note

note copied to clipboard
分析数据库学习记录 OLAP
个人理解的特点
- 是一个 MySQL 的存储引擎,使用协议语法同 MySQL,接入非常简单;
- 列式存储+压缩(最高压缩比30:1),相同数据量使用机器数少,有效降低机器成本;
- 根据数据特性选择压缩算法,如 GZIP, LZ4;
- 通过 build on insert, build on select 构建多个额外的 meta 数据,提高查询效率;
- 同类产品:Infobright(起源),Sybase,HANA,Vertica,Greenplum
存储结构剖析
HiStore 是按 Node (包) 为单位来存储数据,默认一个包有 64k 条数据。只有一个包存满 64 k才会刷到磁盘。
如下图,HiStore 除了数据列式压缩存储按 Nodes 存储,还会有单独一块 Meta 信息(包括MDN,Numeric Histogram,String & Character MAP,Distributions,Pack-2-Pack),一直在内存中,提高查询时的效率。
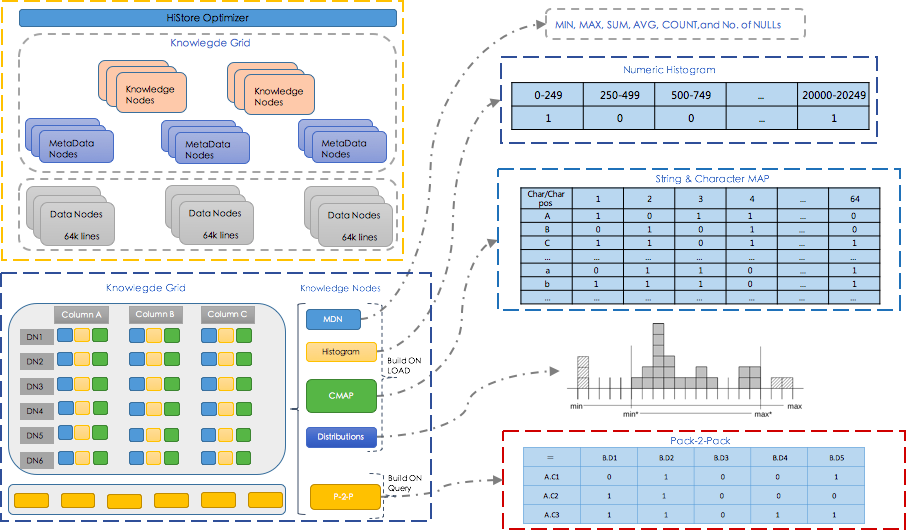
以下都是 Nodes 维度的数据
MDN
- build on insert
- 记录这个 Node 的最大值、最小值、平均值、计数等
Numeric Histogram
- build on insert
- 仅有数值类的列才会存在
- 把当前 Node 所有数据按最小值到最大值划分为 1024 个区间,每个区间以 0,1 表示在这个区间内是否值存在
String & Character MAP (知识图谱)
- build on insert
- 仅有字符串的列才会存在
- 以 ascii 码(128个) 作为行,以 字符串位置(第几个,最大64) 作为列的一个二进制表格,默认二进制表格全是0,在字符对应的作为置1。如 abc,bbc 两个字符串, abc 对应的三个位置 (a, 1), (b, 2), (c, 3) 置为1, bbc 对应的三个位置 (b, 1), (b, 2), (c, 3) 置为1。 当字符串超过 64 则截断
Distributions
- build on insert
- 存储某个区间的数量范围
Pack-2-Pack
- build on select
- 当有过一次 join 查询后才会构建
- 对 join 的两个列所在的包,记录一个二进制表格,默认全是 0,如果 join 有结果,则置为1。 如 Node A 的c1列 和 Node B 的d1列有 join 结果,那么在对应的位置置为 1。
仔细品读,发现上面做的这些查询优化都非常的有趣,哈哈哈。