Allow more parallel work in dead argument eliminiation
Take more advantage of DAEScanner threading by aggregating calls to function as they are scanned opposed to tracking the calls a function makes and then aggregating in another pass. This does introduce a mutex, but with larger binaries that merging after the scan is a large portion of the time
Building on #4629
Before:
[PassRunner] running pass: dae-optimizing... 39.9249 seconds.
After:
[PassRunner] running pass: dae-optimizing... 20.1887 seconds.
@kripken When i am running the fuzzer on this branch i am receiving
You found a bug in the fuzzer itself! It failed to generate a valid wasm file
from the random input. Please report it with
seed: 14163501195477415117
Using Python 3.7.5
That error (You found a bug in the fuzzer itself! It failed to generate a valid wasm file) can be ignored. Not sure why it's started happening just today, but I've seen it too. Hopefully #4642 fixes it.
i am still hitting the bug in the fuzzer but less frequent
10616326470480632236
1630626949815546522
3487257774816750057
I think the fuzzer is finding something with this branch as well, looking into that now, not seeing it with main
This does introduce a mutex, but with larger binaries that merging after the scan is a large portion of the time
That surprises me - do you know why that is? The number of calls in a module is usually not that high (for every call there are many other instructions around it), so I wouldn't expect us to be merging large amounts of data here. I wouldn't ask if the change here were obviously better, but as it switches one tradeoff (merging) to another (mutex) I think it might be good to understand the overhead here better.
I think the reason is with what i am testing is there are 130k functions, and so doing a big merge at the end is where i was seeing a lot of the overhead. I don't think the lock contention is very high with that many functions, especially since the lock isn't for every function but rather for a specific function. I also tried a spin wait which did prove to be quicker since the operations are very quick and reduces the lock overhead. I just went the safe route and put the mutex in and to avoid pitfalls of a spin wait
I am probably going to need to abandon both my of changes for a while as i have some other priorities coming up and then is chewing up my time since i am ramping up on some of this
I think the reason is with what i am testing is there are 130k functions, and so doing a big merge at the end is where i was seeing a lot of the overhead.
Hmm, I'd still expect most of those 130k functions to have few calls in them, so the time spent on them in the merge code should be almost 0..? But maybe I'm missing something.
In any case, you're probably right if that's what you measure. If it's faster for you, and we don't see a slowdown on small modules (which is very likely the case) then sounds good to me.
I am probably going to need to abandon both my of changes for a while as i have some other priorities coming up
Got it, thanks for the update. Whenever you have time for it, I think these would be good changes to get in - you've found some large speedup opportunities on very large modules, which is an important case to optimize for (which I guess we haven't done enough for, yet).
@kripken Just to make sure we are talking about the same thing the "merge" is the following code.
// Combine all the info.
std::map<Name, std::vector<Call*>> allCalls;
for (auto& [_, info] : infoMap) {
for (auto& [name, calls] : info.calls) {
auto& allCallsToName = allCalls[name];
allCallsToName.insert(allCallsToName.end(), calls.begin(), calls.end());
}
for (auto& [name, calls] : info.droppedCalls) {
allDroppedCalls[name] = calls;
}
}
Currently the scanner only tracks the calls from a specific function, once all the thread are complete that information is transformed into the final data structure which is what are all the calls to each function.
My change is adjusting that so as we find function calls we put it in the final desired structure which is what are all the call sites to a function, By doing so this way it does create a race conditions on the data structure if two threads each try to add a call site to a specific function at once. The advantage where is we get to build that final structure in parallels, and the lock contention per function is very low because as you mention I'd still expect most of those 130k functions to have few calls in them,
Also since #4629 was rolled back, I attempted to fix that issue, i have a proposed solution, but i am struggling to understand the exact issue, so i am not totally sure it will fix all. I tried running the emscripten test deck i sort of stumbled on a potential solution. Coincidentally without these changes to process the information more in parallel, the performance is worse. So breaking out 4692 probably doesn't make sense anymore without the fully optimized changes
Just to make sure we are talking about the same thing the "merge" is the following code.
Yes, exactly, that code. I'm surprised it would take a large amount of time, unless there is some slow hashing or other operation there.
Running on clang.wasm, which is 35MB, each merge operation takes much less than 1 second. A UE4 game I have of 46MB is slightly faster than that. The slowest I can find is the Qt soffice app, 209MB of wasm (!), and that takes almost 1 second per merge. So at least on those, I don't see the merge is being very slow, although we do run multiple iterations - so perhaps the difference in your case is the number of iterations? I see something like 10 iterations on those. If your case has a lot more then perhaps just capping that limit makes sense.
@kripken What is the total runtime of those wasm files with and without my change? I realize there is still an issue to work out but curious if the net change in time
One theory is my library has some boost spirit which is very templated and can result in large class and function names which could play into the hashing theory
side note spirit can also lead to very deep call stacks
With the change I see something like a 30% speedup on --dae, which is good. However, the benefit is smaller with --dae-optimizing (which also optimizes each time). On another codebase though, j2wasm, which is 14MB I see a 6% slowdown. So this PR seems promising, but it's slightly mixed.
Other quick measurements show that reducing the number of iterations is an easy way to make this faster. Later iterations do less important things, usually, so it may be the right tradeoff. Perhaps we could limit the iterations in -O2 but not -O3 for example.
The larger issue is that we rescan the entire module in each cycle, even functions that we do not change. That could be a much larger speedup, I expect, as the changes we make are usually not widespread.
I agree about the iterations, my hesitation with just capping it is two fold.
One since we can only apply all dead argument removal or return value removal in one iteration, there is a chance that all we end up doing in those iterations is remove dead arguments. This problem would be addressed if I could land #4629 , unfortunately i am able to fix some of the issue but i just uncover other things, with my trial and error approach to fixing it.
- In my wasm currently it takes 36 total iterations, return values aren't removed until iteration 26, With 4629 we only need 25 total iterations
TBD since there are bugs :)
The second issue is probably more theoretical than practical, I am thinking there could be cases that as parameters remove and return values are dropped as we move up the call tree the gains could get bigger because the propagation would spread to more calls upstream. That would be something that maybe isn't that practical but is possible.
The larger issue is that we rescan the entire module in each cycle, even functions that we do not change. That could be a much larger speedup, I expect, as the changes we make are usually not widespread.
This is exactly what my original approach that i attempted, and have attempted it recently as well. My thoughts were
- full module scan
- Remove params / drop returns (probably needs #4629)
- Optimize
- For each parent function of call sites that were adjusted, rechecked used params and return value.
- If we find any unused params or return values GOTO step 2.
- else potentially GOTO step 1. (not sure this would actually bare any fruit so could be omitted)
Finally i am going to grab the distribution of function name length in my library that the DAE passes see, i am wondering if that does effect the hashing since large string hashing will be more expensive. One way to prevent this could maybe to be strip the debug first before optimizing... ? I can test this theory as well
This surprised me but there are some extremely long function names. Some in the hundreds of thousands
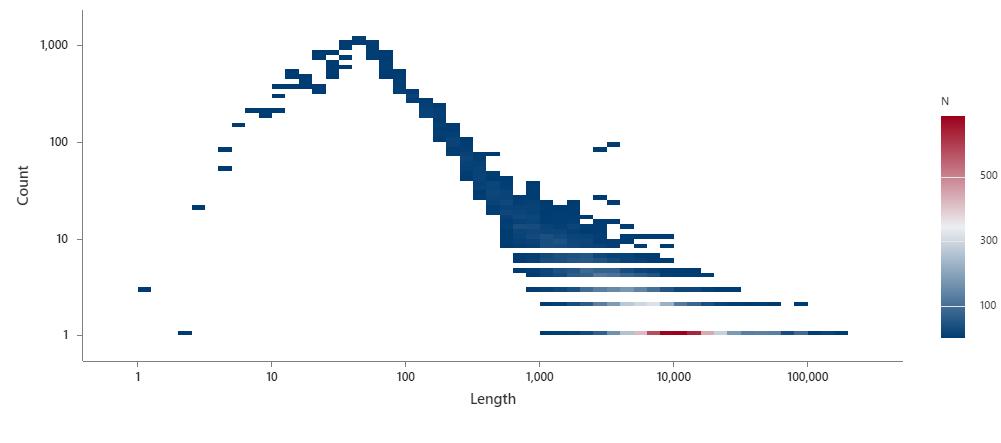
If i strip the debug information out and let the optimizer work without having the full names. This is the function name lengths
Length Count
11 92
10 90
9 10
6 100755
5 26421
4 3879
3 697
2 81
1 10
Here is a comparison optimizer running with debug information(419MB) and with debug information stripped(38.6MB) first
With Debug
[PassRunner] running passes
[PassRunner] running pass: duplicate-function-elimination... 14.9919 seconds.
[PassRunner] running pass: memory-packing... 0.368626 seconds.
[PassRunner] running pass: once-reduction... 0.279827 seconds.
[PassRunner] running pass: ssa-nomerge... 8.43582 seconds.
[PassRunner] running pass: dce... 2.71033 seconds.
[PassRunner] running pass: remove-unused-names... 0.422292 seconds.
[PassRunner] running pass: remove-unused-brs... 2.36642 seconds.
[PassRunner] running pass: remove-unused-names... 0.411341 seconds.
[PassRunner] running pass: optimize-instructions... 1.83179 seconds.
[PassRunner] running pass: pick-load-signs... 0.589166 seconds.
[PassRunner] running pass: precompute... 1.18663 seconds.
[PassRunner] running pass: optimize-added-constants-propagate... 19.1788 seconds.
[PassRunner] running pass: code-pushing... 0.872877 seconds.
[PassRunner] running pass: simplify-locals-nostructure... 4.52711 seconds.
[PassRunner] running pass: vacuum... 4.38618 seconds.
[PassRunner] running pass: reorder-locals... 0.641371 seconds.
[PassRunner] running pass: remove-unused-brs... 1.76588 seconds.
[PassRunner] running pass: coalesce-locals... 4.1686 seconds.
[PassRunner] running pass: local-cse... 2.27638 seconds.
[PassRunner] running pass: simplify-locals... 5.32231 seconds.
[PassRunner] running pass: vacuum... 3.72094 seconds.
[PassRunner] running pass: reorder-locals... 0.595884 seconds.
[PassRunner] running pass: coalesce-locals... 4.03779 seconds.
[PassRunner] running pass: reorder-locals... 0.612997 seconds.
[PassRunner] running pass: vacuum... 3.65364 seconds.
[PassRunner] running pass: code-folding... 1.46624 seconds.
[PassRunner] running pass: merge-blocks... 0.945553 seconds.
[PassRunner] running pass: remove-unused-brs... 1.86604 seconds.
[PassRunner] running pass: remove-unused-names... 0.395657 seconds.
[PassRunner] running pass: merge-blocks... 0.858571 seconds.
[PassRunner] running pass: precompute... 1.07304 seconds.
[PassRunner] running pass: optimize-instructions... 1.73007 seconds.
[PassRunner] running pass: rse... 4.40189 seconds.
[PassRunner] running pass: vacuum... 3.34757 seconds.
[PassRunner] running pass: dae-optimizing... 55.2779 seconds.
[PassRunner] running pass: inlining-optimizing... 17.7029 seconds.
[PassRunner] running pass: duplicate-function-elimination... 1.21331 seconds.
[PassRunner] running pass: duplicate-import-elimination... 0.0309795 seconds.
[PassRunner] running pass: simplify-globals-optimizing... 0.223707 seconds.
[PassRunner] running pass: remove-unused-module-elements... 0.740021 seconds.
[PassRunner] running pass: directize... 0.0859641 seconds.
[PassRunner] running pass: generate-stack-ir... 0.552758 seconds.
[PassRunner] running pass: optimize-stack-ir... 11.0822 seconds.
[PassRunner] running pass: strip-dwarf... 0.375781 seconds.
[PassRunner] running pass: post-emscripten... 0.639791 seconds.
[PassRunner] running pass: strip-debug... 0.0253184 seconds.
[PassRunner] running pass: strip-producers... 0.0135212 seconds.
[PassRunner] passes took 193.404 seconds.
No Debug
[PassRunner] running passes
[PassRunner] running pass: duplicate-function-elimination... 13.9025 seconds.
[PassRunner] running pass: memory-packing... 0.380054 seconds.
[PassRunner] running pass: once-reduction... 0.296989 seconds.
[PassRunner] running pass: ssa-nomerge... 8.36684 seconds.
[PassRunner] running pass: dce... 2.61591 seconds.
[PassRunner] running pass: remove-unused-names... 0.424185 seconds.
[PassRunner] running pass: remove-unused-brs... 2.36245 seconds.
[PassRunner] running pass: remove-unused-names... 0.417089 seconds.
[PassRunner] running pass: optimize-instructions... 1.79819 seconds.
[PassRunner] running pass: pick-load-signs... 0.578632 seconds.
[PassRunner] running pass: precompute... 1.17347 seconds.
[PassRunner] running pass: optimize-added-constants-propagate... 15.3037 seconds.
[PassRunner] running pass: code-pushing... 0.802933 seconds.
[PassRunner] running pass: simplify-locals-nostructure... 4.22882 seconds.
[PassRunner] running pass: vacuum... 3.53519 seconds.
[PassRunner] running pass: reorder-locals... 0.601484 seconds.
[PassRunner] running pass: remove-unused-brs... 1.6635 seconds.
[PassRunner] running pass: coalesce-locals... 3.71014 seconds.
[PassRunner] running pass: local-cse... 2.03246 seconds.
[PassRunner] running pass: simplify-locals... 4.94412 seconds.
[PassRunner] running pass: vacuum... 3.26723 seconds.
[PassRunner] running pass: reorder-locals... 0.553454 seconds.
[PassRunner] running pass: coalesce-locals... 3.15231 seconds.
[PassRunner] running pass: reorder-locals... 0.541218 seconds.
[PassRunner] running pass: vacuum... 3.18846 seconds.
[PassRunner] running pass: code-folding... 1.26198 seconds.
[PassRunner] running pass: merge-blocks... 0.903362 seconds.
[PassRunner] running pass: remove-unused-brs... 1.83269 seconds.
[PassRunner] running pass: remove-unused-names... 0.392195 seconds.
[PassRunner] running pass: merge-blocks... 0.842431 seconds.
[PassRunner] running pass: precompute... 1.05346 seconds.
[PassRunner] running pass: optimize-instructions... 1.57928 seconds.
[PassRunner] running pass: rse... 3.37757 seconds.
[PassRunner] running pass: vacuum... 3.18092 seconds.
[PassRunner] running pass: dae-optimizing... 49.5336 seconds.
[PassRunner] running pass: inlining-optimizing... 16.8868 seconds.
[PassRunner] running pass: duplicate-function-elimination... 1.2011 seconds.
[PassRunner] running pass: duplicate-import-elimination... 0.0232897 seconds.
[PassRunner] running pass: simplify-globals-optimizing... 0.213803 seconds.
[PassRunner] running pass: remove-unused-module-elements... 0.646562 seconds.
[PassRunner] running pass: directize... 0.0983739 seconds.
[PassRunner] running pass: generate-stack-ir... 0.543641 seconds.
[PassRunner] running pass: optimize-stack-ir... 8.79893 seconds.
[PassRunner] running pass: strip-dwarf... 0.359053 seconds.
[PassRunner] running pass: post-emscripten... 0.618734 seconds.
[PassRunner] running pass: strip-debug... 0.0239753 seconds.
[PassRunner] running pass: strip-producers... 0.0137845 seconds.
[PassRunner] passes took 173.227 seconds.
In my wasm currently it takes 36 total iterations, return values aren't removed until iteration 26
Interesting! That's more than any codebase I've tested on, which might explain the differences.
Also, that return values aren't removed until late is interesting. I was probably wrong in assuming later iterations matter less - important work could happen any time, as you were saying.
Finally i am going to grab the distribution of function name length in my library that the DAE passes see, i am wondering if that does effect the hashing since large string hashing will be more expensive.
This shouldn't be an issue. We intern string names as we load the module, and then hashing a function name is hashing the pointer to the interned string, so it's all constant time. Perhaps the total difference in the last two measurements is the startup time, actually - the per-pass data seems not much changed.
(Although, it's very interesting there are such long names...!)