Eventually Consistent scans / ScanServer feature
This commit builds on the changes added in prior commits 8be98d6, 50b9267f, and 39bc7a0 to create a new server component that implements TabletHostingServer and uses the TabletScanClientService Thrift API to serve client scan requests on Tablets outside the TabletServer. To accomplish this the new server (ScanServer) constructs a new type of tablet called a SnapshotTablet which is comprised of the files in the metadata table and not the in-memory mutations that the TabletServer might contain. The Accumulo client has been modified to allow the user to set a flag on scans to make them eventually consistent, meaning that the user is ok with scanning data that may not be immediately consistent with the version of the Tablet that is being hosted by the TabletServer.
This feature is optional and experimental.
Closes #2411
Co-authored-by: Keith Turner [email protected]
Background
Accumulo TabletServers are responsible for:
- ingesting new data
- compacting (merging) new and old data into files
- reading data from files to support system and user scans
- performing maintenance on Tablets (assignments, merging, splitting, bulk importing, etc).
To support these activities newly ingested data is hosted in memory (in-memory maps) until it's written to a file, and blocks of accessed files may be cached within the TabletServer for better performance. The TabletServer has configuration properties to control the amout of memory available to the heap, in-memory maps, and block caches, and the size of the various thread pools that perform these activities. For example:
tserver.assignment.concurrent.max
tserver.bulk.process.threads
tserver.cache.data.size
tserver.cache.index.size
tserver.cache.summary.size
tserver.compaction.major.concurrent.max
tserver.compaction.minor.concurrent.max
tserver.memory.maps.max
tserver.migrations.concurrent.max
tserver.recovery.concurrent.max
tserver.scan.executors.default.threads
tserver.scan.executors.meta.threads
tserver.scan.files.open.max
tserver.server.threads.minimum
tserver.sort.buffer.size
tserver.summary.partition.threads
tserver.summary.remote.threads
tserver.total.mutation.queue.max
tserver.workq.threads
When a TabletServer exhausts available memory, for whatever reason, an OutOfMemoryError will be raised and the TabletServer will be terminated. When this happens the clients running scans on that TabletServer are paused while the Tablets are re-hosted and then the scans continue on the new TabletServers once the re-hosting process is complete. If the cause of the TabletServer failure was due to scans on a particular Tablet, then this process will repeat until there are no TabletServers remaining or the pattern is identified by a user/admin and the scan process is terminated.
Objective
Provide Accumulo users with the ability to run scans without terminating the TabletServer.
Possible approaches
- Run the scan in a separate process
- Restrict memory usage on a per-scan basis
- Read directly from files in client side scan code. This approach does not allow a small number of clients to scale out a large number of expensive queries to tablet and/or scan servers. It also may lead to an OOM killing a client process that may be executing multiple concurrent scans. It also does not allow client to leverage cache of data and metadata on a scan server or tablet server.
This approach
Create a separate server process that is used to run user scans and give the user the option whether or not to use the new server process on a per-scan basis. Provide the user with the ability to control how many scans will be affected if this new process dies and how many of these new processes to use for a single scan.
Implementation
This PR includes:
- a new server process called the ScanServer.
- changes to the Accumulo client
- changes to the GarbageCollector
- Ancillary changes
Scan Server
The ScanServer is a TabletHostingServer that hosts SnapshotTablets and implements the TabletScanClientService Thrift API. When the ScanServer receives a request via the scan API, it creates a SnapshotTablet object from the Tablet metadata (which may be cached), and then uses the ThriftScanClientHandler to complete the scan operations. The user scan is run using the same code that the TabletServer uses; the ScanServer is just responsible for ensuring that the Tablet exists for the scan code. The Tablet hosted within the ScanServer may not contain the exact same data as the corresponding Tablet hosted by the TabletServer. The ScanServer does not have any of the Tablet data that may reside within the in-memory maps and the Tablet may reference files that have been compacted as Tablet metadata can be cached within the ScanServer (see Property.SSERV_CACHED_TABLET_METADATA_EXPIRATION). The number of concurrent scans that the ScanServer will run is configurable (Property.SSERV_SCAN_EXECUTORS_DEFAULT_THREADS and Property.SSERV_SCAN_EXECUTORS_PREFIX). The ScanServer has other configuration properties that can be set to allow it to have different settings than the TabletServer (Thrift, block caches, etc). It is also possible that a ScanServer may be hosting multiple versions of a SnapshotTablet in the case where scans are in progress, the TabletMetadata has expires, and a new scan request arrives.
Scan servers implement a busy timeout parameter on their scan RPCs. The busytimeout allows a client to specify a configurable time during which the scan must either start running or throw a busy thrift exception. On the client side this busy exception can be detected and a different scan server selected.
Client changes
A new method has been added to the client (ScannerBase.setConsistencyLevel) to configure the client to use IMMEDIATE (default) or EVENTUAL consistency for scans. IMMEDIATE means that the user wants to scan all data related to the Tablet at the time of the scan. To accomplish this the client will send the scan request to the TabletServer that is hosting the Tablet. This is the current behavior and is the default configuration, so no code change is required to have the same behavior. The other possible value, EVENTUAL, means that the user is willing to relax the data freshness guarantee that the TabletServer provides and instead potentially improve the chances of their scan completing when their scan is known to take a long time or require a lot of memory. When the consistency level is set to EVENTUAL the client uses a ScanServerDispatcher class to determine which ScanServers to use. The user can supply their own ScanServerDispatcher implementation (ClientProperty.SCAN_SERVER_DISPATCHER) if they don't want to use the DefaultScanServerDispatcher (see class javadoc for a description of the behavior). Scans will be sent to the TabletServer in the event that EVENTUAL consistency is selected for the client and no ScanServers are running.
Default scan server dispatcher
The default scan server dispatcher that executes on the client side has the following strategy for selecting a scan server.
- It hashes a tablets tableId, end row, and prev endrow. This hash is used to consitently map the tablet to one of three random scan servers. So for a given tablet the same three random scan servers are used by different tablets.
- The client sends a request to one of the three scan servers with a small busytimeout.
- If a busytimeout exception happens, then the default scan server dispatcher will notice this and it will choose from a larger set of scan servers.
- The default scan server dispatcher will expand rapidly to randomly selecting from all scan servers after which point it will start exponentially increasing the busy timeout.
For example if there are 1000 scan servers and a lot of them are busy, the default scan dispatcher might do something like the following. This example shows how it will rapidly increase the set of servers chosen from and then start rapidly increasing the busy timeout. The reason to start increasing the busy timeout after observing a lot busy exceptions is that those provide evidence that the entire cluster of scan servers may be busy. So eventually its better to just go to a scan server and queue up rather look for a non-busy scan server.
- Choose scan server S1 from 3 random scan servers with a busy timeout of 33ms.
- If a busy exceptions happens. Choose scan server S2 from 21 random scan servers with a busy timeout of 33ms.
- If a busy exceptions happens. Choose scan server S3 from 147 random scan servers with a busy timeout of 33ms.
- If a busy exceptions happens. Choose scan server S4 from 1000 random scan servers with a busy timeout of 33ms.
- If a busy exceptions happens. Choose scan server S5 from 1000 random scan servers with a busy timeout of 66ms.
- If a busy exceptions happens. Choose scan server S6 from 1000 random scan servers with a busy timeout of 132ms.
This default behavior makes tablets sticky to scan servers which is good for cache utilization and reusing cached tablet metadata. In the case where those few scan servers are busy the client starts searching for other places to run.
Garbage Collector changes
The ScanServer inserts entries into a new section (~sserv) of the metadata table to place a reservation on the file so that the GarbageCollector process does not remove the files that are being used for the scan. Accordingly GCEnv.getReferences has been modified to include these file reservations in the list of active file references. The ScanServer has a background thread that removes the file reservations from the metadata table after some period of time after the file is no longer used (see Property.SSERVER_SCAN_REFERENCE_EXPIRATION_TIME). The Manager has a new background thread that calls the ScanServerMetadataEntries.clean method on a periodic basis. Users can use the ScanServerMetadataEntries utility to remove file reservations that exist in the metadata table with no corresponding running ScanServer.
In order to avoid race conditions with the Accumulo GC, Scan servers use the following algorithm when first reading a tablets metadata.
- Read metadata for tablet
- Write an ~sserv entries for the tablets files to the metadata table to prevent GC
- Read the meadata again and see if it changed. If it did changes delete the entries from step 2 and go back to step 1.
The above algorithm may be a bit expensive the first time a tablet is scanned on scan server. However subsequent scans of the same tablet will use cached tablet metadata for a configurable time and not repeate the above steps. In the future we may want to look into faster ways of preventing GC of files used by scan servers.
Ancillary changes
- Modifications to scripts (accumulo-cluster, accumulo-service and accumulo-env.sh) have been made to start/stop one or more ScanServers per host.
- The shell commands
grepandscanhave been modified to accept a consistency level (cl) argument - The shell command
listscanshas been modified to include scans running on ScanServers - ZooZap has been modified to remove ScanServer entries in ZooKeeper
- MiniAccumuloCluster has been modified to include the ability to start/stop ScanServers (used by the ITs)
- A new utility (ScanServerMetadataEntries) has been created to cleanup any dangling scan server file references in the metadata table.
Shell Example
Below is an example of how this works using the scan command in the shell.
root@test> createtable test (1)
root@test test> insert a b c d (2)
root@test test> scan (3)
a b:c [] d
root@test test> scan -cl immediate (4)
a b:c [] d
root@test test> scan -cl eventual (5)
root@test test> flush (6)
2022-01-28T18:58:10,693 [shell.Shell] INFO : Flush of table test initiated...
root@test test> scan (7)
a b:c [] d
root@test test> scan -cl eventual (8)
a b:c [] d
In this example, I create a table (1) and insert some data (2). When I run a scan (3,4) with the immediate consistency level, which happens to be the default, the client uses the normal code path and issues the scan command against the Tablet Server. Data is returned because the Tablet Server code path also returns data that is in the in-memory map. When I scan with the eventual consistency level (5) no data is returned because the Scan Server only uses the data in the Tablet's files. When I flush (6) the data to write a file in HDFS, the subsequent scans with immediate (7) and eventual (8) consistency level return the data.
It's weird to ask for eventual consistency. Nobody wants eventual consistency. Eventual consistency is always tolerated, never desired.
Eventual consistency for reads is desired in this case, but perhaps it isn't the best name. The user is willing to sacrifice the liveness of reads for increased availability of the tservers. We could call it Strong Eventual Consistency, but I think that is used mostly for writes https://en.wikipedia.org/wiki/Eventual_consistency#Strong_eventual_consistency. Maybe we could call the traditional scans "Live Scans", like we do with Live Ingest. And then calling the new scans "Cached Scans" or something.
It's weird to ask for eventual consistency. Nobody wants eventual consistency. Eventual consistency is always tolerated, never desired.
Eventual consistency for reads is desired in this case
No, I don't think so. Like you said yourself, what the user desires is increased availability. Eventual consistency is the trade-off they tolerate to get increased availability. The only scenarios where I can imagine an actual preference for the possibility of stale data are nefarious ones where someone is trying to exploit or deceive on the basis of old information.
Using set/getConsistencyLevel on ScannerBase allows us to change the implementation without changing the API. Using a name tied to the implementation will cause API churn if the implementation changes. I'm not tied to set/getConsistencyLevel.
I'm waiting for some consensus before change the API method names.
Using
set/getConsistencyLevelon ScannerBase allows us to change the implementation without changing the API. Using a name tied to the implementation will cause API churn if the implementation changes. I'm not tied toset/getConsistencyLevel.
Yes, but it would allow us to change implementation of that specific characteristic... but that's not the essential characteristic here.
I'm waiting for some consensus before change the API method names.
That's reasonable. Thus far, I haven't really been thinking alternative names. I've only been trying to make the case that consistency level isn't the right way of exposing the feature to users. To think of new names, I think it would be good to think about what the essential characteristics are for scan servers:
- higher availability?
- dynamically scalable hosting?
- read-only service?
- some other sufficient description?
what the user desires is increased availability
I think that depends on who the "user" is. If we are talking about an app developer, the person writing the code that uses the Scanner, then I'm not sure that they will give any thought to system or data availability. If the user is a system administrator, then they will deploy ScanServers for system and data availability.
Looking at PACELC, Accumulo prioritizes Consistency when operating normally (PC/EC). Using ScanServers enables the system administrator and app developer to use Accumulo in a PC/EL manner.
Since this is an API for app developers, do we talk about this in terms of latency? prioritizeLatency() ?
I think the design of this change is great so far but it is a major new feature, with a drastic increase in complexity, touching major parts of Accumulo (scans, API, metadata, configuration, scripts, and introduces another new server). I don't think this should get merged into 2.1. The complexity of this change on top of all the changes already in 2.1 will only further delay the release of 2.1. Main already has many major new features (ZK Prop Store, Overhaul of Compactions code, External Compactions, AMPLE, Master Rename, New Tracing, New Metrics, New SPI, Root Table change) not to mention the 1,130+ tickets marked done for 2.1.
Here is a timeline of the past 4 years:
- 2.0.0-alpha-1 was released 14 Oct 2018 and then 2.0.0-alpha-2 was released 31 Jan 2019
- Non-LTM 2.0.0 was released 02 Aug 2019
- LTM 1.10 was released 03 Sep 2020.
- Bug fix release 1.10.1 was 22 Dec 2020
- Bug fix 2.0.1 was released 24 Dec 2020
- Sadly the first time ever, Accumulo did not have a release in 2021 :frowning_face:
- Bug fix for 1.10.2 was 13 Feb 2022
I think 2.1.0 needs to be released ASAP so it can be tagged as an LTM. Users who are not on 1.10, should upgrade to 1.10.3. Users who upgraded to 2.0 at the time of release have been waiting 3 years (users who snagged the alpha will be 4 years) for the next LTM release. I think it would be a disservice to not have an LTM release this year. Our original plan was to Periodically release a new LTM approximately every 2 years.
That being said Main may already be a major release and need to be called 3.0 so if that is the case, merge away!
I think the design of this change is great so far but it is a major new feature, with a drastic increase in complexity, touching major parts of Accumulo (scans, API, metadata, configuration, scripts, and introduces another new server). I don't think this should get merged into 2.1. The complexity of this change on top of all the changes already in 2.1 will only further delay the release of 2.1. Main already has many major new features (ZK Prop Store, Overhaul of Compactions code, External Compactions, AMPLE, Master Rename, New Tracing, New Metrics, New SPI, Root Table change) not to mention the 1,130+ tickets marked done for 2.1.
I have been working really hard on testing this new feature over the past few weeks. Tonight I finally got to a point where I was seeing scan servers work really well on a small cluster (12 scan servers, 3 tablets servers, 3 datanodes) for the first time. I was running 200 ish random concurrent greps over random large ranges in a single tablet that scanned lots of data and returned little data. To get to that point #2700, #2744, and #2745 needed to be debugged and fixed. Each of these took a lot of time to find and fix. The interesting thing is that these problems were not all specific to scan servers, they were a result of all of the complex changes you mentioned and just happened to be found during intense scan server testing. I think with or without scan servers that 2.1 need s a lot of testing to shake out more latent problems. I think it would be nice to stop adding new features and release a 2.1.0-beta-1 and use it to do that testing and refining. If we did that I would like to see scan servers in 2.1.0 as the last big feature. The feature has gotten a good bit of review. While working on this @dlmarion and I reviewed each others work as we went in addition to this review. If anyone is interested, @dlmarion and I could give a talk about the concepts on slack sometime in order to help guide anyone reviewing.
In addition to reviews, the feature does need more testing. Next week I hope to scale up the scan server testing to larger clusters now that I am getting small cluster to work well. If anyone wants to help I would be happy to show you how to run scan server and some new test in kubernetes. The source code for the testing I have been doing is here, its not documented but I would be happy to offer guidance on how to run it (need Kubernetes+Accumulo+Zookeper+DFS). It supports multiple different test scenarios and I am running through those.
After that, for 2.1.0 in general I would like to set up a test scenario w/ continuous bulk import+external compactions+scan servers+heavy query load and compare that to continuous bulk import+tservers only+heavy query load. This testing could be done w/ a 2.1.0-beta-1 release possibly. If anyone is interested in collaborating on that let me know, could definitely use help.
I do agree that this new feature could break existing functionality unrelated to scan servers. I am optimistic that we can mitigate this with good testing though.
I can't get the ContinuousVerify M/R job in https://github.com/dlmarion/accumulo-testing/tree/ci-verify-consistency-level to use the ScanServer. I have modifed the AccumuloInputFormat configuration several times, I must be missing something. The CI scan, walk, and batch walk do use the ScanServer.
@dlmarion made a few suggestions about the testing. I updated and the report and ran some new tests based on that. The new tests results are in the report.
Summarizing the remaining unresolved issues from the conversation above:
- There is disagreement on the naming of the API methods.
- There is concern about merging this into 2.1 due to the complexity of this change, on top of the other complex changes already in 2.1, that it will require too much time to test that it will delay the release of 2.1.
Did I capture those correctly? Did I miss anything?
I started up a 2 node cluster from commit fcd2738 and my accumulo-testing branch which includes changes to set the consistency level for the continuous walker, batch walker, scanner, and verify applications. I loaded data for an hour using cingest ingest, then used cingest verify jobs to test my changes in commits abcd8a7, 406df63, and c7dd148. The first job ran with consistency level IMMEDIATE (which uses the tserver) and the second job ran with EVENTUAL (which uses the sserver). I confirmed that the scans during the second job showed up on the Active Scans page in the monitor and confirmed that the metrics worked using Grafana. In the Grafana screenshot below you can see the end of the ingest process happening and then the two verify jobs, first one using the tserver and the second one using the sserver.
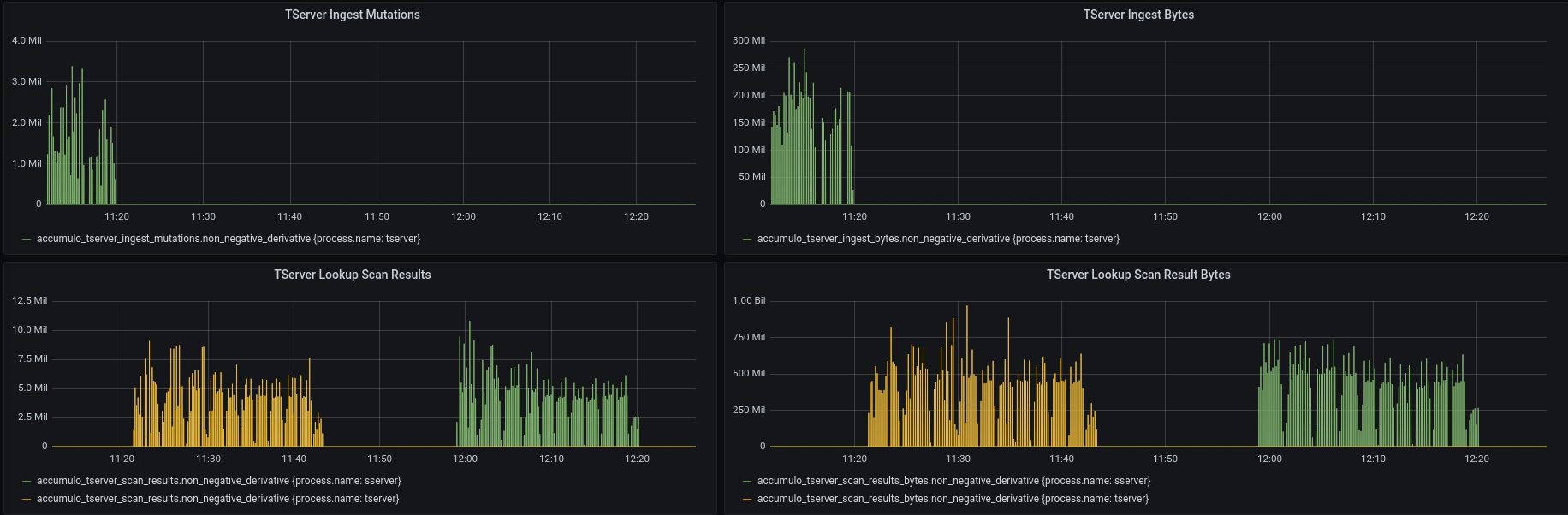
I should also note that the verify jobs both came back with the same results.
I kicked off a full build with ITs and the only ITs that failed are the same ones that are currently failing in main.
I'm thinking it would be better to leverage the scan hints to control a ScanServer-aware dispatcher, rather than add a new API for the consistency level.
I'm thinking it would be better to leverage the scan hints to control a ScanServer-aware dispatcher, rather than add a new API for the consistency level.
I think this goes against the purpose of scan execution hints. They were created to modify execution behavior like priority, caching, and thread pool selection. They were never intended to change anything about data returned, it says so in their javadocs.
https://github.com/apache/accumulo/blob/d5f81877fcc794c8158f38b840d02331e3c563dc/core/src/main/java/org/apache/accumulo/core/client/ScannerBase.java#L342-L361
Slightly related I created a new default scan server dispatcher. Its currently a PR against Dave's branch: dlmarion/accumulo#29. When running 100+ test scenarios this is what I realized I wanted. I wish I had had it when running all of those test, I could have a run a few more test that I wanted to but could not. This new dispatcher is completely configuration driven (replacing the algorithm the previous default dispatcher had) and can be influenced by scan execution hints. If we merge this PR, I could close the PR on Dave's fork and make a PR on the main Accumulo GH.
I'm thinking it would be better to leverage the scan hints to control a ScanServer-aware dispatcher, rather than add a new API for the consistency level.
I think this goes against the purpose of scan execution hints. They were created to modify execution behavior like priority, caching, and thread pool selection. They were never intended to change anything about data returned, it says so in their javadocs.
That's only because we didn't have even the possibility of returning data that wasn't immediately consistent before. Servers that returned data never previously had the option of returning data that was stale before. But, now we have a whole new server type that we can dispatch to. It's not the scan execution hints that are modifying the behavior... it's the configured dispatcher. And, the scan hints are still not affecting the data returned... it's the server that it was dispatched to that is doing that.
A scan hint that explicitly says the eventual consistency is tolerable seems perfectly reasonable to me. It fits very naturally into the whole design of scan hints affecting dispatching. And the ability for a dispatcher to use ScanServers instead of TabletServers also seems perfectly natural. No fundamental design changes at all, and no special-purpose APIs needed to support the feature. The feature all works with the existing design elements wired together in a particular way.
We can easily update the javadoc to clarify that the scan hints affect how the scan is dispatched only, and not the data, but that the dispatcher could dispatch to a server that provides stale data (in the case of scan servers) if the scan hint specified to do so.
https://github.com/apache/accumulo/blob/d5f81877fcc794c8158f38b840d02331e3c563dc/core/src/main/java/org/apache/accumulo/core/client/ScannerBase.java#L342-L361
Slightly related I created a new default scan server dispatcher. Its currently a PR against Dave's branch: dlmarion#29. When running 100+ test scenarios this is what I realized I wanted. I wish I had had it when running all of those test, I could have a run a few more test that I wanted to but could not. This new dispatcher is completely configuration driven (replacing the algorithm the previous default dispatcher had) and can be influenced by scan execution hints. If we merge this PR, I could close the PR on Dave's fork and make a PR on the main Accumulo GH.
The idea of creating a custom dispatcher that would work with the scan servers is exactly what I had in mind. However, I don't think it should be the default.
I think in order to leverage scan servers, the user should:
- Run some ScanServers,
- Configure a
table.scan.dispatcherto an implementation that is ScanServer-aware, and - Configure individual scans with the scan execution hint recognized by that dispatcher to instruct it to dispatch to ScanServers
It's not the scan execution hints that are modifying the behavior... it's the configured dispatcher. And, the scan hints are still not affecting the data returned... it's the server that it was dispatched to that is doing that.
If scan hints+config can change the behavior of a scanner from immediate to eventual I think this could lead to disaster. Consider something like the Accumulo GC algorithm where its correctness relies on only using scanners with immediate consistency. Consider the following situation.
- Person A writes a scanner that requires immediate consistency and sets a scan hint with intention of changing cache behavior to be opportunistic.
- Later Person B changes Accumulo configuration such that it causes the scan hints set by person A to now make the scanner coded by person A be eventually consistent.
If the code in question were the Accumulo GC, this could cause files to be deleted when they should not be. Eventual vs immediate consistency is so important to some algorithms that it should always be explicitly declared per scanner and never be overridden by config that could impact all scanners in an indiscriminate manner without consideration of individual circumstances and per scanner intent.
They [scan hints] were never intended to change anything about data returned
I equate scan hints with Oracle's optimizer hints which allow the user to alter the execution plan for the query. I agree that scan hints should affect how the scan gets executed and not affect the results being returned.
It's weird to ask for eventual consistency. Nobody wants eventual consistency. Eventual consistency is always tolerated, never desired.
I think setting the consistency level is the means for achieving a specific goal. Some applications may require strict consistency for correctness and others may be more concerned with speed. I looked for how other products exposed consistency levels in their api. Specifically I was looking for products that used consistency level and not some other name to show that it's not uncommon. This is by no means a complete list, but just some examples of products that document their consistency levels and then provide a method for setting the consistency level in their api.
-
Microsoft Cosmos DB uses a method called
consistencyLevel -
Amazon DynamoDB has read operations that take a
ConsistentReadparameter - HashiCorp Consul has a HTTP API query parameter for specifying the consistency level
Since immediate/strict consistency is the default, maybe we just need a method to disable it for a specific query instead of specifying the value. For example, enableEventualConsistency(), relaxReadGuarantees(), disableConsistentReads(), allowStaleReads(), etc.
I'm also thinking that there should be a table configuration that enables/disables this feature. Currently, an admin can spin up some ScanServers and an application developer can enable eventual consistency, but do we want that on the metadata table for example?
I'm also thinking that there should be a table configuration that enables/disables this feature. Currently, an admin can spin up some ScanServers and an application developer can enable eventual consistency, but do we want that on the metadata table for example?
For a table where that are zero known uses cases for eventual consistency and enabling it is likely a mistake having that feature makes sense to me.
@keith-turner wrote:
It's not the scan execution hints that are modifying the behavior... it's the configured dispatcher. And, the scan hints are still not affecting the data returned... it's the server that it was dispatched to that is doing that.
If scan hints+config can change the behavior of a scanner from immediate to eventual I think this could lead to disaster. Consider something like the Accumulo GC algorithm where its correctness relies on only using scanners with immediate consistency. Consider the following situation.
- Person A writes a scanner that requires immediate consistency and sets a scan hint with intention of changing cache behavior to be opportunistic.
- Later Person B changes Accumulo configuration such that it causes the scan hints set by person A to now make the scanner coded by person A be eventually consistent.
I think it's an exaggeration to call this a disaster. Scan hints controlling a specific configured dispatcher's behavior should already be documented in that dispatcher's documentation and stable before users can rely on it for stable behavior. This is not a problem. If we change the semantics of any configuration, we can break things users intended with their previous configuration. This situation is no different... scan hints are just configuration for a dispatcher that are semantically constrained to that dispatcher's documented behavior.
Having this as behavior with an explicit API method to configure isn't any different. A configured dispatcher could just ignore that configuration and dispatch to an eventually consistent ScanServer instead of a TabletServer. Hints are just another kind of configuration. Whether that configuration is set by an API with a different name, or set by the API that sets hints, we're in the same situation... we have to trust the dispatcher that the user has configured to do the thing we expect it to, based on whatever configuration is set on the scan task, regardless of how it is set.
The main difference here, is that it already logically makes sense to use scan hints to modify the dispatcher behavior, because that's what that configuration is for.
If the code in question were the Accumulo GC, this could cause files to be deleted when they should not be. Eventual vs immediate consistency is so important to some algorithms that it should always be explicitly declared per scanner and never be overridden by config that could impact all scanners in an indiscriminate manner without consideration of individual circumstances and per scanner intent.
I think the discussion of the accumulo-gc is a bit of a red herring. That scans the metadata. It is already well documented that all metadata scans are always dispatched to an executor named "meta", and should always be immediately consistent. Even it if it wasn't, though, I don't think by setting the scan configuration via executor hints is substantially different than setting other scan configuration via other APIs. It's all configuration, and the dispatcher's behavior ultimately has to be documented, known, and relied upon in order to get any kind of guarantees about any scan results.
@dlmarion wrote:
Since immediate/strict consistency is the default, maybe we just need a method to disable it for a specific query instead of specifying the value. For example,
enableEventualConsistency(),relaxReadGuarantees(),disableConsistentReads(),allowStaleReads(), etc.I'm also thinking that there should be a table configuration that enables/disables this feature. Currently, an admin can spin up some ScanServers and an application developer can enable eventual consistency, but do we want that on the
metadatatable for example?
I would like to keep configuration simple. I've read so many articles about software complexity killing projects, and I think Accumulo is already in that risky area, where every new complex feature we add, often for niche use cases, adds an obtuse amount of complexity. We already have an overwhelming amount of single-purpose configuration elements that micro-manage so many elements of Accumulo's operations. We have an opportunity here to keep things simple. The dispatcher is already one such configurable component. If the dispatcher is responsible for deciding which server to use, and we already have a way to pass configuration to a dispatcher through the scan hints, then I don't see why we need to have additional configuration that add to the bloat. Let's be modular... let's let the configurable dispatcher to the work. We can add this feature without any additional user facing complexity... if we recognize that scan hints are merely dispatcher configuration, and the dispatcher is already a pluggable module, and all of these configurations are already per-table or per-scan.
Having this as behavior with an explicit API method to configure isn't any different. A configured dispatcher could just ignore that configuration and dispatch to an eventually consistent ScanServer instead of a TabletServer.
That can not happen in this PR as its currently coded. When a scanner is set to immediate consistency the scan server dispatcher plugin is never consulted and only the tserver is used.
Having this as behavior with an explicit API method to configure isn't any different. A configured dispatcher could just ignore that configuration and dispatch to an eventually consistent ScanServer instead of a TabletServer.
That can not happen in this PR as its currently coded. When a scanner is set to immediate consistency the scan server dispatcher plugin is never consulted and only the tserver is used.
So, there's two separate dispatching paths? And the path for the scan server bypasses the per-table configured dispatcher table.scan.dispatcher? That seems very confusing, especially since this PR adds new properties to configure sserver.scan.executors... but there's no way to select an executor via hints to a dispatcher? My understanding is that we wanted to try to mirror the tserver scan behavior as much as possible. Having two paths, without a dispatcher in the scan server path is very confusing. Have two paths, period, is very confusing. It just seems dramatically simpler to have a per-table dispatcher that is aware of scan servers and capable of dispatching to sserver.scan.executors (depending on hints) in addition to the usual tserver.scan.executors.
Even if a dispatcher is added to the path for the scan server, it still seems far more complex than just relying on a single dispatcher... which also gives us the "enabled or disabled for a table" feature that Dave mentioned... because you can choose whether to configure a dispatcher that is scan server aware or not for a given table... without any new APIs.
I'm probably completely misunderstanding how the dispatching changed in this PR. Is there a diagram or something to help illustrate the new dispatching design?
Is there a diagram or something to help illustrate the new dispatching design?
Here is one.
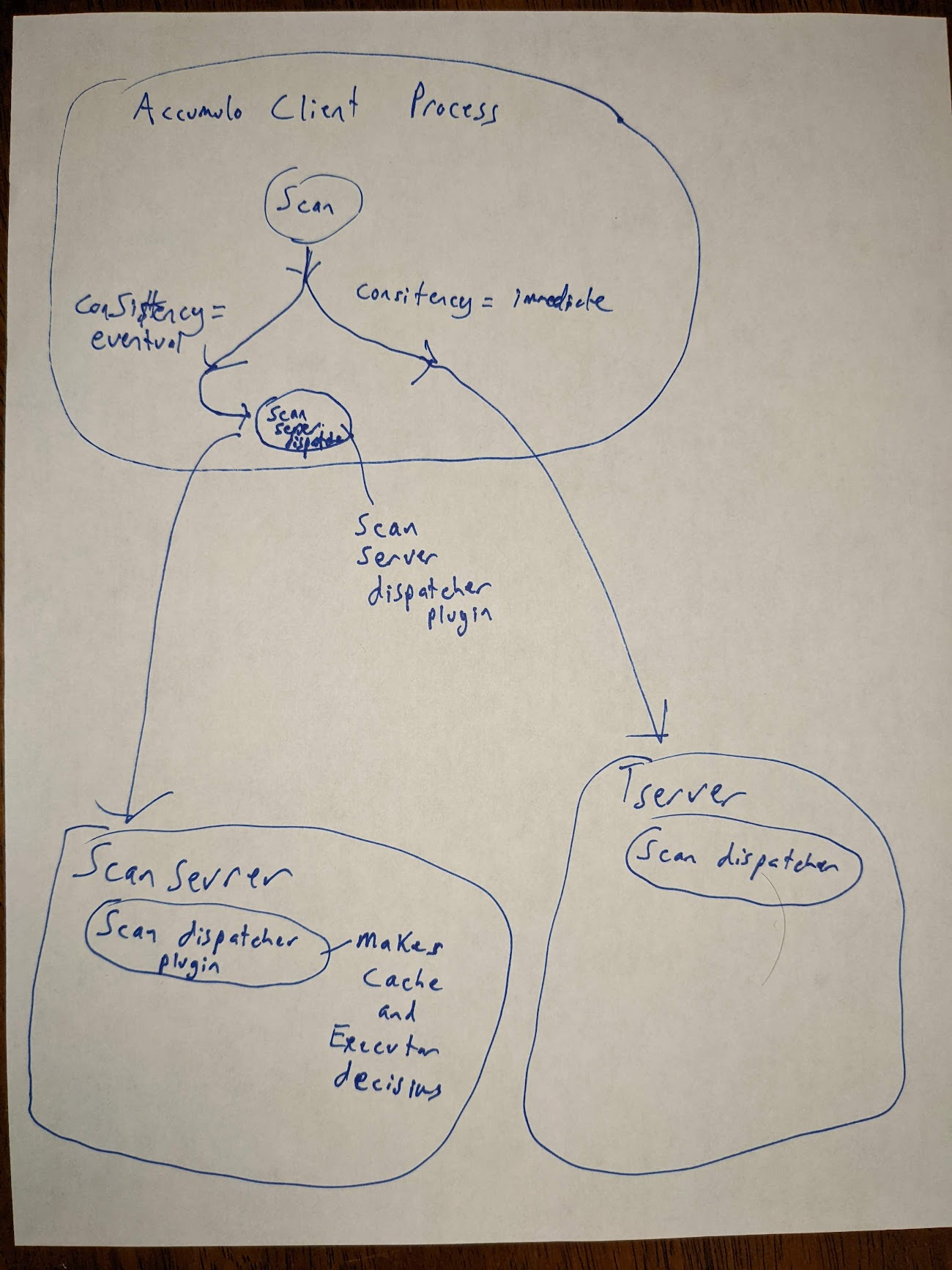
The ScanServerDispatcher plugin is new and it runs client side to determine which scan server to use for eventually consistent scans and what busy timeout to use. If the scan fails because of busy timeout its consulted again and can pick another scan server. The busy timeout feature is unique to scan servers. This new plugin is configured via accumulo client config,
On the server side (tserver and scan server) there is an existing per table ScanDispatcher plugin that determines what thread pools to use and how to use cache. This existing plugin makes no decision about which scan server to use as that needs to be done client side for efficiency. This existig plugin is configured via table props.
Execution hints are made available to both plugins and some other plugins not mentioned. The plugins are not obligated to do anything with hints.
Okay, thanks. That helps. I guess I was thinking the current dispatcher ran in the client side. So, using scan hints wouldn't even work the way I imagined it. We need the scan server dispatcher plugin to run on the client side first.
A few thoughts based on my new understanding:
- The client side dispatcher concept is very different from the executor dispatching that is done in the tserver, but has a very similar name. It might be helpful to have this named completely differently... like "server chooser" or "tablet scanner server type selector" or something along those lines (not necessarily as verbose as that latter one... but something to make it clearly distinct from the executor pool dispatching inside the server).
- It would be nice if the scan server dispatching inside the scan server worked the same as the existing per-table dispatcher inside the tserver. Ideally, the same dispatcher would work in both servers, without a new dispatcher SPI specifically for the scan server.
One thing is clear, my previous suggestion about using scan hints can be thrown out. Those are specifically scan executor hints, and should be used only by the dispatcher inside the server, because the dispatcher inside the server dispatches to an executor. The choice of which server type is an entirely different kind of dispatching, not to a scan executor, but to a server. So, that does imply a new kind of SPI or configuration to do the server selection inside the client (or... a different client entirely rather than modify the existing client).
This is what I'm picturing now (very similar to yours, but tries to keep the servers similar, and makes server type selection more explicit):
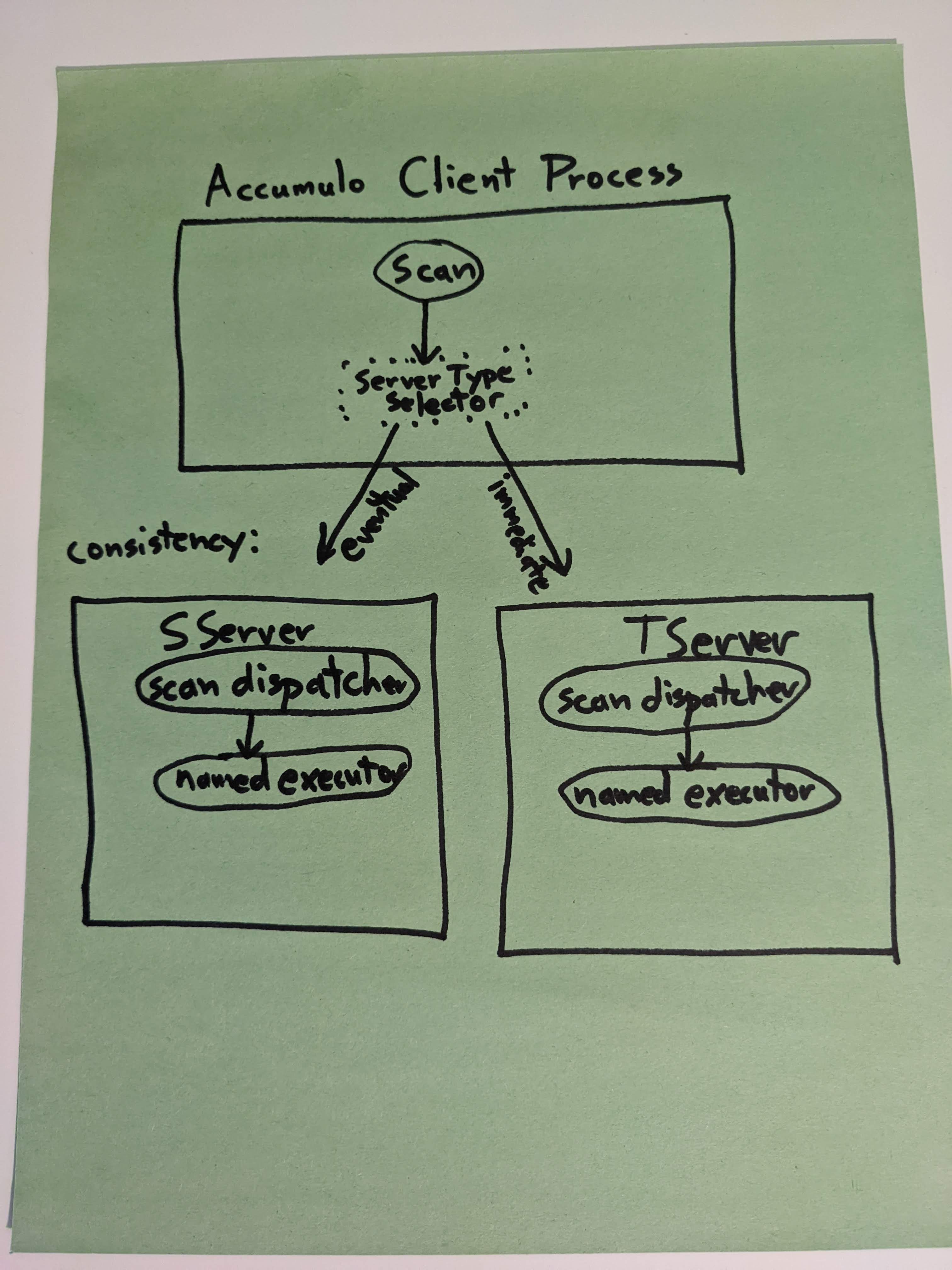
The client side dispatcher concept is very different from the executor dispatching that is done in the tserver, but has a very similar name. It might be helpful to have this named completely differently... like "server chooser" or "tablet scanner server type selector"
I kinda like ScanServerChooser
So, that does imply a new kind of SPI or configuration to do the server selection inside the client (or... a different client entirely rather than modify the existing client).
I am not sure if you are implying the client side plugin should have control over choosing tservers and sservers. If so, I would like to avoid that and keep the plugin narrowly scoped to choosing scan servers because of the following :
- Any scan server can be chosen to service a query for a tablet. Only one tserver can be chosen to service a tablet scan.
- Scan servers have a busy timeout and tservers do not. The plugin specifies the busy timeout to use.
- History of busy timeout events is given to the plugin. This allows it to possibly choose a different scan server based on past events.
The way we choose which tserver vs which scan server is very different and I don't think it would be good to try to have one plugin do both. Also the logic for choosing a tserver is not flexible and there is basically only one way to do it ATM.
Working on this I have realized if we did have anything pluggable for tservers, it would probably not be around choosing a tserver but more about backoff strategies in the case of failures. I think that would be another narrowly scoped plugin that makes very specific decisions.
Those are specifically scan executor hints, and should be used only by the dispatcher inside the server, because the dispatcher inside the server dispatches to an executor.
I think it makes sense to pass the scan exec hint so the ScanServerChooser/ScanServerDispatcher plugin in addition to plugins dealing with caching, prioritizationm and thread pool selection on the server side. Consider the case where in the code I set scan_hints to either scan_type=gold, scan_type=silver, or scan_type=iron. I could start off configuring multiple run time plugins to do the following (on tserver and scan server).
- When we see scan_type=gold enable full caching, use a dedicated thread pool A with 32 threads
- When we see scan_type=silver enable opportunistic caching, use a thread pool B with 8 threads, set the scan prio to 1 in the thread pool queue
- When we see scan_type=iron enable disable caching, and use a thread pool B with 8 threads, set the scan prio to 2 in the thread pool queue
Then later I could change config at runtime to react to the scan types differently like
- When we see scan_type gold and its eventual, then use a dedicated group of scan servers with large memory and full caching enabled
- When we see scan_type silver and its eventual use the default set of scan servers. On the scan server enable caching, use a thread pool B with 8 threads, set the scan prio to 1 in the thread pool queue for this scan type.
- When we see scan_type iron and its eventual use the default set of scan servers. On the scan server disable caching, use a thread pool B with 8 threads, set the scan prio to 2 in the thread pool queue for this scan type.
So by passing the hints to any plugin involved in scan execution we can change runtime config to respond to those hints in different ways over time (using feedback from metrics) including scan server selection.
It would be nice if the scan server dispatching inside the scan server worked the same as the existing per-table dispatcher inside the tserver. Ideally, the same dispatcher would work in both servers, without a new dispatcher SPI specifically for the scan server.
The plugins in the scan server does work exactly the same as in the tserver with these changes. The only difference is they have a different set of config prefixes (well the ones that are not per table). Config for dispatching to thread pools is per table and has the exact same config across tserver and sserver. Config for creating thread pools and cache to service scans is at the server level and therefore has diff config prefix for sserver but the exact same config props as tservers.
It may be useful to add information to the following that informs a server side dispatcher if its running in a tserver or a scan server. Not sure about this. Would be follow on work.
https://github.com/apache/accumulo/blob/418eee8fa0abed50f30cb6c97184964f924d2c67/core/src/main/java/org/apache/accumulo/core/spi/scan/ScanDispatcher.java#L98-L110
I like ScanServerSelector also as a name. I do think it would be good to have something besides Dispatcher in the name to avoid confusion w/ the server side plugin.
@keith-turner wrote:
I am not sure if you are implying the client side plugin should have control over choosing tservers and sservers. If so, I would like to avoid that and keep the plugin narrowly scoped to choosing scan servers because of the following :
That was what I was suggesting. The advantage of flattening the decision of choosing between tservers and sservers, and choosing among the sservers is that there is only one branching point when you zoom out and look at the the server selection logic, instead of two. One simplifies the bigger picture, but potentially makes the plugin more complicated. Keeping those decisions separate makes the zoomed out view look more complicated, but the job of the plugin is simpler.
Having one decision point also enables more complex selection features in the plugin, like "I don't care if I get a tserver or a sserver... treat them equally", or "try a tserver first, but settle for a sserver if the tserver's load is high". The plugin can't do that if it is narrowly focused on a decision after the tserver is excluded.
- Any scan server can be chosen to service a query for a tablet. Only one tserver can be chosen to service a tablet scan.
The selector plugin does not need to be responsible for the all the logic that identifies the one tserver. It can be provided with a Supplier that executes our current logic, so it can have the option of selecting the tserver, but without all the complexity of locating it.
- Scan servers have a busy timeout and tservers do not. The plugin specifies the busy timeout to use.
- History of busy timeout events is given to the plugin. This allows it to possibly choose a different scan server based on past events.
I don't think there's any reason a tserver can't have some of those features, in case a selector plugin wanted to treat the tserver as another possible scan server to choose from. Those features wouldn't be of much use if immediate consistency were required... but if it's not required, it would certainly be acceptable for a selector to choose the tserver if the sservers are busy or unavailable.
I'm also wondering if the "busy timeout" concept can be made more generalized. Like, instead of a queue wait timeout, a sserver could be considered "busy" if its CPU load was high or something else. Computing this weight could be another SPI added in future. The first pass could just be the current "busy timeout"... just with a more generic name, so it doesn't strictly have to be a timeout in future, but some other selection weight.
Also the logic for choosing a tserver is not flexible and there is basically only one way to do it ATM.
As explained here, I'm not proposing that we diverge from the current one way to do this. I'm only proposing that the selector be allowed to select it.
I think it makes sense to pass the scan exec hint
I concede this point. The selection of the sserver is still part of the overall execution of the scan, and could make use of these hints, even if they are not used to determine whether the tserver is selected or the sservers are selected.
@keith-turner - I think your latest commit left ScanServerIT.testBatchScannerTimeout in a broken state.
@ctubbsii - I believe that I have addressed most, if not all, of your comments either by responding, creating a follow-on issue, or fixing the code.
@ctubbsii @keith-turner @milleruntime @EdColeman - If there is no further discussion, then I intend on merging this by COB today.
I haven't looked at the changes since my last PR, but feel free to merge... I can look at them later. I saw a bunch of new issues, but they are all over the place, and it's hard for me to track those all. After this is merged, I'll probably go line by line through my comments here to ensure that each of them have been done, or I'll do them as a follow on. If I do that, I'm not going to track down each of the separate issues that were created, though... I'm just going to do one PR to fix what I think needs fixing (if it hasn't already been done by the time I take a look).