succinct
 succinct copied to clipboard
succinct copied to clipboard
Enabling queries on compressed data.

[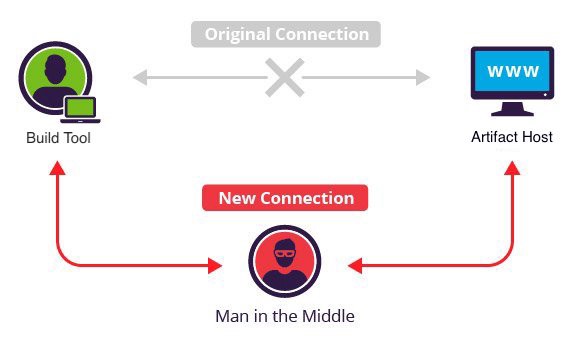](https://medium.com/@jonathan.leitschuh/want-to-take-over-the-java-ecosystem-all-you-need-is-a-mitm-1fc329d898fb?source=friends_link&sk=3c99970c55a899ad9ef41f126efcde0e) - [Want to take over the Java ecosystem? All you need is a MITM!](https://medium.com/@jonathan.leitschuh/want-to-take-over-the-java-ecosystem-all-you-need-is-a-mitm-1fc329d898fb?source=friends_link&sk=3c99970c55a899ad9ef41f126efcde0e) - [Update: Want to take over the Java ecosystem? All you need is a MITM!](https://medium.com/bugbountywriteup/update-want-to-take-over-the-java-ecosystem-all-you-need-is-a-mitm-d069d253fe23?source=friends_link&sk=8c8e52a7d57b98d0b7e541665688b454)...
Fixes: https://github.com/amplab/succinct/issues/35
scala> spark.read.json(rdd) res59: org.apache.spark.sql.DataFrame = [ProgressionRegex: string, Progressions: array ... 27 more fields] scala> val flattenedDf = spark.read.json(rdd) flattenedDf: org.apache.spark.sql.DataFrame = [ProgressionRegex: string, Progressions: array ... 27 more fields] scala>...
Faster scans can be supported by having a snappy compressed representation of the data along with the Succinct data structures; operations on the Succinct RDDs / DataFrame that require full...
val df = spark.sql("SELECT * from table_name limit 100") df.write.format("edu.berkeley.cs.succinct.sql").save("/Users/hello/df") This is what happens: java.lang.IllegalArgumentException: Unexpected type. BinaryType at edu.berkeley.cs.succinct.sql.SuccinctTableRDD$$anonfun$7.apply(SuccinctTableRDD.scala:223) at edu.berkeley.cs.succinct.sql.SuccinctTableRDD$$anonfun$7.apply(SuccinctTableRDD.scala:213) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)...
The current Spark SQL interface still uses constructs from Spark 1.4.0. The implementation can benefit from the optimizations if the Data Source is brought up to date with Spark 2.0...
The current search() implementation performs a case-sensitive match. We should add a flag to the search call to make it case insensitive, i.e., ``` scala def search(query: String, caseInsensitive: Boolean...
[](https://infosecwriteups.com/want-to-take-over-the-java-ecosystem-all-you-need-is-a-mitm-1fc329d898fb) --- This is a security fix for a high severity vulnerability in your [Apache Maven](https://maven.apache.org/) `pom.xml` file(s). The build files indicate that this project is resolving dependencies over HTTP...