Optimize write cache: supports configuring multiple caches
fixed: https://github.com/apache/bookkeeper/issues/3322
Motivation
We often find that the two write caches are full, causing write requests to block:
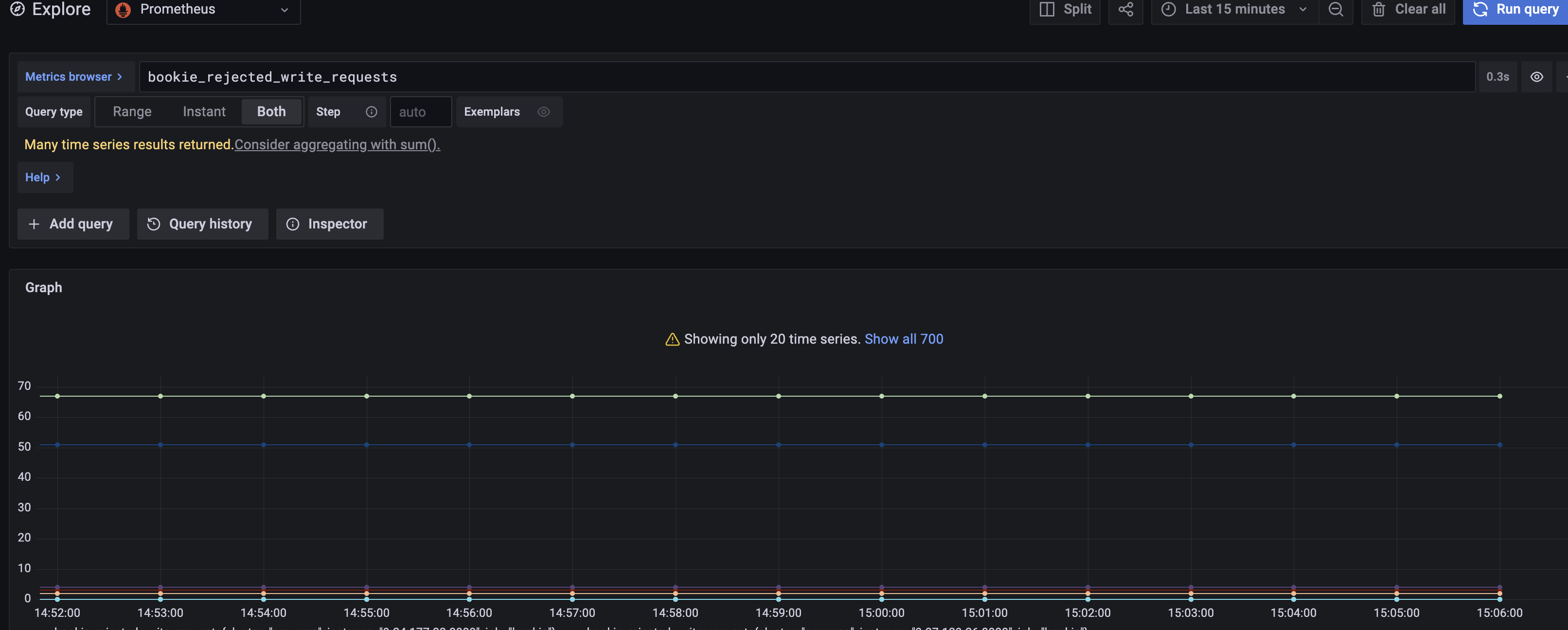
The current write cache has only 2 blocks, which has the following deficiencies:
- Insufficient use of cache: When half of the write cache is flushed, it must wait for all the data in the write cache to be flushed before it can be released. With the same write cache size, if we divide the write cache into multiple blocks, the cache resources can be released faster, preventing the write request from waiting too long for the cache resources to be released;
- The current write cache is allocated according to the configured data directory, so that the write cache resources between directories cannot be shared. When the write cache resources corresponding to one directory continue to be full, it is possible that the cache resources of other directories are still relatively low. Idle, so that the full utilization of the write cache is not used;
Changes
1.Two write caches become multi-cache blocks; 2.In addition to the exclusive write cache for each data directory, all directories also have some shared write cache resources; 3.The default configuration is still 2 write caches;
We replaced 3 nodes in the online bookie cluster. Under the same traffic, the comparison of the delay before and after is as follows:
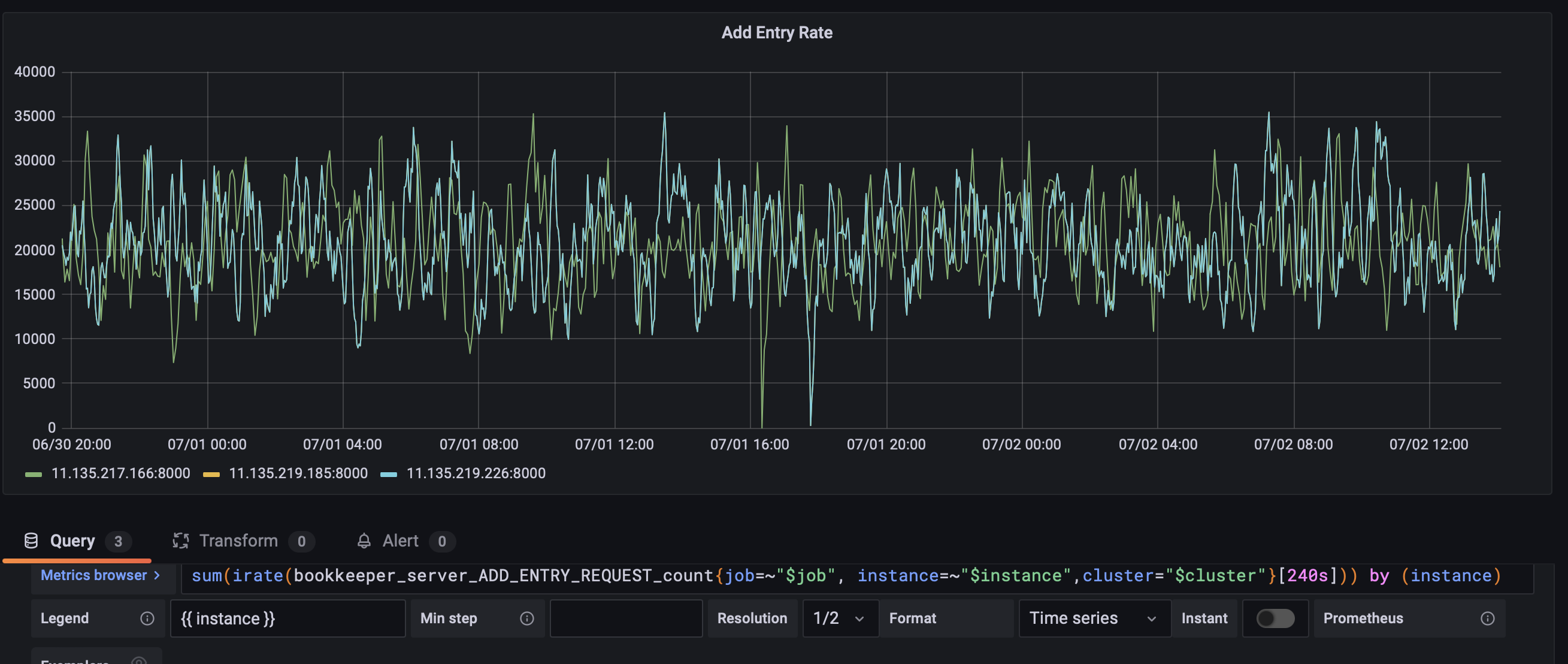
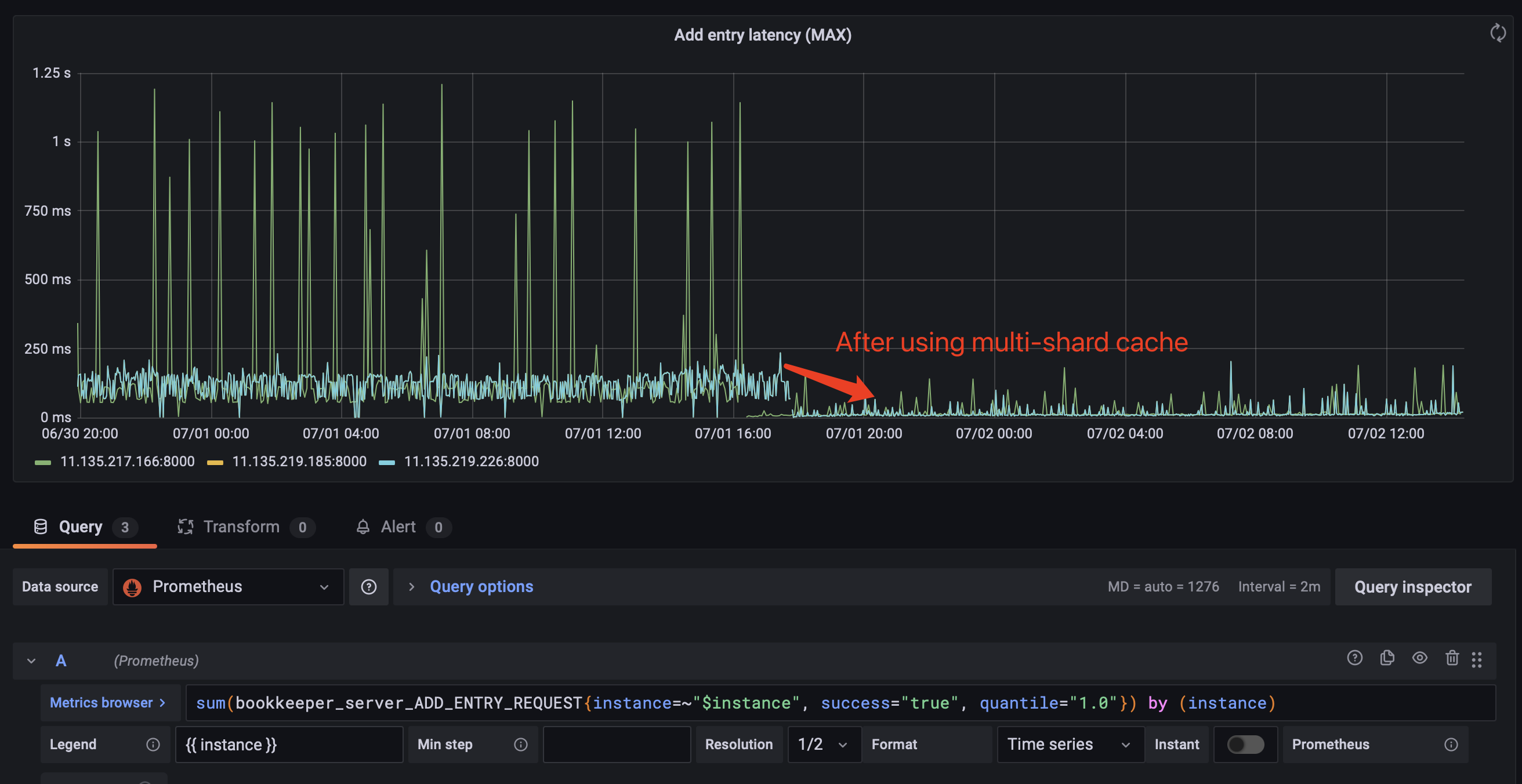
@hangc0276 @eolivelli @StevenLuMT @merlimat @codelipenghui PTAL,thanks!
Have added a unit test for multiple write cache.
PTAL,thanks! @eolivelli
@hangc0276 @eolivelli @StevenLuMT @merlimat @codelipenghui PTAL,thanks!
Sharing the write cache pool with all ledger disks may cause competition for write cache resources, and eventually cause some ledger writes starve to death because they cannot get the write cache.
Suppose there are 3 ledgers, corresponding to 3 disks data1, data2 and data3, and the write cache pool size is 6. The traffic on data1 is relatively high, and the number of applied write caches will be skewed toward data1. If a large number of disk reads occur in data1 at a certain time, the write performance of data1 decreases, causing the write cache of pending flush to increase. The write cache pool is exhausted, and other normal disks data2 and data3 will wait because the write cache cannot be obtained.
Maybe we need a proposal and send to the dev mail list to discuss.
@merlimat @eolivelli @dlg99 Please help take a look, thanks.
Sharing the write cache pool with all ledger disks may cause competition for write cache resources, and eventually cause some ledger writes starve to death because they cannot get the write cache.
Suppose there are 3 ledgers, corresponding to 3 disks data1, data2 and data3, and the write cache pool size is 6. The traffic on data1 is relatively high, and the number of applied write caches will be skewed toward data1. If a large number of disk reads occur in data1 at a certain time, the write performance of data1 decreases, causing the write cache of pending flush to increase. The write cache pool is exhausted, and other normal disks data2 and data3 will wait because the write cache cannot be obtained.
Maybe we need a proposal and send to the dev mail list to discuss.
@merlimat @eolivelli @dlg99 Please help take a look, thanks.
OK
Sharing the write cache pool with all ledger disks may cause competition for write cache resources, and eventually cause some ledger writes starve to death because they cannot get the write cache. Suppose there are 3 ledgers, corresponding to 3 disks data1, data2 and data3, and the write cache pool size is 6. The traffic on data1 is relatively high, and the number of applied write caches will be skewed toward data1. If a large number of disk reads occur in data1 at a certain time, the write performance of data1 decreases, causing the write cache of pending flush to increase. The write cache pool is exhausted, and other normal disks data2 and data3 will wait because the write cache cannot be obtained. Maybe we need a proposal and send to the dev mail list to discuss. @merlimat @eolivelli @dlg99 Please help take a look, thanks.
OK
@hangc0276 @eolivelli discussion email: https://lists.apache.org/thread/25lz5g61vg3h4b3pzrny0vqhhyddy4rj