_bounds_n[3]) obj0_pointer[8obj0_ld] = rC[1][3]obj4+ obj0_pointer[8obj0_ld]obj5; if (in_bounds_m[2] && in_bounds_n[3]) obj0_pointer[16obj0_ld] = rC[2][3]obj4+ obj0_pointer[16obj0_ld]obj5; if (in_bounds_m[3] && in_bounds_n[3]) obj0_pointer[24obj0_ld] = rC[3][3]obj4+ obj0_pointer[24obj0_ld]obj5; obj0_pointer += 8obj0_stride2; } attribute((reqd_work_group_size(8,8,1))) __kernel void _prod_TN(unsigned int M, unsigned int N, unsigned int K, __global double obj0_pointer,unsigned int obj0_ld,unsigned int obj0_start2,unsigned int obj0_start1,unsigned int obj0_stride2,unsigned int obj0_stride1,__global double* obj1_pointer,unsigned int obj1_ld,unsigned int obj1_start1,unsigned int obj1_start2,unsigned int obj1_stride1,unsigned int obj1_stride2,__global double* obj4_pointer,unsigned int obj4_ld,unsigned int obj4_start1,unsigned int obj4_start2,unsigned int obj4_stride1,unsigned int obj4_stride2,double obj5,double obj6) { obj0_pointer += (obj0_start1) * obj0_ld + ( obj0_start2); obj1_pointer += (obj1_start1) + ( obj1_start2) * obj1_ld; obj4_pointer += (obj4_start1) + ( obj4_start2) * obj4_ld; obj0_ld *= obj0_stride1; obj1_ld *= obj1_stride2; obj4_ld *= obj4_stride2; double rC[4][4] = {{(double)0}}; double rA[1][4]; double rB[1][4];__local double lA[264];__local double lB[264]; size_t gidx = get_group_id(0); size_t gidy = get_group_id(1); size_t idx = get_local_id(0); size_t idy = get_local_id(1);
size_t idt = 8*idy + idx;
size_t idxT = idt % 8;
size_t idyT = idt / 8;
bool in_bounds_m[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m[m] = gidx*32 + idx + m*8 < M;
bool in_bounds_m_local[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m_local[m] = gidx*32 + idyT + m*8 < M;
bool in_bounds_n[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n[n] = gidy*32 + idy + n*8 < N;
bool in_bounds_n_local[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n_local[n] = gidy*32 + idyT + n*8 < N;
obj1_pointer += idxT*obj1_stride1 + gidx*32*obj1_ld + idyT*obj1_ld;
obj4_pointer += idxT*obj4_stride1 + gidy*32*obj4_ld + idyT*obj4_ld;
size_t K_size_t = K;
for(size_t block_k=0; block_k < K_size_t; block_k+=8){
__local double* plA = lA + idxT*33 + idyT;
__local double* plB = lB + idxT*33+ idyT;
barrier(CLK_LOCAL_MEM_FENCE);
(plA + 0)[0] = in_bounds_m_local[0]?obj1_pointer[0*obj1_ld +
0obj1_stride1]:0; (plA + 8)[0] = in_bounds_m_local[1]?obj1_pointer[8obj1_ld + 0obj1_stride1]:0; (plA + 16)[0] = in_bounds_m_local[2]?obj1_pointer[16obj1_ld + 0obj1_stride1]:0; (plA + 24)[0] = in_bounds_m_local[3]?obj1_pointer[24obj1_ld + 0obj1_stride1]:0; (plB + 0)[0] = in_bounds_n_local[0]?obj4_pointer[0obj4_ld + 0obj4_stride1]:0; (plB + 8)[0] = in_bounds_n_local[1]?obj4_pointer[8obj4_ld + 0obj4_stride1]:0; (plB + 16)[0] = in_bounds_n_local[2]?obj4_pointer[16obj4_ld + 0obj4_stride1]:0; (plB + 24)[0] = in_bounds_n_local[3]?obj4_pointer[24obj4_ld + 0obj4_stride1]:0; barrier(CLK_LOCAL_MEM_FENCE); size_t offA = 1idx; size_t offB = 1idy; for(size_t k = 0; k < 8 && (block_k + k < K_size_t); k+=1){ #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t mm = 0; mm < 4; mm++) { rA[kk][mm1+0] = lA[offA + mm8+0+ kk33]; } #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t nn = 0; nn < 4; nn++) { rB[kk][nn1+0] = lB[offB + nn8+0+ kk33]; } offA += 33; offB += 33; #pragma unroll 1 for(size_t kk = 0; kk <1; ++kk) { rC[0][0]=fma(rA[kk][0],rB[kk][0],rC[0][0]); rC[1][0]=fma(rA[kk][1],rB[kk][0],rC[1][0]); rC[2][0]=fma(rA[kk][2],rB[kk][0],rC[2][0]); rC[3][0]=fma(rA[kk][3],rB[kk][0],rC[3][0]); rC[0][1]=fma(rA[kk][0],rB[kk][1],rC[0][1]); rC[1][1]=fma(rA[kk][1],rB[kk][1],rC[1][1]); rC[2][1]=fma(rA[kk][2],rB[kk][1],rC[2][1]); rC[3][1]=fma(rA[kk][3],rB[kk][1],rC[3][1]); rC[0][2]=fma(rA[kk][0],rB[kk][2],rC[0][2]); rC[1][2]=fma(rA[kk][1],rB[kk][2],rC[1][2]); rC[2][2]=fma(rA[kk][2],rB[kk][2],rC[2][2]); rC[3][2]=fma(rA[kk][3],rB[kk][2],rC[3][2]); rC[0][3]=fma(rA[kk][0],rB[kk][3],rC[0][3]); rC[1][3]=fma(rA[kk][1],rB[kk][3],rC[1][3]); rC[2][3]=fma(rA[kk][2],rB[kk][3],rC[2][3]); rC[3][3]=fma(rA[kk][3],rB[kk][3],rC[3][3]); } } obj1_pointer += 8obj1_stride1; obj4_pointer += 8obj4_stride1; } obj0_pointer += gidx32obj0_ld; obj0_pointer += idx1obj0_ld; obj0_pointer += gidy32obj0_stride2; obj0_pointer += idy1obj0_stride2; if (in_bounds_m[0] && in_bounds_n[0]) obj0_pointer[0obj0_ld] = rC[0][0]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[0]) obj0_pointer[8obj0_ld] = rC[1][0]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[0]) obj0_pointer[16obj0_ld] = rC[2][0]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[0]) obj0_pointer[24obj0_ld] = rC[3][0]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[1]) obj0_pointer[0obj0_ld] = rC[0][1]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[1]) obj0_pointer[8obj0_ld] = rC[1][1]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[1]) obj0_pointer[16obj0_ld] = rC[2][1]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[1]) obj0_pointer[24obj0_ld] = rC[3][1]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[2]) obj0_pointer[0obj0_ld] = rC[0][2]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[2]) obj0_pointer[8obj0_ld] = rC[1][2]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[2]) obj0_pointer[16obj0_ld] = rC[2][2]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[2]) obj0_pointer[24obj0_ld] = rC[3][2]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[3]) obj0_pointer[0obj0_ld] = rC[0][3]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[3]) obj0_pointer[8obj0_ld] = rC[1][3]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[3]) obj0_pointer[16obj0_ld] = rC[2][3]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[3]) obj0_pointer[24obj0_ld] = rC[3][3]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; } attribute((reqd_work_group_size(8,8,1))) __kernel void _prod_NT(unsigned int M, unsigned int N, unsigned int K, __global double obj0_pointer,unsigned int obj0_ld,unsigned int obj0_start2,unsigned int obj0_start1,unsigned int obj0_stride2,unsigned int obj0_stride1,__global double* obj1_pointer,unsigned int obj1_ld,unsigned int obj1_start1,unsigned int obj1_start2,unsigned int obj1_stride1,unsigned int obj1_stride2,__global double* obj3_pointer,unsigned int obj3_ld,unsigned int obj3_start1,unsigned int obj3_start2,unsigned int obj3_stride1,unsigned int obj3_stride2,double obj5,double obj6) { obj0_pointer += (obj0_start1) * obj0_ld + ( obj0_start2); obj1_pointer += (obj1_start1) + ( obj1_start2) * obj1_ld; obj3_pointer += (obj3_start1) + ( obj3_start2) * obj3_ld; obj0_ld *= obj0_stride1; obj1_ld *= obj1_stride2; obj3_ld *= obj3_stride2; double rC[4][4] = {{(double)0}}; double rA[1][4]; double rB[1][4];__local double lA[264];__local double lB[264]; size_t gidx = get_group_id(0); size_t gidy = get_group_id(1); size_t idx = get_local_id(0); size_t idy = get_local_id(1);
size_t idt = 8*idy + idx;
size_t idxT = idt % 8;
size_t idyT = idt / 8;
bool in_bounds_m[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m[m] = gidx*32 + idx + m*8 < M;
bool in_bounds_m_local[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m_local[m] = gidx*32 + idxT + m*8 < M;
bool in_bounds_n[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n[n] = gidy*32 + idy + n*8 < N;
bool in_bounds_n_local[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n_local[n] = gidy*32 + idxT + n*8 < N;
obj1_pointer += (gidx*32 + idxT)*obj1_stride1 + idyT*obj1_ld;
obj3_pointer += (gidy*32 + idxT)*obj3_stride1 + idyT*obj3_ld;
size_t K_size_t = K;
for(size_t block_k=0; block_k < K_size_t; block_k+=8){
__local double* plA = lA + idyT*33 + 1*idxT;
__local double* plB = lB + idyT*33 + 1*idxT;
barrier(CLK_LOCAL_MEM_FENCE);
(plA + 0)[0] = in_bounds_m_local[0]?obj1_pointer[0*obj1_ld +
0obj1_stride1]:0; (plA + 8)[0] = in_bounds_m_local[1]?obj1_pointer[0obj1_ld + 8obj1_stride1]:0; (plA + 16)[0] = in_bounds_m_local[2]?obj1_pointer[0obj1_ld + 16obj1_stride1]:0; (plA + 24)[0] = in_bounds_m_local[3]?obj1_pointer[0obj1_ld + 24obj1_stride1]:0; (plB + 0)[0] = in_bounds_n_local[0]?obj3_pointer[0obj3_ld + 0obj3_stride1]:0; (plB + 8)[0] = in_bounds_n_local[1]?obj3_pointer[0obj3_ld + 8obj3_stride1]:0; (plB + 16)[0] = in_bounds_n_local[2]?obj3_pointer[0obj3_ld + 16obj3_stride1]:0; (plB + 24)[0] = in_bounds_n_local[3]?obj3_pointer[0obj3_ld + 24obj3_stride1]:0; barrier(CLK_LOCAL_MEM_FENCE); size_t offA = 1idx; size_t offB = 1idy; for(size_t k = 0; k < 8 && (block_k + k < K_size_t); k+=1){ #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t mm = 0; mm < 4; mm++) { rA[kk][mm1+0] = lA[offA + mm8+0+ kk33]; } #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t nn = 0; nn < 4; nn++) { rB[kk][nn1+0] = lB[offB + nn8+0+ kk33]; } offA += 33; offB += 33; #pragma unroll 1 for(size_t kk = 0; kk <1; ++kk) { rC[0][0]=fma(rA[kk][0],rB[kk][0],rC[0][0]); rC[1][0]=fma(rA[kk][1],rB[kk][0],rC[1][0]); rC[2][0]=fma(rA[kk][2],rB[kk][0],rC[2][0]); rC[3][0]=fma(rA[kk][3],rB[kk][0],rC[3][0]); rC[0][1]=fma(rA[kk][0],rB[kk][1],rC[0][1]); rC[1][1]=fma(rA[kk][1],rB[kk][1],rC[1][1]); rC[2][1]=fma(rA[kk][2],rB[kk][1],rC[2][1]); rC[3][1]=fma(rA[kk][3],rB[kk][1],rC[3][1]); rC[0][2]=fma(rA[kk][0],rB[kk][2],rC[0][2]); rC[1][2]=fma(rA[kk][1],rB[kk][2],rC[1][2]); rC[2][2]=fma(rA[kk][2],rB[kk][2],rC[2][2]); rC[3][2]=fma(rA[kk][3],rB[kk][2],rC[3][2]); rC[0][3]=fma(rA[kk][0],rB[kk][3],rC[0][3]); rC[1][3]=fma(rA[kk][1],rB[kk][3],rC[1][3]); rC[2][3]=fma(rA[kk][2],rB[kk][3],rC[2][3]); rC[3][3]=fma(rA[kk][3],rB[kk][3],rC[3][3]); } } obj1_pointer += 8obj1_ld; obj3_pointer += 8obj3_ld; } obj0_pointer += gidx32obj0_ld; obj0_pointer += idx1obj0_ld; obj0_pointer += gidy32obj0_stride2; obj0_pointer += idy1obj0_stride2; if (in_bounds_m[0] && in_bounds_n[0]) obj0_pointer[0obj0_ld] = rC[0][0]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[0]) obj0_pointer[8obj0_ld] = rC[1][0]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[0]) obj0_pointer[16obj0_ld] = rC[2][0]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[0]) obj0_pointer[24obj0_ld] = rC[3][0]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[1]) obj0_pointer[0obj0_ld] = rC[0][1]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[1]) obj0_pointer[8obj0_ld] = rC[1][1]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[1]) obj0_pointer[16obj0_ld] = rC[2][1]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[1]) obj0_pointer[24obj0_ld] = rC[3][1]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[2]) obj0_pointer[0obj0_ld] = rC[0][2]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[2]) obj0_pointer[8obj0_ld] = rC[1][2]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[2]) obj0_pointer[16obj0_ld] = rC[2][2]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[2]) obj0_pointer[24obj0_ld] = rC[3][2]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[3]) obj0_pointer[0obj0_ld] = rC[0][3]obj5+ obj0_pointer[0obj0_ld]obj6; if (in_bounds_m[1] && in_bounds_n[3]) obj0_pointer[8obj0_ld] = rC[1][3]obj5+ obj0_pointer[8obj0_ld]obj6; if (in_bounds_m[2] && in_bounds_n[3]) obj0_pointer[16obj0_ld] = rC[2][3]obj5+ obj0_pointer[16obj0_ld]obj6; if (in_bounds_m[3] && in_bounds_n[3]) obj0_pointer[24obj0_ld] = rC[3][3]obj5+ obj0_pointer[24obj0_ld]obj6; obj0_pointer += 8obj0_stride2; } attribute((reqd_work_group_size(8,8,1))) __kernel void _prod_TT(unsigned int M, unsigned int N, unsigned int K, __global double obj0_pointer,unsigned int obj0_ld,unsigned int obj0_start2,unsigned int obj0_start1,unsigned int obj0_stride2,unsigned int obj0_stride1,__global double* obj1_pointer,unsigned int obj1_ld,unsigned int obj1_start1,unsigned int obj1_start2,unsigned int obj1_stride1,unsigned int obj1_stride2,__global double* obj4_pointer,unsigned int obj4_ld,unsigned int obj4_start1,unsigned int obj4_start2,unsigned int obj4_stride1,unsigned int obj4_stride2,double obj6,double obj7) { obj0_pointer += (obj0_start1) * obj0_ld + ( obj0_start2); obj1_pointer += (obj1_start1) + ( obj1_start2) * obj1_ld; obj4_pointer += (obj4_start1) + ( obj4_start2) * obj4_ld; obj0_ld *= obj0_stride1; obj1_ld *= obj1_stride2; obj4_ld *= obj4_stride2; double rC[4][4] = {{(double)0}}; double rA[1][4]; double rB[1][4];__local double lA[264];__local double lB[264]; size_t gidx = get_group_id(0); size_t gidy = get_group_id(1); size_t idx = get_local_id(0); size_t idy = get_local_id(1);
size_t idt = 8*idy + idx;
size_t idxT = idt % 8;
size_t idyT = idt / 8;
bool in_bounds_m[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m[m] = gidx*32 + idx + m*8 < M;
bool in_bounds_m_local[4];
for(size_t m = 0; m < 4; m++)
in_bounds_m_local[m] = gidx*32 + idyT + m*8 < M;
bool in_bounds_n[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n[n] = gidy*32 + idy + n*8 < N;
bool in_bounds_n_local[4];
for(size_t n = 0; n < 4; n++)
in_bounds_n_local[n] = gidy*32 + idxT + n*8 < N;
obj1_pointer += idxT*obj1_stride1 + gidx*32*obj1_ld + idyT*obj1_ld;
obj4_pointer += (gidy*32 + idxT)*obj4_stride1 + idyT*obj4_ld;
size_t K_size_t = K;
for(size_t block_k=0; block_k < K_size_t; block_k+=8){
__local double* plA = lA + idxT*33 + idyT;
__local double* plB = lB + idyT*33 + 1*idxT;
barrier(CLK_LOCAL_MEM_FENCE);
(plA + 0)[0] = in_bounds_m_local[0]?obj1_pointer[0*obj1_ld +
0obj1_stride1]:0; (plA + 8)[0] = in_bounds_m_local[1]?obj1_pointer[8obj1_ld + 0obj1_stride1]:0; (plA + 16)[0] = in_bounds_m_local[2]?obj1_pointer[16obj1_ld + 0obj1_stride1]:0; (plA + 24)[0] = in_bounds_m_local[3]?obj1_pointer[24obj1_ld + 0obj1_stride1]:0; (plB + 0)[0] = in_bounds_n_local[0]?obj4_pointer[0obj4_ld + 0obj4_stride1]:0; (plB + 8)[0] = in_bounds_n_local[1]?obj4_pointer[0obj4_ld + 8obj4_stride1]:0; (plB + 16)[0] = in_bounds_n_local[2]?obj4_pointer[0obj4_ld + 16obj4_stride1]:0; (plB + 24)[0] = in_bounds_n_local[3]?obj4_pointer[0obj4_ld + 24obj4_stride1]:0; barrier(CLK_LOCAL_MEM_FENCE); size_t offA = 1idx; size_t offB = 1idy; for(size_t k = 0; k < 8 && (block_k + k < K_size_t); k+=1){ #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t mm = 0; mm < 4; mm++) { rA[kk][mm1+0] = lA[offA + mm8+0+ kk33]; } #pragma unroll 1 for(size_t kk = 0; kk < 1; kk++) #pragma unroll 4 for(size_t nn = 0; nn < 4; nn++) { rB[kk][nn1+0] = lB[offB + nn8+0+ kk33]; } offA += 33; offB += 33; #pragma unroll 1 for(size_t kk = 0; kk <1; ++kk) { rC[0][0]=fma(rA[kk][0],rB[kk][0],rC[0][0]); rC[1][0]=fma(rA[kk][1],rB[kk][0],rC[1][0]); rC[2][0]=fma(rA[kk][2],rB[kk][0],rC[2][0]); rC[3][0]=fma(rA[kk][3],rB[kk][0],rC[3][0]); rC[0][1]=fma(rA[kk][0],rB[kk][1],rC[0][1]); rC[1][1]=fma(rA[kk][1],rB[kk][1],rC[1][1]); rC[2][1]=fma(rA[kk][2],rB[kk][1],rC[2][1]); rC[3][1]=fma(rA[kk][3],rB[kk][1],rC[3][1]); rC[0][2]=fma(rA[kk][0],rB[kk][2],rC[0][2]); rC[1][2]=fma(rA[kk][1],rB[kk][2],rC[1][2]); rC[2][2]=fma(rA[kk][2],rB[kk][2],rC[2][2]); rC[3][2]=fma(rA[kk][3],rB[kk][2],rC[3][2]); rC[0][3]=fma(rA[kk][0],rB[kk][3],rC[0][3]); rC[1][3]=fma(rA[kk][1],rB[kk][3],rC[1][3]); rC[2][3]=fma(rA[kk][2],rB[kk][3],rC[2][3]); rC[3][3]=fma(rA[kk][3],rB[kk][3],rC[3][3]); } } obj1_pointer += 8obj1_stride1; obj4_pointer += 8obj4_ld; } obj0_pointer += gidx32obj0_ld; obj0_pointer += idx1obj0_ld; obj0_pointer += gidy32obj0_stride2; obj0_pointer += idy1obj0_stride2; if (in_bounds_m[0] && in_bounds_n[0]) obj0_pointer[0obj0_ld] = rC[0][0]obj6+ obj0_pointer[0obj0_ld]obj7; if (in_bounds_m[1] && in_bounds_n[0]) obj0_pointer[8obj0_ld] = rC[1][0]obj6+ obj0_pointer[8obj0_ld]obj7; if (in_bounds_m[2] && in_bounds_n[0]) obj0_pointer[16obj0_ld] = rC[2][0]obj6+ obj0_pointer[16obj0_ld]obj7; if (in_bounds_m[3] && in_bounds_n[0]) obj0_pointer[24obj0_ld] = rC[3][0]obj6+ obj0_pointer[24obj0_ld]obj7; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[1]) obj0_pointer[0obj0_ld] = rC[0][1]obj6+ obj0_pointer[0obj0_ld]obj7; if (in_bounds_m[1] && in_bounds_n[1]) obj0_pointer[8obj0_ld] = rC[1][1]obj6+ obj0_pointer[8obj0_ld]obj7; if (in_bounds_m[2] && in_bounds_n[1]) obj0_pointer[16obj0_ld] = rC[2][1]obj6+ obj0_pointer[16obj0_ld]obj7; if (in_bounds_m[3] && in_bounds_n[1]) obj0_pointer[24obj0_ld] = rC[3][1]obj6+ obj0_pointer[24obj0_ld]obj7; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[2]) obj0_pointer[0obj0_ld] = rC[0][2]obj6+ obj0_pointer[0obj0_ld]obj7; if (in_bounds_m[1] && in_bounds_n[2]) obj0_pointer[8obj0_ld] = rC[1][2]obj6+ obj0_pointer[8obj0_ld]obj7; if (in_bounds_m[2] && in_bounds_n[2]) obj0_pointer[16obj0_ld] = rC[2][2]obj6+ obj0_pointer[16obj0_ld]obj7; if (in_bounds_m[3] && in_bounds_n[2]) obj0_pointer[24obj0_ld] = rC[3][2]obj6+ obj0_pointer[24obj0_ld]obj7; obj0_pointer += 8obj0_stride2; if (in_bounds_m[0] && in_bounds_n[3]) obj0_pointer[0*obj0_ld] = rC[0][3]obj6+ obj0_pointer[0obj0_ld]obj7; if (in_bounds_m[1] && in_bounds_n[3]) obj0_pointer[8obj0_ld] = rC[1][3]obj6+ obj0_pointer[8obj0_ld]obj7; if (in_bounds_m[2] && in_bounds_n[3]) obj0_pointer[16obj0_ld] = rC[2][3]obj6+ obj0_pointer[16obj0_ld]obj7; if (in_bounds_m[3] && in_bounds_n[3]) obj0_pointer[24obj0_ld] = rC[3][3]obj6+ obj0_pointer[24obj0_ld]obj7; obj0_pointer += 8obj0_stride2; }
MJ
MJ
On Thu, Mar 15, 2018 at 7:47 PM, Charles Determan [email protected] wrote:
@mjaniec2013 https://github.com/mjaniec2013 thank you, that helps. It looks like the memory is approximately doubling. As the internal matrix sizes would be 5120x5120. The math comes out for 3 matrices at double precision to 35120512082 ~= 1.2GB. I have just made another commit to develop that I think should help. Please try the latest code at let me know if anything has improved.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373483897, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlpBerWDEy66BJEX60Sq16ZR2xINHks5terdagaJpZM4QNTQn .
@mjaniec2013 that is strange, does it work with smaller matrices? It just passed all my unit tests on Travis and I just did a matrix multiplication locally on my machine although it is just an Intel GPU.
Yes it work with smaller matrices:
library(gpuR)Number of platforms: 1
- platform: NVIDIA Corporation: OpenCL 1.2 CUDA 9.1.84
-
context device index: 0
- GeForce GTX 1050 Ti checked all devices completed initializationgpuR 2.0.2 Attaching package: ‘gpuR’ The following objects are masked from ‘package:base’:
colnames, pmax, pmin, svd
-
n <- 4000 t0 <- Sys.time()
A <- matrix( rnorm(n^2), nrow=n ) B <- matrix( rnorm(n^2), nrow=n )
t_rnorm <- Sys.time()-t0 t0 <- Sys.time()
vclA = vclMatrix(A, type="double") vclB = vclMatrix(B, type="double") vclC = vclA %*% vclB t_gpu <- Sys.time()-t0
format(object.size(A), units = "MB") [1] "122.1 Mb"
cbind( t_rnorm, t_gpu ) t_rnorm t_gpu [1,] 3.151196 1.106757
MJ
@mjaniec2013 does the memory allocation on the GPU look more accurate as well with those 4K matrices? I'm really not sure about the 5K matrix at the moment.
More or less, is fine. Growth from ~880 to ~1315MB -> 144 Mb per matrix, if I am correct.
MJ
MJ
On Thu, Mar 15, 2018 at 8:58 PM, Charles Determan [email protected] wrote:
@mjaniec2013 https://github.com/mjaniec2013 does the memory allocation on the GPU look more accurate as well with those 4K matrices? I'm really not sure about the 5K matrix at the moment.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373503780, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprljhuad9tkzRLa277sJCdR-wDO-E7ks5tesfagaJpZM4QNTQn .
Thanks @mjaniec2013, do you have what the growth was prior to the change? You could try installing the master branch and running the same code to see. This would be a good confirmation of the most recent changes.
Before I will test with master branch again, let me show you results of another test I've just performed.
I run matrix multiplication in a for loop, without gc():
for (i in 1:100) {
cat("\r",i)
vclA = vclMatrix(A, type="double") vclB = vclMatrix(B, type="double")
vclC = vclA %*% vclB
} cat("\n")
When i reached 19, error was generated:
19ViennaCL: FATAL ERROR: Kernel start failed for 'assign_cpu'.ViennaCL: Smaller work sizes could not solve the problem. Error in cpp_sexp_mat_to_vclMatrix(data, 8L, context_index - 1) : ViennaCL: FATAL ERROR: CL_MEM_OBJECT_ALLOCATION_FAILURE ViennaCL could not allocate memory on the device. Most likely the device simply ran out of memory. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance!
Meanwhile monitoring showed:
This was the second run of the loop test. Before, memory usage hit 4GB.
MJ
MJ
On Fri, Mar 16, 2018 at 2:45 PM, Charles Determan [email protected] wrote:
Thanks @mjaniec2013 https://github.com/mjaniec2013, do you have what the growth was prior to the change? You could try installing the master branch and running the same code to see. This would be a good confirmation of the most recent changes.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373717393, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlusLklbs6mq7xtLoA6qWNfNfi3KLks5te8HxgaJpZM4QNTQn .
Matrix size was 4k*4k.
MJ
MJ
On Sun, Mar 18, 2018 at 8:43 AM, Maciej Janiec [email protected] wrote:
Before I will test with master branch again, let me show you results of another test I've just performed.
I run matrix multiplication in a for loop, without gc():
for (i in 1:100) {
cat("\r",i)
vclA = vclMatrix(A, type="double") vclB = vclMatrix(B, type="double")
vclC = vclA %*% vclB
} cat("\n")
When i reached 19, error was generated:
19ViennaCL: FATAL ERROR: Kernel start failed for 'assign_cpu'.ViennaCL: Smaller work sizes could not solve the problem. Error in cpp_sexp_mat_to_vclMatrix(data, 8L, context_index - 1) : ViennaCL: FATAL ERROR: CL_MEM_OBJECT_ALLOCATION_FAILURE ViennaCL could not allocate memory on the device. Most likely the device simply ran out of memory. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance!
Meanwhile monitoring showed:
This was the second run of the loop test. Before, memory usage hit 4GB.
MJ
MJ
On Fri, Mar 16, 2018 at 2:45 PM, Charles Determan < [email protected]> wrote:
Thanks @mjaniec2013 https://github.com/mjaniec2013, do you have what the growth was prior to the change? You could try installing the master branch and running the same code to see. This would be a good confirmation of the most recent changes.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373717393, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlusLklbs6mq7xtLoA6qWNfNfi3KLks5te8HxgaJpZM4QNTQn .
When using TensorFlow, GPU memory also gets filled quickly. rm and gc do not free video memory. Only quitting Rstudio works. Nevertheless, the memory does not "overfill" and no errors are generated.
MJ
MJ
On Sun, Mar 18, 2018 at 8:45 AM, Maciej Janiec [email protected] wrote:
Matrix size was 4k*4k.
MJ
MJ
On Sun, Mar 18, 2018 at 8:43 AM, Maciej Janiec [email protected] wrote:
Before I will test with master branch again, let me show you results of another test I've just performed.
I run matrix multiplication in a for loop, without gc():
for (i in 1:100) {
cat("\r",i)
vclA = vclMatrix(A, type="double") vclB = vclMatrix(B, type="double")
vclC = vclA %*% vclB
} cat("\n")
When i reached 19, error was generated:
19ViennaCL: FATAL ERROR: Kernel start failed for 'assign_cpu'.ViennaCL: Smaller work sizes could not solve the problem. Error in cpp_sexp_mat_to_vclMatrix(data, 8L, context_index - 1) : ViennaCL: FATAL ERROR: CL_MEM_OBJECT_ALLOCATION_FAILURE ViennaCL could not allocate memory on the device. Most likely the device simply ran out of memory. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance!
Meanwhile monitoring showed:
This was the second run of the loop test. Before, memory usage hit 4GB.
MJ
MJ
On Fri, Mar 16, 2018 at 2:45 PM, Charles Determan < [email protected]> wrote:
Thanks @mjaniec2013 https://github.com/mjaniec2013, do you have what the growth was prior to the change? You could try installing the master branch and running the same code to see. This would be a good confirmation of the most recent changes.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-373717393, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlusLklbs6mq7xtLoA6qWNfNfi3KLks5te8HxgaJpZM4QNTQn .
@mjaniec2013 I don't know if you were trying to include images or additional things but since you replied via email they didn't come through. I cannot see what you were trying to show after Meanwhile monitoring showed: comment.
Regarding Tensorflow, I heard somewhere the it uses all the GPU memory by default and releasing the memory is only done after you end the session (in this case Rstudio). I cannot confirm it but your note isn't a huge surprise to me with Tensorflow.
Saved a picuture copy of the mail as: https://cl.ly/0B1t3P1P2a2p
As you can see, gpuR crashes after 19 iterations of small (n=1000) matrix multiplication without gc()
I've been testing TF over recent days. In general there are no problems with memory management here.
However, since TF in R is actually just an interface to Python version, other issues arrise. Seems, at this moment using TF (and Keras) is more stable in Python.
MJ
MJ
On Wed, Mar 21, 2018 at 6:47 PM, Charles Determan [email protected] wrote:
@mjaniec2013 https://github.com/mjaniec2013 I don't know if you were trying to include images or additional things but since you replied via email they didn't come through. I cannot see what you were trying to show after Meanwhile monitoring showed: comment.
Regarding Tensorflow, I heard somewhere the it uses all the GPU memory by default and releasing the memory is only done after you end the session (in this case Rstudio). I cannot confirm it but your note isn't a huge surprise to me with Tensorflow.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/cdeterman/gpuR/issues/100#issuecomment-375035275, or mute the thread https://github.com/notifications/unsubscribe-auth/AFprlpjualRrXND9lZAb8Hx8W9Ypze_-ks5tgpIjgaJpZM4QNTQn .
Hi, i just hit the same problem, im using gpuR 2.0.0 because in not figured out yet how to install development versions. On my over kill GTX 1080 Ti with 11GB of memory i can multiply 8K matrix (488.3 MB), which consumes 1,091 MB of video memory. 9K matrix end with error.
package
Loading required package: gpuR Number of platforms: 1
- platform: NVIDIA Corporation: OpenCL 1.2 CUDA 9.1.84
- context device index: 0
- GeForce GTX 1080 Ti checked all devices completed initialization gpuR 2.0.0
- context device index: 0
code
nr<-8000
x<-matrix(rnorm(nr*nr,0,1),nrow=nr,ncol=nr)
vclX = gpuR::vclMatrix(x, type="float") #push matrix to GPU
time3<-system.time({
mm3<-vclX %*% vclX
})
eror
ViennaCL: FATAL ERROR: Kernel start failed for 'assign_cpu'. ViennaCL: Smaller work sizes could not solve the problem. Error in cpp_zero_vclMatrix(nrow, ncol, 6L, context_index - 1) : ViennaCL: FATAL ERROR: CL_MEM_OBJECT_ALLOCATION_FAILURE ViennaCL could not allocate memory on the device. Most likely the device simply ran out of memory. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance! Timing stopped at: 0.03 0 0.03
@aplikaplik strange with that much available device memory. Regarding the develop version have you tried using devtools::install_github('cdeterman/gpuR', ref = 'develop')? If you can do that and attempt your matrix multiplication again it would be helpful.
@cdeterman ok, i install the develop version, thanks for that. But i still see the error. On atached image, you can see memory usage for four tests, 8K, 9K, 10K, 20K (3Gb) matrix. I m definitely not expert in programming, but its looks more like some variable overflow rather that memory issue. Also is strange that after code execute, data remain in graphic memory, even in 8K matrix case. If you send me some code for test, i can run it ans send you back results. also i m using win 10 64bit, graphic driver 391.35 and i tested Ropen 3.4.3 an R 3.4.4. on Rstudio Version 1.1.423. Its the same error.
package
** testing if installed package can be loaded Number of platforms: 1
- platform: NVIDIA Corporation: OpenCL 1.2 CUDA 9.1.84
- context device index: 0
- GeForce GTX 1080 Ti checked all devices completed initialization
- context device index: 0
- DONE (gpuR) In R CMD INSTALL Reloading installed gpuR Number of platforms: 1
- platform: NVIDIA Corporation: OpenCL 1.2 CUDA 9.1.84
- context device index: 0
- GeForce GTX 1080 Ti checked all devices completed initialization gpuR 2.0.2
- context device index: 0
memory usage
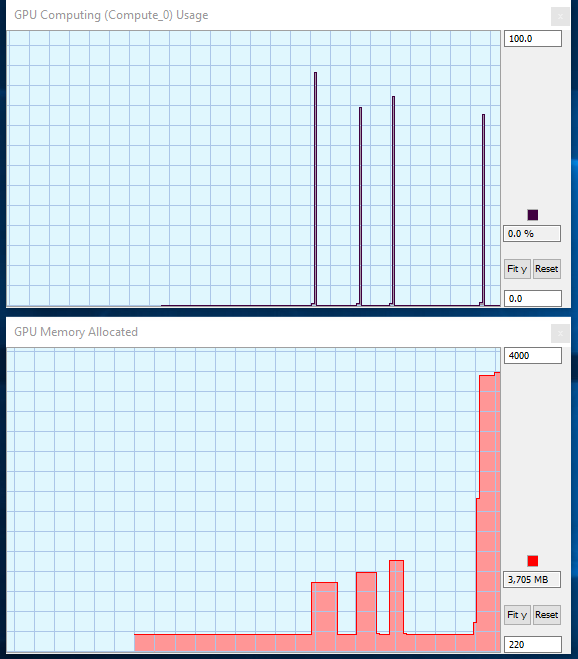
error
Error in cpp_vclMatrix_gemm(A@address, B@address, C@address, 6L) : ViennaCL: FATAL ERROR: CL_INVALID_PROGRAM_EXECUTABLE. If you think that this is a bug in ViennaCL, please report it at [email protected] and supply at least the following information:
- Operating System
- Which OpenCL implementation (AMD, NVIDIA, etc.)
- ViennaCL version Many thanks in advance! Timing stopped at: 0.42 1.79 2.29
code
nr<-8000 #(also 9000, 10000, 20000)
x<-matrix(rnorm(nr*nr,0,1),nrow=nr,ncol=nr)
vclX = gpuR::vclMatrix(x, type="float") #push matrix to GPU
time3<-system.time({
mm3<-vclX %*% vclX
})
Same issue here. I was trying to calculate the inner product of a 10k X 75 matrix and a 75 X 9k matrix, and got the error message about running out of memory.
Number of platforms: 1
- platform: NVIDIA Corporation: OpenCL 1.2 CUDA 9.0.282
- context device index: 0
- Tesla P100-PCIE-16GB
- context device index: 1
- Tesla P100-PCIE-16GB
- context device index: 2
- Tesla P100-PCIE-16GB
- context device index: 3
- Tesla P100-PCIE-16GB checked all devices completed initialization gpuR 2.0.0
- context device index: 0