Allow `Option<Entity>` to leverage niche optimization
Objective
- Implements change described in #3022
- Goal is to allow Entity to benefit from niche optimization, especially in the case of
Option<Entity> - Ultimately to reduce overhead with certain data structures with empty slots (ie. grids)
Solution
-
Entity::generationwas changed toNonZeroU32, overEntity::idbecause:- It reduces the amount of API breakage, being effectively an implementation detail
- It's, probably, less error-prone than constantly offsetting
Entity::id
-
Entities::metachanged toOption<NonZeroU32>to match-
Noneindicates a slot that has used all generation values and can no longer be reused.
-
-
Entity::from_bitswas modified to return aOption<Entity> - Tests updated (mostly just Entity::generation init with
NonZeroU32::new) - Added tests for
Entity::from_bitswhen the bits are invalid;Option<Entity>niche optimization;Entities::metageneration increment;Entities::metageneration overflow behaviour;
Edit: PS first PR here, be harsh but gentle :sweat_smile:
Edit2: Updated to reflect latest commit
Entities::meta changedtoOption<NonZeroU32>to match -Noneindicates a slot that has used all generation values and can no longer be reused.
Is permanently retiring an id actually behavior that people want? It seems more like it's a consequence of wrapping the generation and not wanting a branch in its increment logic.
Entity::generationwas changed toNonZeroU32, overEntity::idbecause: - It reduces the amount of API breakage, being effectively an implementation detail - It's, probably, less error-prone than constantly offsettingEntity::id
I wouldn't expect people to spawn 4 billion entities 4 billion times each (they might tho), but aside from being less code to change, this part feels arbitrary. I think this PR should argue why retirement is a good idea for everyone, since it would essentially put a hardcoded time-limit on a World, which is strange when things like change ticks wraparound.
(Edit: Also, in the future, it's plausible that Bevy would reduce the number of generation bits to add something else.)
(Edit 2: The current implementation panics if a generation maxes out, so I guess this PR is a net improvement and good as-is, but why not let it wraparound with a warning that stale cached Entity values may have become valid again?)
Oops, just realized that I didn't post my reply, just need to rewrite it - one sec. Sorry if this is a little rambly/overly-specific, bit late here and I like running silly numbers (hopefully I didn't fumble the math at least)
Is permanently retiring an id actually behavior that people want? It seems more like it's a consequence of wrapping the generation and not wanting a branch in its increment logic.
The reason for not wrapping generation IDs is to prevent the entire class of errors caused by aliasing, which range from subtle to significant bugs and are difficult to test for, design around and reproduce. By retiring we trade that class of errors for a single well-defined error case that both already exists (spawn more entities than assignable IDs) and is significantly less likely to occur (both than aliasing and running out of entity IDs alone). This has the additional advantage of potentially allowing us to expose a handler to the developer, if that is something we're interested in (ie. save critical data, shutdown gracefully, perform some operation to free entity IDs).
I wouldn't expect people to spawn 4 billion entities 4 billion times each (they might tho), but aside from being less code to change, this part feels arbitrary. I think this PR should argue why retirement is a good idea for everyone, since it would essentially put a hardcoded time-limit on a World, which is strange when things like change ticks wraparound.
If there is actual demand for destroying and re-creating that many entities over the lifetime of the program, I'd suggest that the first step would be to re-evaluate the approach being taken. Other than standard suggestions like merging entities into groups (ie. a particle system instead of particle entities), I would suggest implementing a pool system. This pool system will better-fit the user's advanced use case as they can then attach (or not attach) any amount of metadata to identify aliasing (ie. a u128 generation), and force the developer to identify which systems care about aliasing. One other solution is sub-apps/sub-worlds, and recreating them if you exhaust IDs, which is a little more transparent and only requires the user to define and facilitate cross-world communication.
I also believe that the chance of encountering this error is so low that any such designs that could, would already need to be designing around limits such as the entity ID address space. Assuming a 4GHz processor incrementing the generation of each entity in-turn, once per tick and performing no other logic/work, it would take 140 years to do. To bring that down to something like a decade, you would need to permanently occupy all but 300k entities (ie. permanently take-up 4 billion, or 93.75% of the address space), at which point you would be much more likely to run out of entity IDs than generations and likely have thus design around it (and it would be a significant burden on system resources, something like 31.8GiB just in Entity ID/Gens alone) - meaning that it wouldn't be unreasonable to also require one to design around a generation limit at that extreme.
Also, in the future, it's plausible that Bevy would reduce the number of generation bits to add something else.
Reducing the number of generation bits could definitely be of concern. Reducing it by even 8 bits in this engineered scenario would only leave us with a little over a half year of uptime. The engineered case is obviously not very useful for doing any work however, and if you're spending 95% of your ticks on actual work, that half year stretches out to just over a decade).
Though as you point out the current implementation panics immediately as soon as generations roll over (though only in debug), and that would occur in just barely over a second (1.07). So on the whole this should be an improvement. Maybe it's something that should be re-visted later when reducing the number of generation bits moves forward? Or is it something worth talking about now? Since this PR effectively allows developers the freedom to chew up generations at a higher rate, and switching back later to be more strict again would break that code and switching to allow wrapping would also break such code
The reason for not wrapping generation IDs is to prevent the entire class of errors caused by aliasing, which range from subtle to significant bugs and are difficult to test for, design around and reproduce.
I also believe that the chance of encountering this error is so low that any such designs that could, would already need to be designing around limits such as the entity ID address space.
You acknowledge that developers who could even encounter this would likely be designing around the limits of the address space already, so it seems a bit overkill to enforce it. If we allow the generation to wraparound, we could just emit a warning when the it resets to 1, e.g. "Dangling references to entity ID {id} may have become valid again."
[A] pool system will better-fit the user's advanced use case as they can then attach (or not attach) any amount of metadata to identify aliasing (ie. a u128 generation), and force the developer to identify which systems care about aliasing.
One other solution is sub-apps/sub-worlds, and recreating them if you exhaust IDs, which is a little more transparent and only requires the user to define and facilitate cross-world communication.
The solutions suggested seem more troublesome than just warning the user about possible aliasing, since they expect the user to have a clear appreciation of aliasing anyway or lean on future work to overcome the inconvenience.
Sub-worlds—or any extension to bevy_ecs that would let users reserve a range of entities—are what I'm mostly concerned about, since they're more likely to be impacted by retirement. Recreating an exhausted World does not sound like a cheap operation, nor does Bevy have a method (or idiom) for doing that.
I think retirement is better than the current debug panic / silent release behavior. (Edit: so yeah, I think we can revisit this after this PR) It's just, given the rarity of apps that approach the limits of a 64-bit ID and our shared assumption that their developers would most likely be careful to avoid dangling entity references anyway, ID retirement seems more like a weirdly targeted obstacle than a general user safeguard.
Other ECS additions we're expecting may also reduce the likelihood of encountering entity aliasing bugs. For example, automatic cleanup of dangling references following despawn is one of the highlights of relations whenever they're brought up in discussion.
You acknowledge that developers who could even encounter this would likely be designing around the limits of the address space already, so it seems a bit overkill to enforce it. If we allow the generation to wraparound, we could just emit a warning when the it resets to 1, e.g. "Dangling references to entity ID {id} may have become valid again."
No, the error I'm talking about in those quotes is exhausting the address space without generation rollover. A bad alias from rollovers is either at least as unlikely as world retirement or orders of magnitude more likely to occur - particularly if we were to reduce the number of bits. Enough that I believe it should be avoided by default. Designing for and debugging aliasing would be a non-insignificant burden on developers since it's such a hard issue to reproduce, and I don't feel like the warning helps in this case because it could have a bad alias on generation 33 and that rollover warning 4+ hours ago in the logs.
The solutions suggested seem more troublesome than just warning the user about possible aliasing, since they expect the user to have a clear appreciation of aliasing anyway or lean on future work to overcome the inconvenience.
I expect them to have a clear appreciation of aliasing in that case, because to encounter that case they would already have had to have designed around other limitations of the entity address space. I do think some kind of graceful shutdown in the case of a panic could be nice though - but that's another design talk for a different part of the engine really.
Sub-worlds—or any extension to bevy_ecs that would let users reserve a range of entities—are what I'm mostly concerned about, since they're more likely to be impacted by retirement.
I definitely agree regarding reserved ranges, that's definitely a huge concern.
I'm just not convinced that making generations rollover by default make sense when you're already manipulating the address space. In that case we could make it opt-in since they're already making active choices regarding the address space, for example we could a mechanism flag a range or subworld as having rollover, and still provide aliasing safety by default.
Recreating an exhausted World does not sound like a cheap operation, nor does Bevy have a method (or idiom) for doing that.
Recreating an exhausted world is definitely an expensive operation. However to need to do something like that you would, with the current amount of bits, need to be doing some kind of multi-decade data science number crunching and providing efficient patterns of such fringe use cases of a game engine seems out of scope to me.
Other ECS additions we're expecting may also reduce the likelihood of encountering entity aliasing bugs. For example, automatic cleanup of dangling references following despawn is one of the highlights of relations whenever they're brought up in discussion.
That's definitely a step towards removing aliasing issues. I do have concerns about that regarding efficient access patterns and storage overhead, primarily in the case of grid or tree structures. But I expect after relations drop there will be plenty of efficient implementations of such structures.
I think retirement is better than the current debug panic / silent release behaviour.
Yeah, that definitely makes me uncomfortable, even though it makes sense it still gives me anxiety just thinking about it. I do wonder if going with panic in both debug/release for now might be the better option, since its more restrictive it might be an easier transition when it later opens it up in other specific ways.
our shared assumption that their developers would most likely be careful to avoid dangling entity references anyway, ID retirement seems more like a weirdly targeted obstacle than a general user safeguard.
The main reason I have concerns about it is because the likelihood of it occurring ranges all the way from as unlikely as retiring a world, to almost certain to occur. Conceivably it can be encountered by developers and players, without any strange access patterns, creating a very difficult situation to debug. Where-as the access patterns required to exhaust a world via retirement is a very fringe use-case, and would require the user to already be making informed design decisions around the entity address space.
However, I can't actually quantify the risk of the average user running into aliasing issues. With 32-bit generations it's either as or more significant than exhausting the address space but probably insignificant for most use cases, but dropping to even 24-bits significantly increases the risk of it occurring and is approaching being almost certain at something extreme like 16-bits. In those cases we would be trading a single entity id for effectively an additional 32/24/16-bits worth of unaliased generations, which is why I generally prefer to make the trade.
That all said, it's just the trade I like to make in my hobby ECSs. I trust that the people working on bevy are much more versed in the design space than I am, as well as on the future direction of Bevy's ECS. So, I'm not against rolling rollover it into this PR if its the general consensus - or we could be more conservative and enforce panic at both debug and runtime - or as you say continue with the PR as-is.
PS. Hope I'm not coming off as rude, definitely none of this is meant with any kind of bad tone.
Given that this is motivated by "optimization", have we done any tests or measurements to show that we successfully optimized something? What have we "won" here?
Hmmm I guess this is pretty reasonable proof:
#[test]
fn entity_option_size_optimized() {
assert_eq!(
core::mem::size_of::<Option<Entity>>(),
core::mem::size_of::<Entity>()
);
}
I agree that "retirement" is an extremely reasonable approach for now, especially given that the current "spawn and despawn a lot of entities frequently" behavior will put a lot of load on lower entity ids (because we favor reuse over extending into higher ids). This way, we can "keep going" after greedily exhausting the lower ids. Very, very nice!
I also appear to experience some regressions, see attached: https://gist.github.com/notverymoe/9b11f94ab76bccee69ff44fde3551442
But with world_query_iter/50000_entities_table, if I'm reading it right, is faster than main by 15-22%:
Benchmarking world_query_iter/50000_entities_table
Benchmarking world_query_iter/50000_entities_table: Warming up for 500.00 ms
Benchmarking world_query_iter/50000_entities_table: Collecting 100 samples in estimated 4.1968 s (106k iterations)
Benchmarking world_query_iter/50000_entities_table: Analyzing
world_query_iter/50000_entities_table
time: [38.267 us 39.290 us 40.300 us]
change: [-22.294% -19.576% -16.936%] (p = 0.00 < 0.05)
Performance has improved.
Though, world_query_get/50000_entities_table & world_get/50000_entities_table appears to have regressed by a similar amount:
Benchmarking world_get/50000_entities_table
Benchmarking world_get/50000_entities_table: Warming up for 500.00 ms
Benchmarking world_get/50000_entities_table: Collecting 100 samples in estimated 6.0048 s (10k iterations)
Benchmarking world_get/50000_entities_table: Analyzing
world_get/50000_entities_table
time: [665.63 us 684.25 us 700.73 us]
change: [+18.658% +21.273% +24.270%] (p = 0.00 < 0.05)
Performance has regressed.
...
Benchmarking world_query_get/50000_entities_table
Benchmarking world_query_get/50000_entities_table: Warming up for 500.00 ms
Benchmarking world_query_get/50000_entities_table: Collecting 100 samples in estimated 5.6335 s (10k iterations)
Benchmarking world_query_get/50000_entities_table: Analyzing
world_query_get/50000_entities_table
time: [531.75 us 545.30 us 559.13 us]
change: [+15.406% +18.433% +21.994%] (p = 0.00 < 0.05)
Performance has regressed.
busy_systems/01x_entities_12_systems & empty_systems/001_systems appears to have regressed 20-30%, and busy_systems/01x_entities_03_systems & empty_systems/010_systems improved by slightly less.
Will have a better look into things when I make it home from work (~3-4 hours), and also re-run on the home machine.
Just got home and ran the tests again: https://gist.github.com/notverymoe/2e7379dc9fe44e38a53064195cddada4
Notable regressions (>15%):
-
for_each_par_iter/threads/4~45% -
busy_systems/02x_entities_12_systems~25% -
busy_systems/02x_entities_15_systems~18% -
busy_systems/03x_entities_12_systems~33% -
busy_systems/04x_entities_06_systems~42% -
busy_systems/04x_entities_12_systems~32% -
busy_systems/04x_entities_15_systems~18% -
busy_systems/05x_entities_12_systems~25%
Notable improvements (>15%):
-
sized_commands_0_bytes/4000_commands~20% -
sized_commands_12_bytes/4000_commands~26% -
for_each_par_iter/threads/1~57% -
empty_systems/000_systems~48% -
empty_systems/005_systems~20% -
busy_systems/03x_entities_03_systems~30% -
busy_systems/03x_entities_06_systems~25% -
busy_systems/03x_entities_09_systems~16% -
busy_systems/02x_entities_03_systems~30% -
busy_systems/02x_entities_06_systems~29% -
busy_systems/05x_entities_03_systems~30%
Most of the world_get/world_query/world_entity/etc. have not changed <~1%, and those that do seem to be in the range of 4-6% regressions. world_query_iter/50000_entities_table in particular has a 0.25% regression on my home system.
Bunch of weird variances in the busy_system stuff, not sure if that's normal/expected? Maybe I have something funky with my setups? Home running Arch, latest stable rust, 16GiB, AMD Ryzen 7 3700X 8-Core (16 thread). Work running Ubuntu 18.04, latest stable rust, 32GiB ram, I'll check CPU when I'm in tomorrow and update this. I'll also give this a test on Windows sometime tomorrow. Neither were run with any applications going, other than i3 related things.
Unfortunately I probably won't get a chance to properly look into this tonight unfortunately, or tomorrow night. I'll try for Thursday and Saturday GMT-8 to look more into it. I would expect some minor slowdown, but surely not 30%.... Hmmm...
Yeah I do think some of these tests are flaky. I really wish we had my tests from #2062, which are generally much stabler + were very useful when I was implementing Bevy ECS V2. But that got reverted because they iterate on ecs_bench_suite, which doesn't have clear licensing.
I'll give those a run and see what they say.
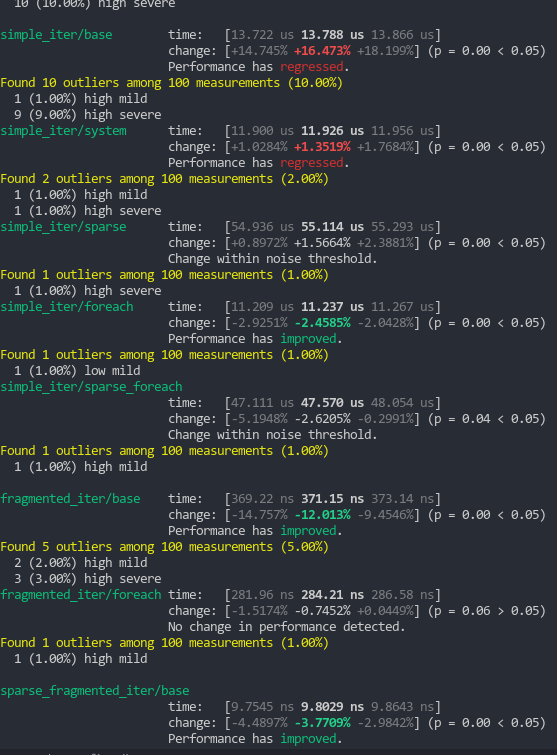
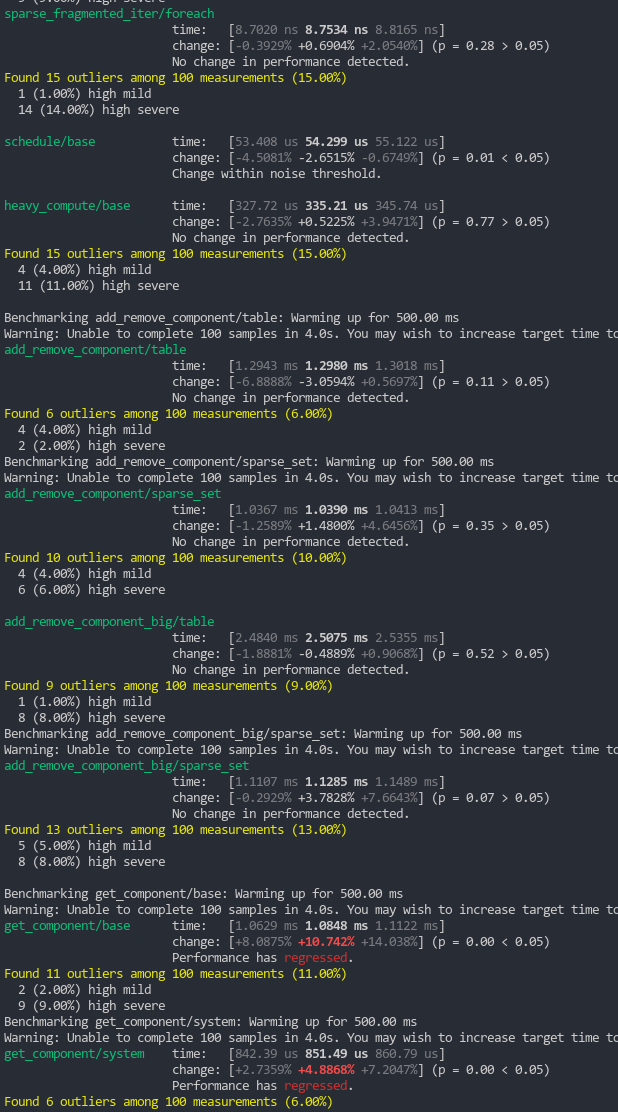
I'm seeing (repeatable) notable regressions in:
- simple_iter/base (~16%), which is in-line with the table iterator regression
- get_component/base (~10%), which does make sense, given that we've added complexity to entity location lookups.
And a repeatable notable improvements in frag_iter/base (~12%).
"fragmented iteration" performance is generally more important than "unfragmented iteration", so the tradeoff seems welcome. And notably, we aren't seeing a significant reduction in system iterator impls.
get_component regressions are understandable, but unfortunate.
I suspect that some of these benches would benefit from black_box.
To me this doesn't feel clear cut. I'm guessing that the get_component regression stems from the "retirement" code (due to extra branching) and not the "niching" code. If it does come from "niching", idk if the Option<Entity> memory size ~~gains~~ wins are worth it. get_component (which is actually a poorly named Query::get benchmark) is a very common api and should be finely tuned to perfection. We are "fast" when compared to other rust archetypal ecs-es, but we are "slow" when compared to direct vec indexing ... this is an interesting related conversation.
If the regression does come from "retirement" ... we might just want to pay that price. That behavior is much better than our current approach.
Currently working through this. I merged in https://github.com/bevyengine/bevy/pull/4332 to get those tests back in, and I'm getting a consistent "change within noise thresholds" or, occasionally, a marginal 1.5% improvement for get_component on stable. On nightly I'm getting some very inconsistent runs, ranging from a 2% to 10% regression for get_component/base and up to between ~10% regression or 2% improvement on get_component/system. (Edit: That's with a nightly run on main, and this branch)
Looking into it on godbolt, the regression would make sense. It seems to output more assembly in the Option<NonZeroU32> version for the comparison, which I'd often see people talk about as "free" on various forums - not certain what's up there. Am pleasantly surprised that there's no heavy regression on spawn/destroy performance, which is where I was anticipating it. (Edit: By using transmute I can get them to be the same assembly, though there's no layout guarantees on Option<NonZero> types, so it's not technically portable. For example, iirc rust-gpu (rust -> spir-v) currently doesn't do niche optimization and just outputs a companion u32 in the option [ouch])
By changing the EntityMeta structure to use raw u32s I can, almost, revert the logic in the Entities::get except it needs to convert the NonZeroU32 to a plain u32, which should be 'free' (std::mem::transmute doesn't improve times at the very least). This doesn't seem to offer any improvement on times however. Strangely, on nightly, I get an additional ~10% regression on the u32 meta versus the NonZeroU32 meta version 0 - likely just a weird blip?
Changing it this PR to alter Entity::id might have a lower performance impact, since we'd only be performing a bit-negation or a single subtract we know won't overflow (or we can just have an unusable 0th entry in the array and pay nothing). However we would be paying that cost on basically every operation involving entities and it wouldn't provide any changes in the generation overflow behaviour that appears to be desired.
Removing from the milestone, this is nice, but shouldn't block a release.
@notverymoe any chance you want to resolve merge conflicts on this and get it up to speed? If so I'll remove the Adopt-Me label and wrangle some final reviews.
Happy to give this an update, might take me a few days though, first day back at work - might be a little hectic.
Just updated this, the merge was a bit ugly to try and resolve so i just recreated the PR line by line.
The hierarchy system required some reworking since it made use of placeholders, I'm not sure my solution is ideal.
I'm not sure what to do about the failed github check, it seems to have failed to clone the repo
Yep I'm rerunning CI for you :) In the future, just ping me or another maintainer and we can do that.
I'd like to see some fresh benchmarks, because this adds branches in numerous key entity-related functions.
The removal of
PLACEHOLDERand the introduction ofParent::try_getis also generally bad UX IMO.
Definitely agree on both those last points, I wasn't entirely certain what the preferred solution there was. I hope to get some fixes for this up by the weekend
I want to also propose an alternative implementation here that might avoid the branches in Entities: use NonZeroU32 for the index not the generation. We can resolve this by padding the Entities internal Vec with an unused EntityMeta, which would require fewer branches and unwraps, and would not incur any cost when indexing into Entities. We lose our on entity zero, but we literally have 2^32 - 2 others, which is probably a worthwhile tradeoff.
For the purposes of the issue being address, niche-optimization, absolutely and I'd be keen to go forward with it since it'll likely be more performant than previous tests for the generation indicate - I hadn't thought about just blacklisting an entity slot to avoid offsetting, very smart. However, we do lose out on having consistent behavior for generation overflows - currently in development exhausting a generation will cause a panic, whilst in production it'll silently overflow.
I mean, generation overflow behavior might be better addressed with a proposal since subworlds complicate this quite a bit.
Hey there, I haven't forgot about this, I just kept remembering when I was busy and forgot again by the time I was free :sweat_smile: Haven't got those fixes up for the branch, but I wrote up the reserved-id branch a little while ago, and missed posting about it: https://github.com/nvm-contrib/bevy/tree/niche-optimization-for-entity-via-id
I tried running the benches at the time, but I got similar inconsistent results like mentioned earlier in this issue. If I get a chance I'll give the benches another go soon.
Bumping to 0.12 milestone: feel free to remake this PR if you think that will be easier than fixing merge conflicts!
Starting a conversation on discord, because honestly I need to know what direction I should be pushing this.
Link here: https://discord.com/channels/691052431525675048/1154573759752183808/1154573764240093224
First pass attempt v2 at Entity::index nicheing. Still some quirks and questions: https://github.com/nvm-contrib/bevy/pull/1/files
If we decide in the discord discussion that index is the go-forward, I'll close this PR and open one for the index version on here
I'll have an update for the Generation version of this change sometime this weekend. Some notes/changes I'll be looking to add into here, after having talked with Joy/Joy2 on discord:
- Generation -> NonZeroU32
- We can make flags and relationships work with it
- We can mitigate performance regressions for iteration/get by removing Option from the entity meta, at the cost of a slightly more expensive free operation.
- Wrap generation for now, and table for discussion, since it'll be less problematic to swap from wrapping to not-wrapping than the other way around.
- There are plenty of generations to go around
- Already planned work will address theoretical subworld id sync concerns
Give the scope of the changes, and the current conflicts. It might be better to open a new PR. Unsure.