Store objects using normalized file names to allow special chars
The S3 API allows for special characters in the object keys.
We don't yet support all special chars and the character / is interpreted as a directory delimiter (S3 doesn't do that).
I propose that we store all objects using a UUID file name and map the original object key to the UUID in a map.
-
Based on the
listObjectsITtests, here's a sample bucket with different potentialdelimiters: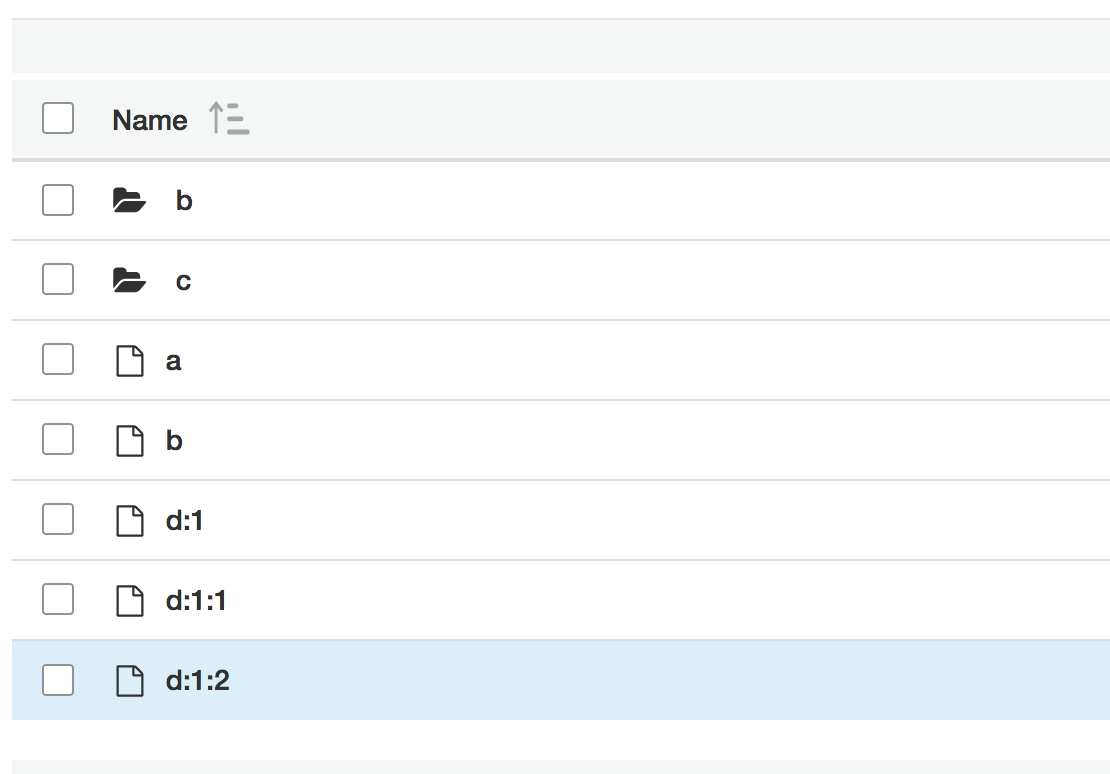
-
This is misleading because S3 is not a file system so the words
delimiteris not equal toFile.separatorit is just any string that can be used cut off the rest of the path entry. Basically
<prefix>wordswords<delimiter>wordswords
<prefix>wordswords<not_a_delimiter>wordswords
<prefix>wordswords<delimiter>wordswords2
<prefix>wordswords<not_a_delimiter>wordswords3
<prefix>wordswords<delimiter>wordswords3
<prefix>wordswords<not_a_delimiter>wordswords3
Would show up if no delimiter is sent.
but if you send the <delimiter> then only:
<prefix>wordswords<not_a_delimiter>wordswords
<prefix>wordswords<not_a_delimiter>wordswords3
<prefix>wordswords<not_a_delimiter>wordswords3
-> commonPrefixes:
<prefix>wordswords<delimiter>
would show up
I tried to add that test because I have a use case with a ~ delimiter and...
Found another issue in the meantime:
listV1[12: prefix=d, delimiter=:](com.adobe.testing.s3mock.its.ListObjectIT) Time elapsed: 0.222 s <<< FAILURE!
java.lang.AssertionError:
Returned keys are correct
Expected: an empty collection
but: <[d:1, d:1:1]>
I did not realize that we had this issue, but with version 2.5.0, I refactored more or less the whole S3Mock core, and we now store Objects in UUID-folders instead of using the incoming key values.
With this change, I could get rid of many workarounds only needed to properly encode/decode the keys in order to make them usable for paths in Java / the file system. :)
This has now been implemented. 🎉