Missing reference paper that has better results on `Human3.6M` than `MHFormer`?
The paper "Occlusion-Aware Networks for 3D Human Pose Estimation in Video"[1] published in ICCV 2019 achieves 42.9 MPJPE(protocol 1) and 32.8 P-MPJPE(protocol 2) while your paper[2] achieves 43.0 MPJPE and 30.5 P-MPJPE. While MHFormer claim state-of-the-art performance on Human3.6M 3D pose estimation, their method seem to outperform MHFormer. It seems that your paper doesn't compare against their results. If I'm haven't mistaken, [1] is not listed in the reference.
Both tables seem to compare performance in the same setting(monocular 3d pose estimation) and also since they both show same numbers for [3], as underlined in red.
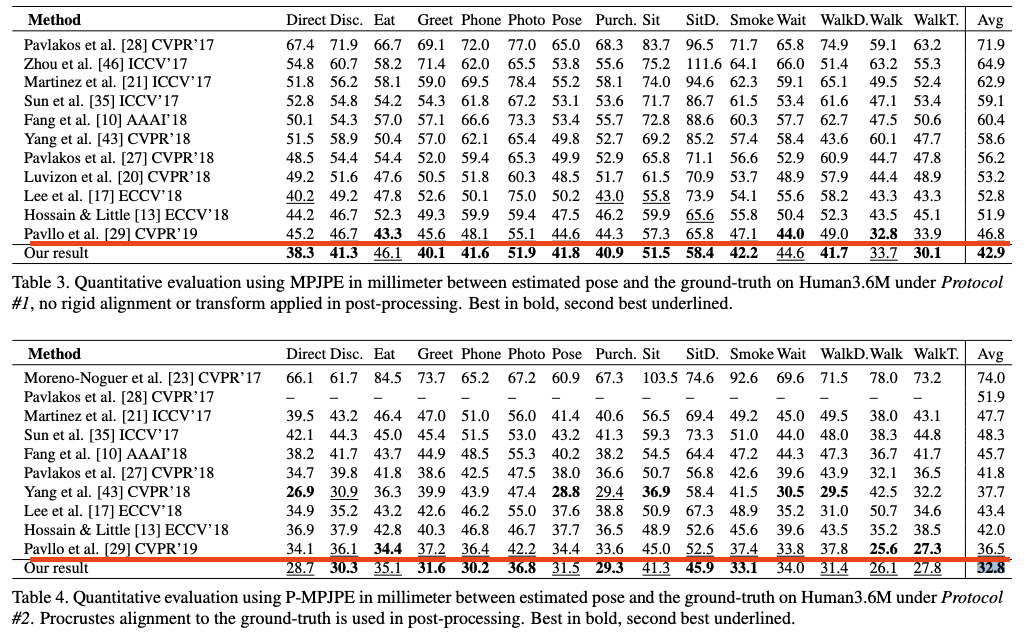
↑ Table from [1]
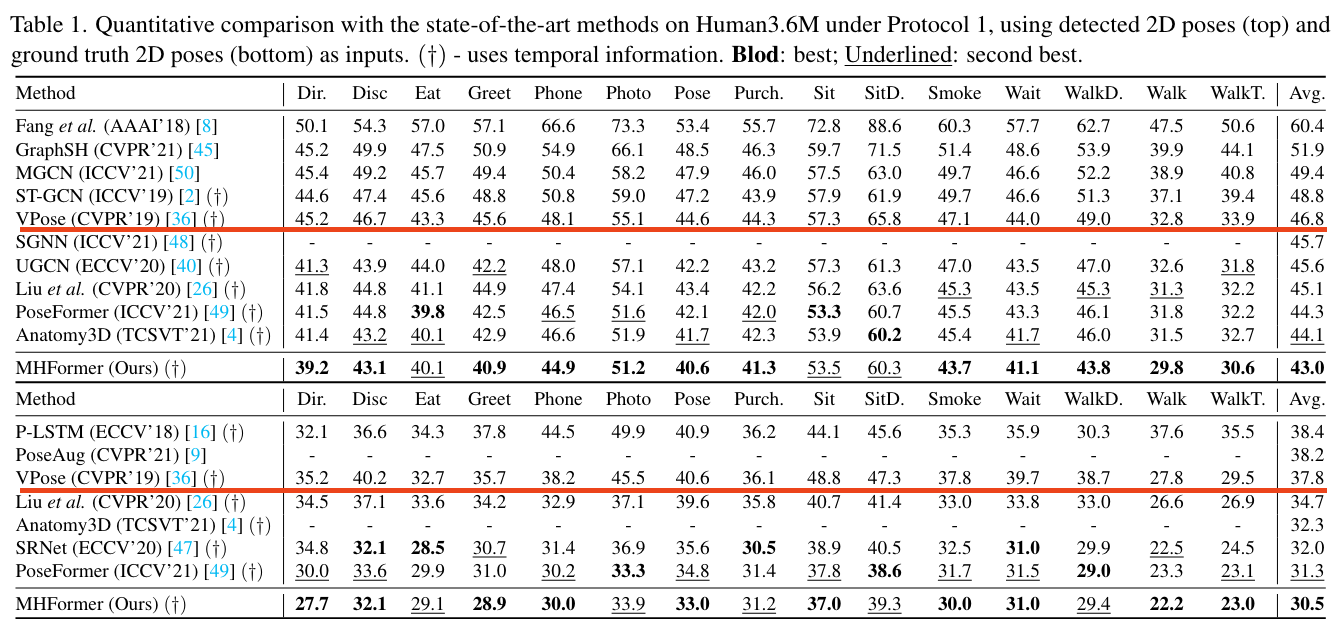
↑ Table from your paper[2]
I think your paper should be revised so that it contain comparisons against [1]. Please correct me if I misunderstood something.
[1] Cheng, Y., Yang, B., Wang, B., Yan, W., & Tan, R. T. (2019). Occlusion-aware networks for 3d human pose estimation in video. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 723-732).
[2] Li, W., Liu, H., Tang, H., Wang, P., & Van Gool, L. (2022). Mhformer: Multi-hypothesis transformer for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13147-13156).
[3] Pavllo, D., Feichtenhofer, C., Grangier, D., & Auli, M. (2019). 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7753-7762).