[SUPPORT] Building workload profile failing after upgrade to 0.11.0 when doing upsert operations
Describe the problem you faced
A clear and concise description of the problem.
Upgrading to 0.11.1 , the deltastreamer is failing to write to a 6GB bucket. It is failing on the
Building workload profile
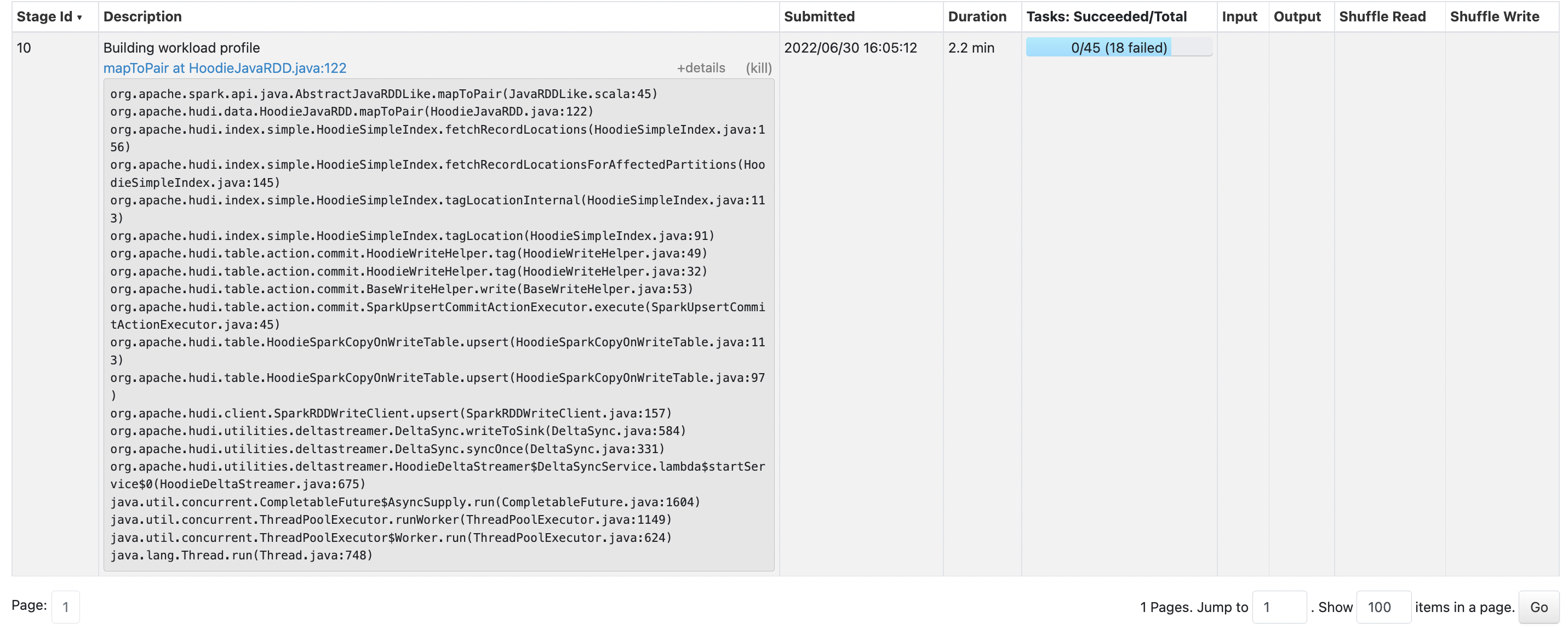
To Reproduce
#!/bin/bash
spark-submit \
--jars /opt/spark/jars/hudi-spark3-bundle.jar,/opt/spark/jars/hadoop-aws.jar,/opt/spark/jars/aws-java-sdk.jar,/opt/spark/jars/spark-avro.jar \
--master spark://spark-master:7077 \
--total-executor-cores 40 \
--executor-memory 4g \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.auth.IAMInstanceCredentialsProvider \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer opt/spark/jars/hudi-utilities-bundle.jar \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-table per_tick_stats \
--table-type COPY_ON_WRITE \
--min-sync-interval-seconds 30 \
--source-limit 25000000 \
--continuous \
--source-ordering-field STATOVYGIYLUMVSF6YLU \
--target-base-path s3a://simian-example-prod-output/stats/querying \
--hoodie-conf hoodie.deltastreamer.source.dfs.root=s3a://example-prod-output/stats/ingesting \
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator \
--hoodie-conf hoodie.datasource.write.recordkey.field=STATONUW25LMMF2GS33OL5ZHK3S7NFSA____,STATONUW2X3UNFWWK___ \
--hoodie-conf hoodie.datasource.write.precombine.field=STATOVYGIYLUMVSF6YLU \
--hoodie-conf hoodie.clustering.plan.strategy.sort.columns= STATONUW25LMMF2GS33OL5ZHK3S7NFSA____,STATMJQXIY3IL5ZHK3S7NFSA____ \
--hoodie-conf hoodie.datasource.write.partitionpath.field= \
--hoodie-conf hoodie.clustering.inline=false \
--hoodie-conf hoodie.clustering.plan.strategy.small.file.limit=100000000 \
--hoodie-conf hoodie.clustering.inline.max.commits=4 \
--hoodie-conf hoodie.metadata.enable=false \
--hoodie-conf hoodie.metadata.index.column.stats.enable=false
Expected behavior
Able to ingest fairly quickly given the source limit
Environment Description
-
Hudi version : 0.11.0
-
Spark version : 3.2.1
-
Hive version :
-
Hadoop version : 3.3.1
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : Yes
Additional context
Add any other context about the problem here.
Stacktrace
Add the stacktrace of the error.
22/06/30 00:34:32 WARN BlockManagerMaster: Failed to remove broadcast 17 with removeFromMaster = true - Cannot receive any reply from /10.10.228.207:58666 in 120 seconds. This timeout is contr
olled by spark.rpc.askTimeout
org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply from /10.10.228.207:58666 in 120 seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at scala.util.Failure.recover(Try.scala:234)
at scala.concurrent.Future.$anonfun$recover$1(Future.scala:395)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at org.apache.spark.util.ThreadUtils$$anon$1.execute(ThreadUtils.scala:99)
at scala.concurrent.impl.ExecutionContextImpl$$anon$4.execute(ExecutionContextImpl.scala:138)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:72)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:288)
at scala.concurrent.Promise.complete(Promise.scala:53)
at scala.concurrent.Promise.complete$(Promise.scala:52)
at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:187)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at scala.concurrent.BatchingExecutor$Batch.processBatch$1(BatchingExecutor.scala:67)
at scala.concurrent.BatchingExecutor$Batch.$anonfun$run$1(BatchingExecutor.scala:82)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:85)
at scala.concurrent.BatchingExecutor$Batch.run(BatchingExecutor.scala:59)
at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:875)
at scala.concurrent.BatchingExecutor.execute(BatchingExecutor.scala:110)
at scala.concurrent.BatchingExecutor.execute$(BatchingExecutor.scala:107)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:873)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:72)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:288)
at scala.concurrent.Promise.tryFailure(Promise.scala:112)
at scala.concurrent.Promise.tryFailure$(Promise.scala:112)
at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:187)
at org.apache.spark.rpc.netty.NettyRpcEnv.org$apache$spark$rpc$netty$NettyRpcEnv$$onFailure$1(NettyRpcEnv.scala:214)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:264)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply from /10.10.228.207:58666 in 120 seconds
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:265)
... 7 more
22/06/30 00:34:32 ERROR ContextCleaner: Error cleaning broadcast 17
org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply from /10.10.228.207:58666 in 120 seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at scala.util.Failure.recover(Try.scala:234)
at scala.concurrent.Future.$anonfun$recover$1(Future.scala:395)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at org.apache.spark.util.ThreadUtils$$anon$1.execute(ThreadUtils.scala:99)
at scala.concurrent.impl.ExecutionContextImpl$$anon$4.execute(ExecutionContextImpl.scala:138)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:72)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:288)
at scala.concurrent.Promise.complete(Promise.scala:53)
at scala.concurrent.Promise.complete$(Promise.scala:52)
at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:187)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at scala.concurrent.BatchingExecutor$Batch.processBatch$1(BatchingExecutor.scala:67)
at scala.concurrent.BatchingExecutor$Batch.$anonfun$run$1(BatchingExecutor.scala:82)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:85)
at scala.concurrent.BatchingExecutor$Batch.run(BatchingExecutor.scala:59)
at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:875)
at scala.concurrent.BatchingExecutor.execute(BatchingExecutor.scala:110)
at scala.concurrent.BatchingExecutor.execute$(BatchingExecutor.scala:107)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:873)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:72)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:288)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:288)
at scala.concurrent.Promise.tryFailure(Promise.scala:112)
at scala.concurrent.Promise.tryFailure$(Promise.scala:112)
at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:187)
at org.apache.spark.rpc.netty.NettyRpcEnv.org$apache$spark$rpc$netty$NettyRpcEnv$$onFailure$1(NettyRpcEnv.scala:214)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:264)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply from /10.10.228.207:58666 in 120 seconds
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:265)
... 7 more
When trying to upgrade to 0.11.1 I receive the following error:
Caused by: java.io.InvalidClassException: org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer$Config; local class incompatible: stream classdesc serialVersionUID = 8242394756111306873, local class serialVersionUID = -7585117557652348753
I use the Spark and Hudi jars provided here:
curl https://repo1.maven.org/maven2/org/apache/hudi/hudi-spark3.2-bundle_2.12/0.11.0/hudi-spark3.2-bundle_2.12-0.11.0.jar --output hudi-spark3-bundle.jar && \
curl https://repo1.maven.org/maven2/org/apache/hudi/hudi-utilities-bundle_2.12/0.11.0/hudi-utilities-bundle_2.12-0.11.0.jar --output hudi-utilities-bundle.jar && \
@rohit-m-99 there might be compatibility issues between hudi-spark3.2-bundle and hudi-utilities-bundle_2.12 in Spark 3.2. However, that may not be the root cause here. A few things to check: (1) the average file sizes and number of files in the target table (2) the memory usage and disk spill of the Spark tasks (3) any warnings in the logs of the executors that fail the stage
Here is the tuning guide for Hudi Spark jobs that is handy: https://hudi.apache.org/docs/tuning-guide
@rohit-m-99 once you figure out the configs to successfully run the job, feel free to let me know and close the ticket.
Was able to successfully run the job by
- Downgrading from Spark 3.2.1 to 3.1.2
- Using hadoop version 3.2.0
- Using hudi-utilities bundle exclusively in the deltastreamer
- Exclusively using the insert operation
#!/bin/bash
spark-submit \
--jars opt/spark/jars/hudi-utilities-bundle.jar,/opt/spark/jars/hadoop-aws.jar,/opt/spark/jars/aws-java-sdk.jar \
--master spark://spark-master:7077 \
--total-executor-cores 10 \
--executor-memory 4g \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer opt/spark/jars/hudi-utilities-bundle.jar \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-table per_tick_stats \
--table-type COPY_ON_WRITE \
--min-sync-interval-seconds 30 \
--source-limit 250000000 \
--continuous \
--source-ordering-field $3 \
--target-base-path $2 \
--hoodie-conf hoodie.deltastreamer.source.dfs.root=$1 \
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator \
--hoodie-conf hoodie.datasource.write.recordkey.field=$4 \
--hoodie-conf hoodie.datasource.write.precombine.field=$3 \
--hoodie-conf hoodie.clustering.plan.strategy.sort.columns=$5 \
--hoodie-conf hoodie.datasource.write.partitionpath.field=$6 \
--hoodie-conf hoodie.clustering.inline=true \
--hoodie-conf hoodie.clustering.plan.strategy.small.file.limit=100000000 \
--hoodie-conf hoodie.clustering.inline.max.commits=4 \
--hoodie-conf hoodie.metadata.enable=true \
--hoodie-conf hoodie.metadata.index.column.stats.enable=true \
--op INSERT
However this results in successful ingestion but is still pretty slow. See following operation:
Given the 250MB source limit seems like only inserting shouldn't be taking on the order of 12 minutes?
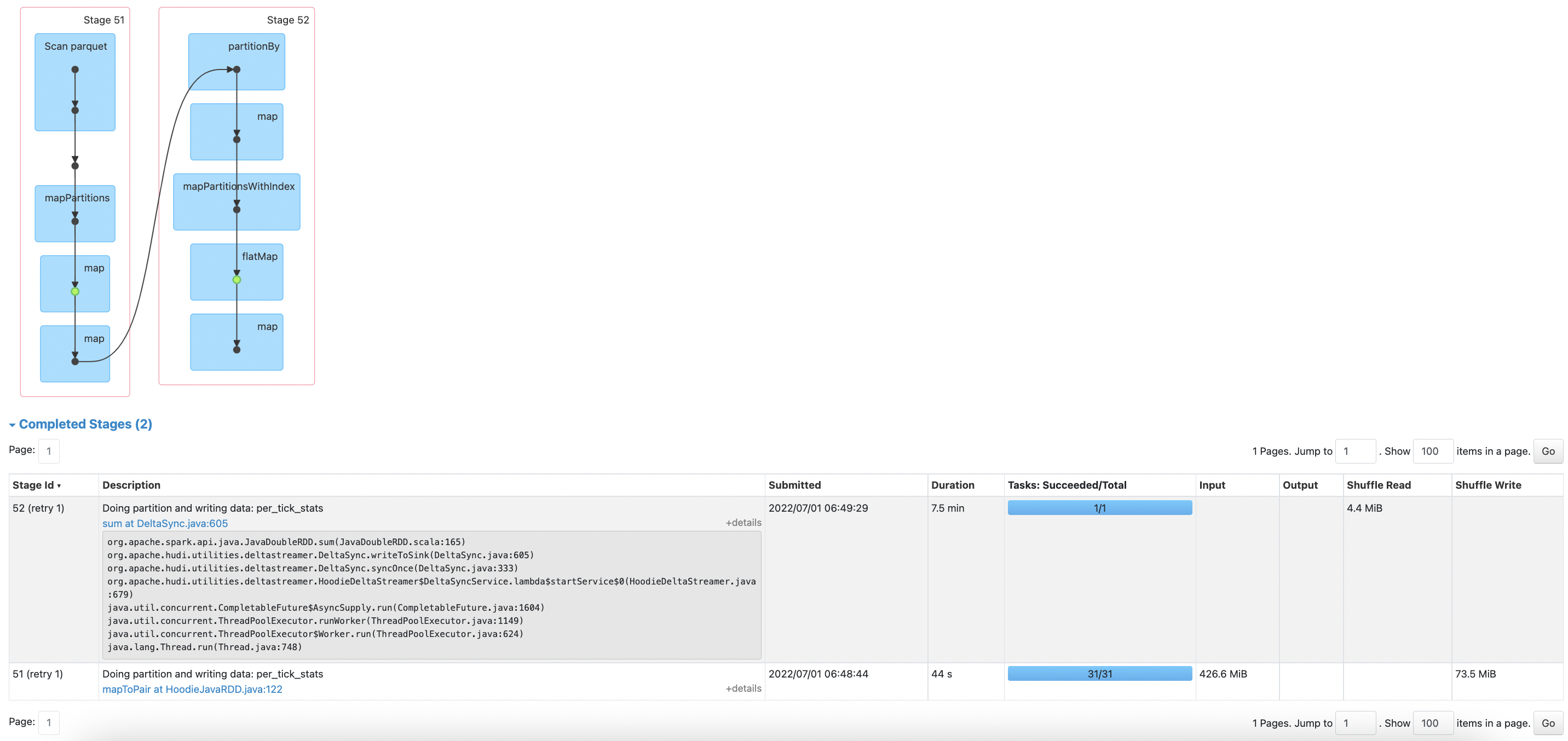
do you know if cleaner got kicked in as part of the write you triggered? do you know if clustering got triggered as part of the wirte you triggered. Since you have inline clustering, and if clustering got triggered, you will see your writes are taking longer to complete since its inline. But if every write is showing higher latency, we need to look into it.
Since we've swtiched to BULK_INSERT / INSERT haven't seen this operation, can close the support ticket.