关于训练终止的问题
我设置total iter为12w,训练在9w的时候输出"End of training",中间没有出现任何报错。 起初我以为是代码内部有EarlyStop机制,但是现在看来好像不是。 以下是我两次训练的输出文档。total iter都设置为12w,在9w终止训练,性能最好的模型分别对应迭代次数为6w和9w。 这有些奇怪。

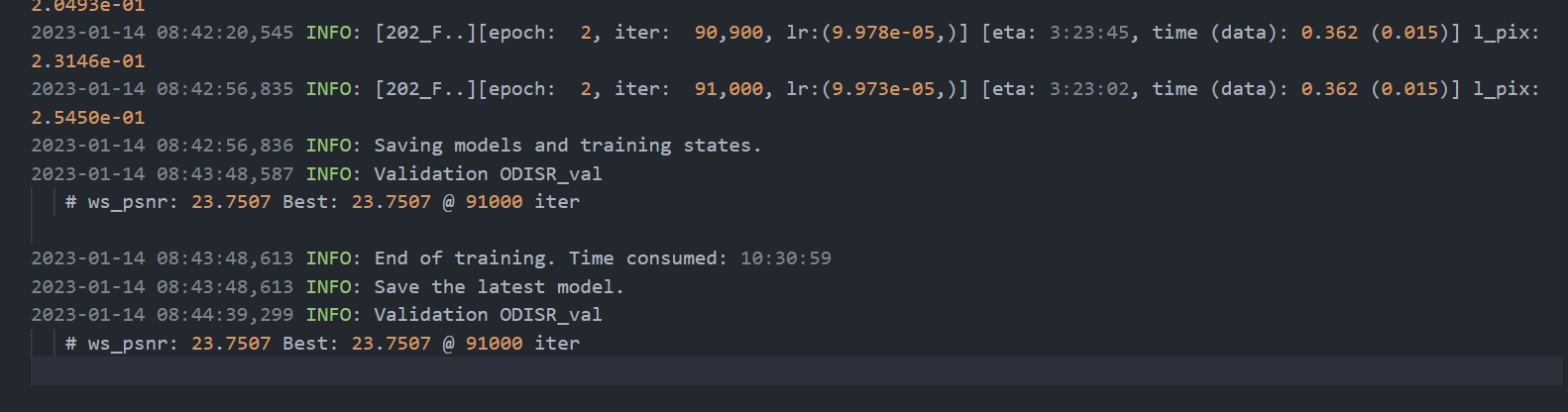
我设置total iter为12w,训练在9w的时候输出"End of training",中间没有出现任何报错。 起初我以为是代码内部有EarlyStop机制,但是现在看来好像不是。 以下是我两次训练的输出文档。total iter都设置为12w,在9w终止训练,性能最好的模型分别对应迭代次数为6w和9w。 这有些奇怪。
您好,我也遇到了同样的问题。请问您解决这个问题了吗,有什么解决方案吗?
我也遇到了这个问题,我的num_gpu设置为2,batch_size_per_gpu为12,total_iter为100000
但在日志里成了这个样子:
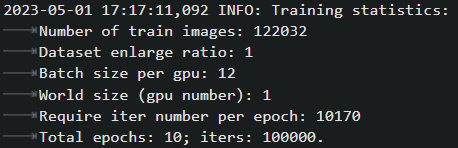 最后也是在55924 iter停止了(5000validation一次,best @ 55924 iter就说明停在第55924 iter)
最后也是在55924 iter停止了(5000validation一次,best @ 55924 iter就说明停在第55924 iter)
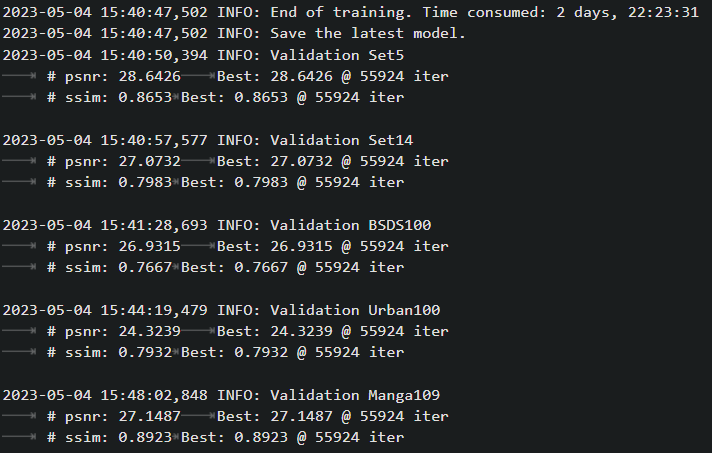
使用non-dist多卡训练好像就有这个问题,换成dist多卡训练就好了 但不太清楚non-dist和dist这两种多卡训练有什么区别。。。感觉non-dist多卡像是把总的iters均分给每块gpu