lac
 lac copied to clipboard
lac copied to clipboard
百度NLP:分词,词性标注,命名实体识别,词重要性

python 版本  c++ 版本  经过比较,两个模型的版本相同的
想用cuda加速分词,但是发现分出来的结果不对。 input:`他是一名算法工程师。` output:`{ "msg": "", "results": [ { "tag": [ "a", "a", "a", "a", "a", "a", "a", ], "word": [ "他", "是", "优秀", "的", "算法", "工程师", "。" ] } ],...
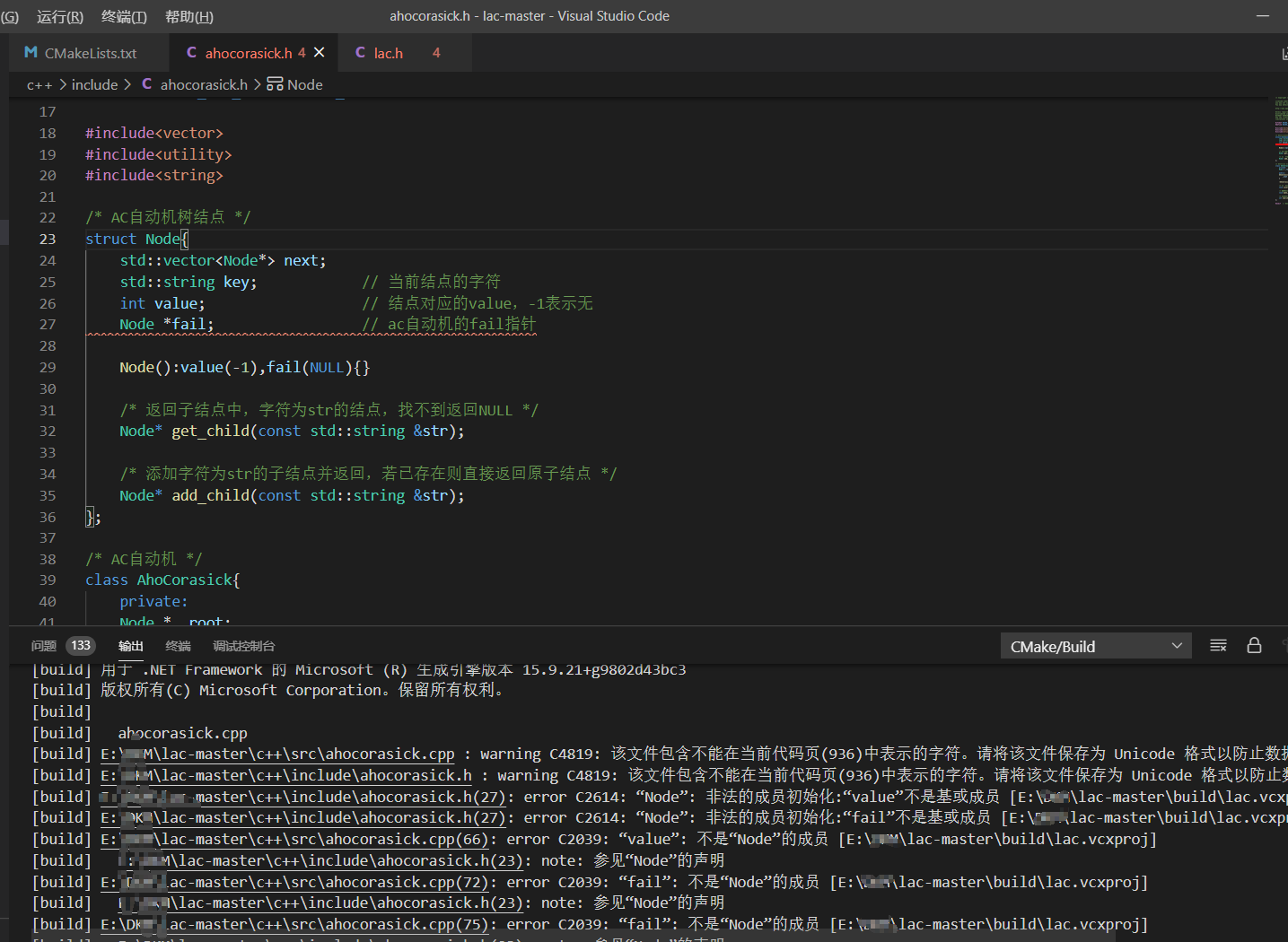
PaddlePaddle 2.x以后的版本没有办法进行增量训练吗?训练时候会出现下面的报错: `AssertionError: In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and 'data()' is only supported in static graph mode. So if you want to use this...
case示例: ``` from LAC import LAC l = LAC(mode='seg') l.add_word("广东省/n") l.add_word("人/n") l.add_word("民/n") l.add_word("人民/n") l.add_word("民政/n") l.add_word("政府/n") ``` ``` l.run("人民政府") ['人', '民', '政府'] ``` 期望得到 ['人民', '政府'] 我观察在源码 `parse_customization` 中仅根据前缀树来修正,有办法引入概率或者其他方式来解决优化吗?