[bitnami/mariadb-galera] It's so dangerous to delete all users and databases
https://github.com/bitnami/bitnami-docker-mariadb-galera/blob/8c6434100f0796d462d5fb2128418c77bdad0e74/10.5/debian-10/rootfs/opt/bitnami/scripts/libmariadbgalera.sh#L502
Why should we delete all users and databses users created when cluster recovered from non-primary node? I think this is a dangerous way.
Hi @lcfang,
It's for synchrony with all the nodes. This method runs when MySQL is initialized and deletes all users because the node started maybe doesn't have the same information as the rest of the nodes. To avoid problems with synchrony all users are deleted and after the replication user is created so that synchronization can be performed. https://github.com/bitnami/bitnami-docker-mariadb-galera/blob/8c6434100f0796d462d5fb2128418c77bdad0e74/10.5/debian-10/rootfs/opt/bitnami/scripts/libmariadbgalera.sh#L526
I hope I have answered your question,
Ibone.
Hi @Mauraza , Thanks for your reply. I know that is for synchrony, but I think this is a dangerous way, sometimes it may cause a disaster.
I encounter a bad scenario rencently. I use 10.5.4 version image, and install the cluster using helm-chart, the cluster runs well for a few days. one day, I found that there were only 2 pods can be seen, mysql-2 is Running, mysql-0 is CrashBackOff, and mysql-1 is missing, and mysql-0 can't join the cluster with NO-PRIMARY error, I try to recover the cluster by deleting all the pod for restart. the cluster restart and all three pods become Running , but I found that the users and databases I created were all deleted which made me crazy.
I still do not know who delete the mysql dir which cause https://github.com/bitnami/bitnami-docker-mariadb-galera/blob/8c6434100f0796d462d5fb2128418c77bdad0e74/10.5/debian-10/rootfs/opt/bitnami/scripts/libmariadbgalera.sh#L499
which reason will cause mysql dir be deleted?
BTW, I encountered similer scenario frenquently recently where only 2 pods can be seen and one can't join the cluster with NO-PRIMARY error, only deleting all pods can recover the cluster, and the users and databases were not always be deleted.
Is there any good idea for this scenario?
Hi @lcfang,
in that scenario, is the primary mysql node lost and not recovered? This is an architecture primary and secondary, the primary is the true data keeper while a no-primary is a replication of master, if your primary is empty the no-primary will be empty, to avoid this, you need a high availability
In the second scenario, not always work perfectly, but in this architecture, the important is the primary, you always can restart the no-primary without a problem.
Hi @Mauraza ,
in that scenario, is the primary mysql node lost and not recovered?
In this scenario, I think split-brain happened for something wrong which I can not understand.
to avoid this, you need a high availability
Actually, I have three pods in my cluster which I think is a high availability.
But, I always encounter the error like this(ignoring 2 containers in my pod, because I have a metrics monitor):
 or
or
 with log:
with log:
 or
or
 I do not know why
I do not know why mysql-0 can not join mysql-2 to recover the cluster automatically.
In this scenario, I try to recover the cluster by deleting all the pods, then the k8s will restart all the pods one by one, safetobootstrap will be set true for mysql-0 which may trigger users and databases lost or not.
Hi @lcfang,
Did you check this https://github.com/bitnami/charts/tree/master/bitnami/mariadb-galera#bootstraping-a-node-other-than-0, that explains how to get the latest node and how to start from it?
Hi, I would like to share some comments, a let's see if I can shed some light.
You can check if you have an split brain by checking the UUID in the file /bitnami/mariadb/data/grastate.dat. It should be the same in all the nodes. Could you provide the content of this file for the three nodes ?
To check that file, you can get into each node and cat it or use the kubectl command from this section.
Regarding the mysql-0 crashloopback, Could you provide the full log and the helm command and values/set used ? My first impression is that maybe something is not right there.
Why should we delete all users and databases users created when cluster recovered from non-primary node? I think this is a dangerous way.
The logic here is that when you are forcing the bootstraping from a node, it means that the "good" data are the ones in that node, and the remaining nodes have to sync with this node because their data are not valid.
@rafariossaa
I can get the UUID in the file /bitnami/mariadb/data/grastate.dat, but is is not always the same.
I find my mysql-cluster down today

the grastate.dat and gvwstate.dat are:
mysql-0:

 mysql-1:
mysql-1:
 mysql-2:
mysql-2:
 But I got one of the UUID is
But I got one of the UUID is 00000000-0000-0000-0000-000000000000 a few days ago having the same phenomenon.
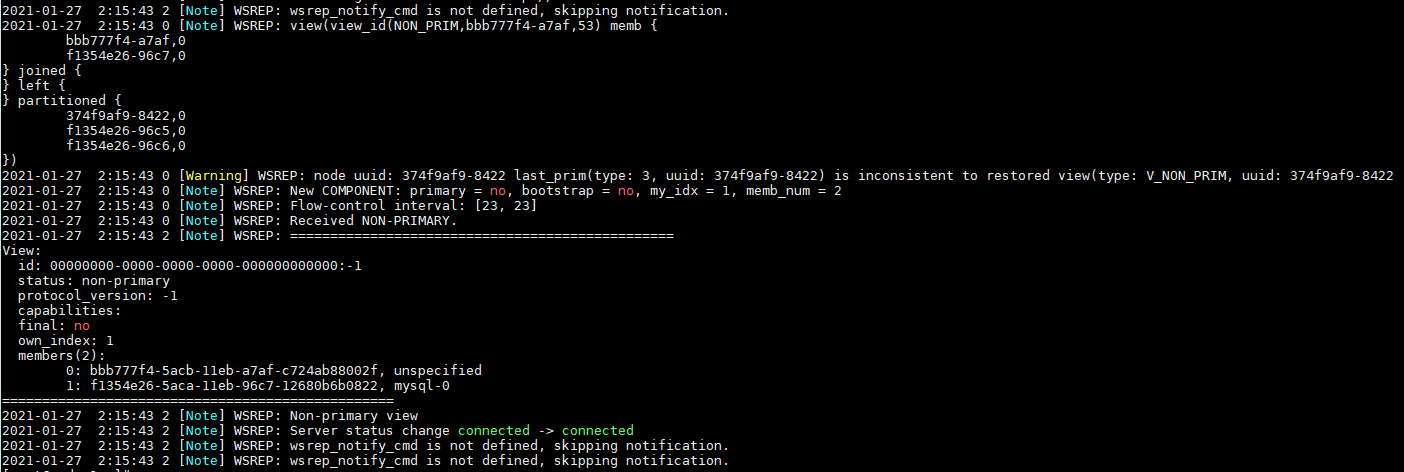
I don't collect the logs today, but the logs of mysql-0 in Jan 27 was:
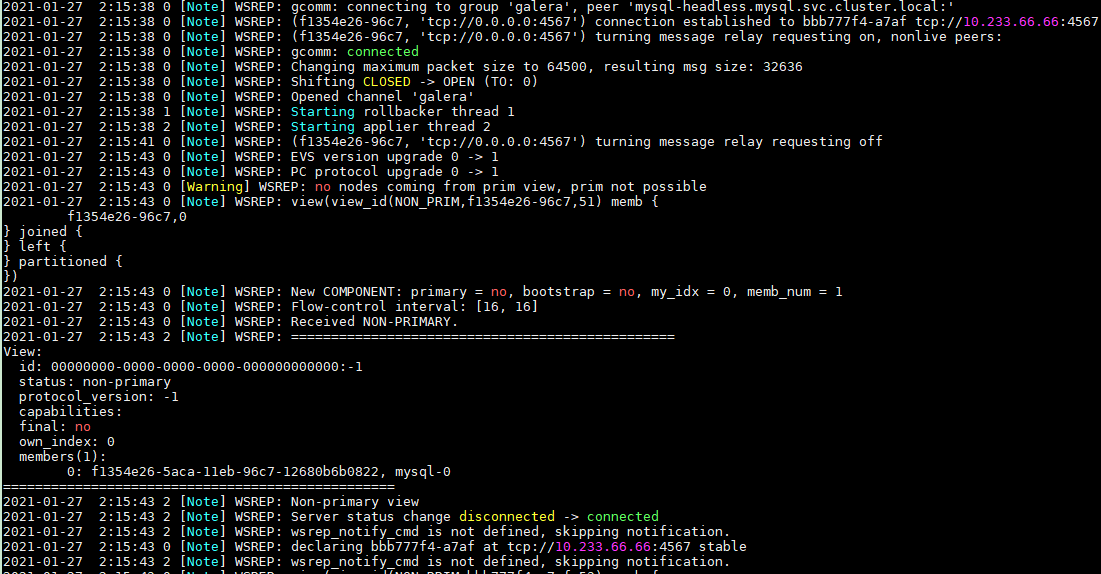
Hi, All the nodes of the same cluster should have the same UUID, if not, they think they are in different clusters and won't sync. To recover you cluster, you can try to scale the cluster to 1 node, then delete the chart deployment. Now that all the nodes are stopped, check the node with the higher seqno, and try to bootstrap the cluster form it. It is a similar procedure than this.
Could you provide which settings or parameters in the values did you use when running helm install ?
Hi @rafariossaa I think I know how to recover this, but I am so sad that I can not understand why this happened so frequently, do you have any idea about the reason? this is my values to install.
Hi, I don't know right now, I guess this is some kind of race condition or an issue when forcing the bootstraping. We have a internal task to review deeper this case. If it happens that you find out the step sequence that lead to this issue, please don't hesitate to let us know.
Hi - I'm not sure if it's related but I woke up this morning to my Docker Swarm container with a wiped out volume. All the data is gone. I was running the galera cluster on just one instance, one node to begin with to evaluate. The server rebooted to install kernel updates, I don't know if it's related.
Hi @patrick-leb If you are going to dig deeper into your issue, please come back and share your findings. Maybe you have more information in the logs (contianer's and docker swarm's ones).
Unfortunately I debugged this the complete wrong way and I ended up scraping the service and the stack. I assumed it was an application error. I don't have logs - and since I don't REALLY need a galera cluster right now, I reverted back to regular MariaDb