[BanyanDB] Support Asynchronous IO and Direct IO
Search before asking
- [X] I had searched in the issues and found no similar feature requirement.
Description
Background
Currently, Banyandb only supports synchronous IO, which is important for a database system that focuses on writing but not reading. So I hope to provide a faster IO model to reduce latency.
Why Direct IO
For the database system, we have created a layer of cache ourselves, and the operating system's cache once again is undoubtedly redundant, which will reduce the performance of BanyanDB. Therefore, using direct io to bypass Linux's cache.
Why Asynchronous IO
Asynchronous IO is undoubtedly an important way to reduce IO latency. Linux version 5.1 supports iouring, and I hope to achieve better performance by supporting io_uring in BanyanDB.
Benchmark
To demonstrate the superiority of Ioring performance, I used GO's benchmark framework to conduct comparative tests on synchronous IO and Ioring, and the results are as follows:

From the above figure, we can see that the latency of io_uring is indeed much lower than that of blocking io, but the overall memory usage and allocation times will be higher, but it does not greatly affect the operation of the entire system.
Using io_uring
Linux provides io_ uring-related system calls to be available for developers to use, but if using system calls directly, the development efficiency will be relatively low. Therefore, I conducted research on some related third-party libraries and ultimately decided to use https://github.com/iceber/iouring-go.The reasons are as follows:
- The API is simple and easy to use,it can be used with relatively little code.
- Implemented most of the basic functions of Iouring,such as register a file set for io_uring instance,set timer,add request extra info, could get it from the result and so on.
- More importantly, the library also encapsulates some performance optimization aspects, such as registering file sets, registering cache, and poll that replaces interrupt.
BanyanDB Optimization Combined With io_uring
Write-ahead Logging
WAL currently in BanyanDB adopts an asynchronous method for disk flushing. The specific process as follows:
- Write the data to the buffer firstly.
- then perform a batch processing on the data in memory, and perform an asynchronous callback of the disk flushing result to the upper layer.
The writing model is very similar with io_uring,so we can perform a smooth migration.Also looking forward to improving performance.
Log Structured Merge Tree
Sometimes it is necessary to query scenarios with multiple keys, perhaps combined with GO's coroutines and io_ uring can achieve performance improvement.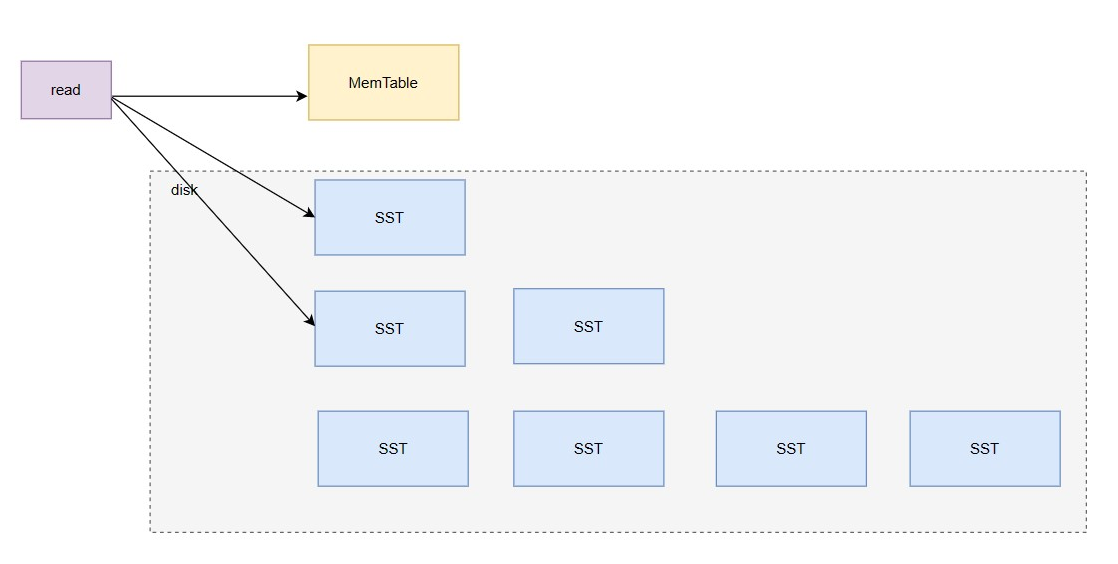
Compaction is a crucial module in LSM-Tree based systems. It optimizes read performance and space issues by continuously recycling old versions of data and merging multiple layers into one through periodic backend tasks. However, during the operation of the compression task, it incurs significant resource overhead. Compression/decompression, data copying, and comparison consume a large amount of CPU, and disk I/O is caused by reading and writing data. This is crucial for the optimization of compression, Similarly to reading, io_uring can be used to perform a batch process on the compaction to accelerate the compaction process.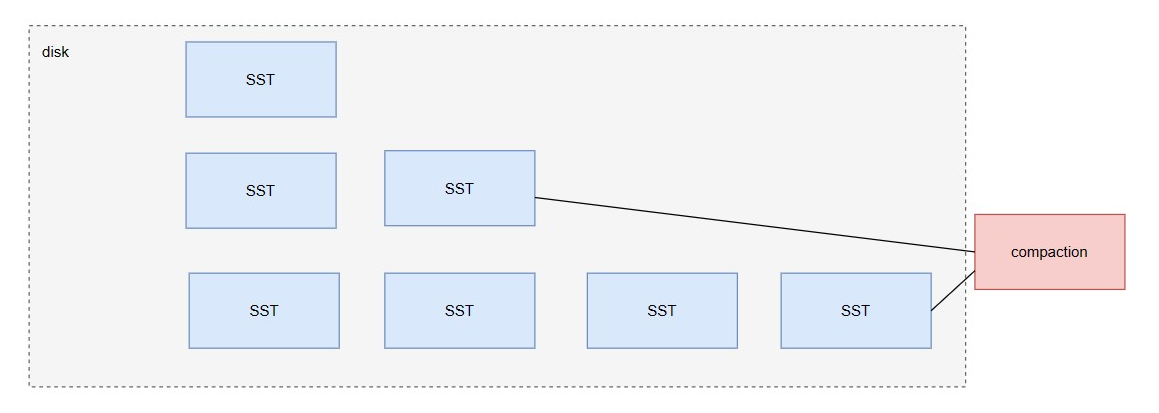
Use case
No response
Related issues
No response
Are you willing to submit a PR?
- [X] Yes I am willing to submit a PR!
Code of Conduct
- [X] I agree to follow this project's Code of Conduct
@hanahmily Please check the proposal and set milestone if this is planned.
@HHoflittlefish777, thank you for sharing your proposal. As we plan to remove MMAP files, which are extensively utilized in LSM-related components, the suggested AIO/DIO solution would play a critical role in this field. In light of this, I have placed the proposal within a long-term milestone, with our initial objective being to apply the solution to the WAL
@HHoflittlefish777, could you please divide this topic into several individual tasks? This will allow us to monitor progress more effectively.
@HHoflittlefish777, could you please divide this topic into several individual tasks? This will allow us to monitor progress more effectively.
I think it should be divided into three sub tasks.
- [ ] Realize io_uring as an independent component.
- [ ] Abstract the read/write interface.
- [ ] Optimize WAL and log structured merge tree using io_uring.
Should I add task lists in description?
@HHoflittlefish777, could you please divide this topic into several individual tasks? This will allow us to monitor progress more effectively.
I think it should be divided into three sub tasks.
- [ ] Realize io_uring as an independent component.
- [ ] Abstract the read/write interface.
- [ ] Optimize WAL and log structured merge tree using io_uring.
Should I add task lists in description?
That's great! Also, it would be better if you create a separate issue for each task. This way, when someone closes the issue, the checkbox for that specific task will automatically be marked as complete.