ENH: Annotation Storage Additions For Visualization
This PR adds some enhancements to storage.py that are useful when using an AnnotationStore for visualization purposes.
Main changes:
Support for adding annotations from a hovernet-style .dat through a utility function
Addition of 'area' field to table in SQliteStore. Annotations are returned sorted by area, and supports querying for annotations satisfying an area threshold, useful for zoomed-out rendering where annotations which are too small to display can be excluded. After the discussions in tiatoolbox meeting, functions are added to allow to add/remove the area column to save space if its not expected to be needed. Sorting annotations efficiently by area (can create an index on it) allows to effficiently deal with potentially overlapping annotations by drawing geometries of smallest area last. Eg
Unsorted rendering:
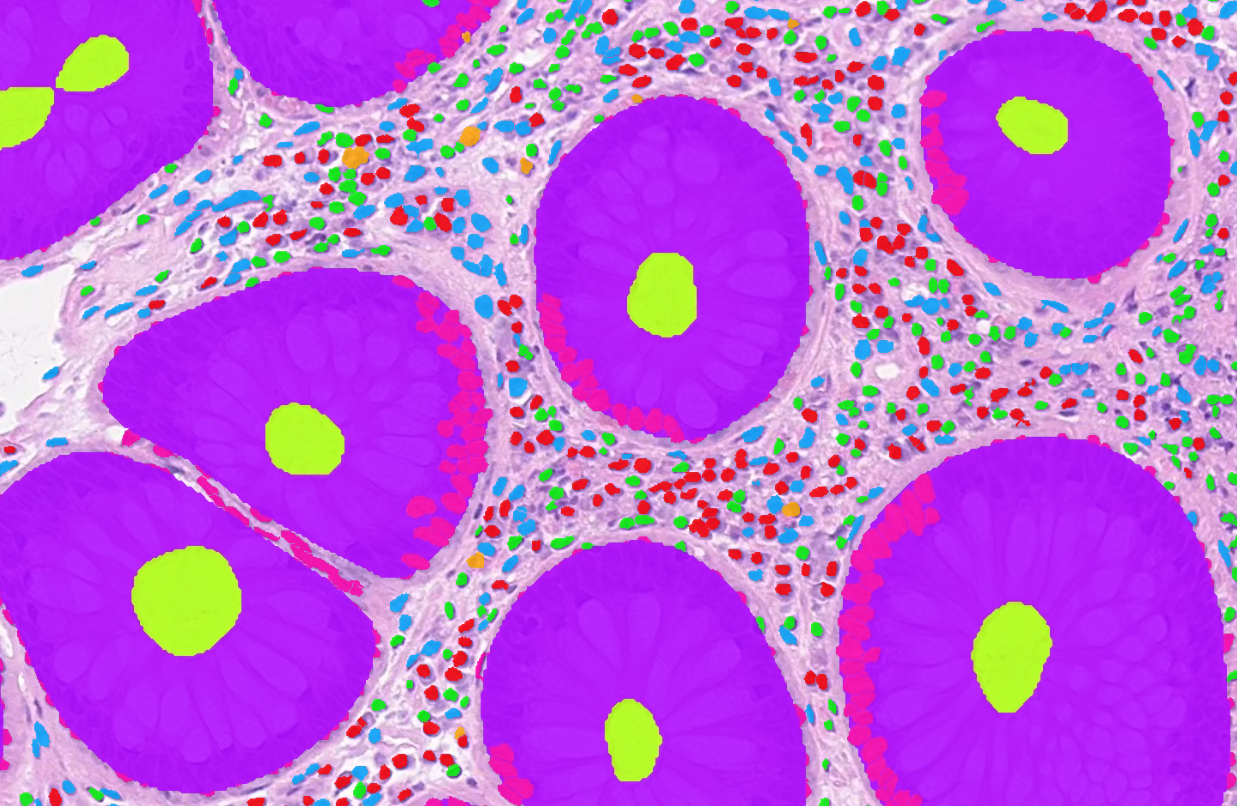
Sorted rendering:
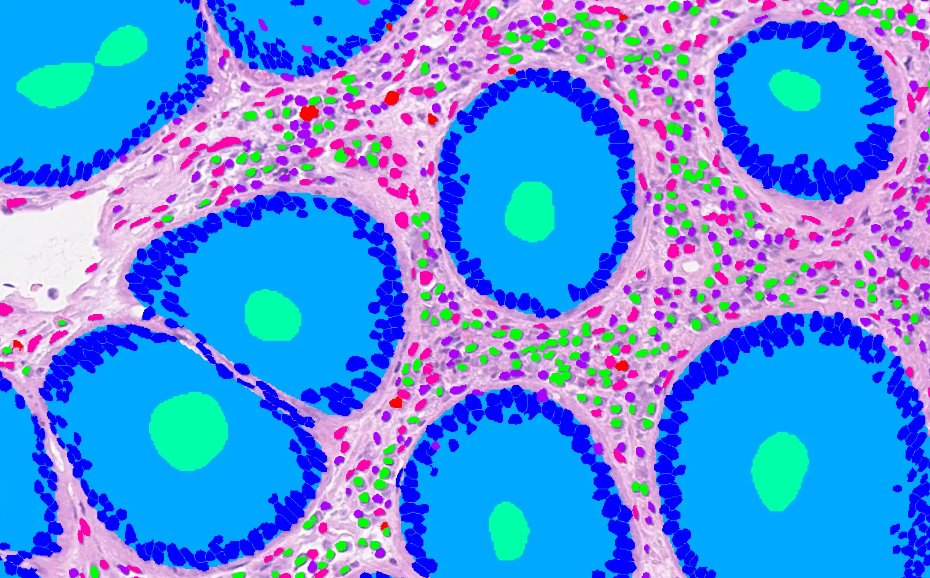
~~Addition of cacheable versions of query, bquery. The intention with these is to potentially be more efficient when viewing the same area of screen and modifying various options controlling how annotations are rendered (perhaps changing color mapping, or deselecting objects of specific types to be renderered). As in these cases we are displaying the same annotations just in a different way, we dont need to re-load all the annotations for each tile from the store; we can just load the cached annotations and then filter/render them differently. Still needs a bit of testing to see how much this actually helps/if its worth using~~ (caching aspects of the PR removed for now after feedback, may revisit this later in a separate PR)
Codecov Report
Merging #445 (963d931) into develop (b0d5981) will increase coverage by
0.03%. The diff coverage is100.00%.
@@ Coverage Diff @@
## develop #445 +/- ##
===========================================
+ Coverage 99.58% 99.62% +0.03%
===========================================
Files 61 61
Lines 6061 6163 +102
Branches 972 1026 +54
===========================================
+ Hits 6036 6140 +104
+ Misses 13 10 -3
- Partials 12 13 +1
| Impacted Files | Coverage Δ | |
|---|---|---|
| tiatoolbox/annotation/storage.py | 99.87% <100.00%> (+0.28%) |
:arrow_up: |
| tiatoolbox/utils/misc.py | 100.00% <100.00%> (ø) |
|
| tiatoolbox/tools/registration/wsi_registration.py | 99.31% <0.00%> (-0.69%) |
:arrow_down: |
| tiatoolbox/utils/image.py | 100.00% <0.00%> (ø) |
|
| tiatoolbox/wsicore/metadata/ngff.py | 100.00% <0.00%> (+3.03%) |
:arrow_up: |
:mega: We’re building smart automated test selection to slash your CI/CD build times. Learn more
I will have to provide longer feedback in future, but just making a few quick notes before our meeting. I have a few concerns:
- I don't think it wise to add more columns to the database. When doing the extensive analysis and use case argument for using this SQLite store, storage space was a big concern, especially with large sets of annotations. I would suggest using a temporary table to keep areas (and other region props) for visualization purposes. This will compute them once when the database is opened and not write them to disk, taking up more space. Alternatively, you could use the bounding box area, which can be obtained in a select statement from the rtree index already without the need to extra columns. Additionally, I think that area might be calculated already when the WKB is parsed. Have you checked this? I.e. does it offer any speedup to have this saved somehwere vs obtaining it from the shapely object?
- Beware caching. It can be full of pitfalls from memory leaks to cache invalidation issues. The built-in functools LRU cache has been known to have issues with memory leaks. I would suggest moving this up the stack out of the storage class itself and into the visualization layer also. There is the issue of if someone updates the database from another process. How does this get propagated etc.
- Dat is a very generic format. Calling it
from_datis confusing as it is specific to our toolbox / hovernet rather than being able to use any dat file. Perhapsfrom_hovernet_datwould be better. Also, this adds the first tight coupling between the annotation store and another part of the toolbox. I think we should avoid this. Especially, if annotation store is to be broken out into a separate package in the future. I can't think of an elegant solution right now but perhaps some loader function which takes a store and a dat file to load into the database would be better than baking it into the storage class to avoid this coupling for now.
I will have to provide longer feedback in future, but just making a few quick notes before our meeting. I have a few concerns:
- I don't think it wise to add more columns to the database. When doing the extensive analysis and use case argument for using this SQLite store, storage space was a big concern, especially with large sets of annotations. I would suggest using a temporary table to keep areas (and other region props) for visualization purposes. This will compute them once when the database is opened and not write them to disk, taking up more space. Alternatively, you could use the bounding box area, which can be obtained in a select statement from the rtree index already without the need to extra columns. Additionally, I think that area might be calculated already when the WKB is parsed. Have you checked this? I.e. does it offer any speedup to have this saved somehwere vs obtaining it from the shapely object?
- Beware caching. It can be full of pitfalls from memory leaks to cache invalidation issues. The built-in functools LRU cache has been known to have issues with memory leaks. I would suggest moving this up the stack out of the storage class itself and into the visualization layer also. There is the issue of if someone updates the database from another process. How does this get propagated etc.
- Dat is a very generic format. Calling it
from_datis confusing as it is specific to our toolbox / hovernet rather than being able to use any dat file. Perhapsfrom_hovernet_datwould be better. Also, this adds the first tight coupling between the annotation store and another part of the toolbox. I think we should avoid this. Especially, if annotation store is to be broken out into a separate package in the future. I can't think of an elegant solution right now but perhaps some loader function which takes a store and a dat file to load into the database would be better than baking it into the storage class to avoid this coupling for now.
- I have changed the area column to an interger to save space, as that is sufficient for what is needed. The impact of the additional column on filesize is around 3-4%. My concerns with the alternate solutions are that BBox area is not sufficient, as that gives a large area to line annotations, which really need their correct zero area as they will show up well plotted over a region annotation, but not vice-versa. And the temporary table solution, I am concerned that calculating the area of all annotations and creating an index on it on load will lengthen the already noticable delay on opening a new store. My first attempt at using area originally had all the filtering/sorting by area outside of the storage class, I moved it into the db as its more efficient to have it there so that you can have an index on it, and so area constraints can be incorporated directly in the query so that you dont even return from the database the annotations you dont plan to render.
- I've removed the cached querys for now, can potentially rethink how its done later.
- I've moved the code to create a store from hovernet style .dat into a standalone function in tiatoolbox\utils\misc.py
I've added functions to add/drop the area column as discussed. Also finished adding tests, so marked it as ready for review.
@measty It has since occurred to me that we may need to add a column for annotation type (e.g. an integer which corresponds to an enum) for filtering annotations etc. This could also be used instead of / as a fallback for area. E.g points/lines get 0 (no computation needed) and polygons get bounding box from the rtree at query. This should be very fast as it is a simple multiplication performed by the query engine. It may in fact be more performant than using the actual area on cold startup (because calculating actual area is slow vs fast bounding box) and may have negligible difference for warm queries also. Can we benchmark this?
If you still want the actual area, the bounding box could be used if the area column is missing at start up (or first query) to reduce lag time. Meanwhile, in the background you could perform a query to add the missing column to avoid start up lag. However, we may find that this combo of annotation type + bounding box is enough.
Thanks @measty. Please can you address the comments? @shaneahmed the docstring-related comments have been addressed
@measty It has since occurred to me that we may need to add a column for annotation type (e.g. an integer which corresponds to an enum) for filtering annotations etc. This could also be used instead of / as a fallback for area. E.g points/lines get 0 (no computation needed) and polygons get bounding box from the rtree at query. This should be very fast as it is a simple multiplication performed by the query engine. It may in fact be more performant than using the actual area on cold startup (because calculating actual area is slow vs fast bounding box) and may have negligible difference for warm queries also. Can we benchmark this?
If you still want the actual area, the bounding box could be used if the area column is missing at start up (or first query) to reduce lag time. Meanwhile, in the background you could perform a query to add the missing column to avoid start up lag. However, we may find that this combo of annotation type + bounding box is enough.
@John-P I tried adding a custom function:
def get_area_approx(objtype, min_x, min_y, max_x, max_y):
"""Function to get the approx. area of a geometry."""
if objtype in ("Point", "LineString"):
return 0
return (max_x - min_x) * (max_y - min_y)
And using that for the area based sorting/filtering. I did a small bit of benchmarking, rendering all the possible tiles in the generator, and just the first 50 to simulate its effect after initial load. All tiles: 279s using above function, 275s using area column First 50: 4.7s using above fn, 3.06 using area column.
So, it seems to be a reasonable fallback, and doesn't degrade performance much apart from a bit of a hit to the initial lag.
One thing to note is that if any changes are being made to the table schema, this must be done carefully to avoid breaking things too much. E.g. we need:
- To document changes in the docstring(s).
- To increment the version number which is written to the database.
- To add checks for version number when reading a database.
- Handle old versions / ask user if they want to upgrade the database.
Just copying over comments here from our last team chat, If we change the type column to be an int/enum instead of text then this would be a breaking change. However, it could be a significant space-saving and hopefully more than account for adding a true area column if this is required. By using the type, we can also get a pseudo area, i.e. 0 for lines and points and the bounding-box area for polygons which may be useful if trying to keep the on disk storage footprint low. Additionally, we could probably remove the cx and cy columns. They are currently used to store a 'representative point', i.e. a point near the center of mass but within the shape. We are currently not using this. Additionally, a bounding box center point can be obtained from the rtree index.
EDIT: We could also further improve the storage of UUIDs by using multiple int columns instead of one text column. However, this would make it harder to use custom string keys.
I am just making note of all the potential changes that we might want to make to the DB schema as making multiple changes at a later date will blow up the complexity of handling different versions. It would be easier to make and handle any changes we want in one batch.
I've make a few comments / suggestions of things. Mostly just suggesting alternative naming for things.
All the comments have been addressed now, I think