有支持多轮对话finetune的实现吗?
你把prompt改成"这张图片里有苹果吗?\n答:有。\n问:有几个苹果?" 把label改成"有2个。" 就相当于训练了多轮对话的第二轮
明白了,所以多轮对话就是把历史的对话变成Prompt,下一轮回答变成label去训练,感谢大佬~~
但是还是有个疑问,如果是这样的形式,那么对话轮次一多,token的数量不断累加了,感觉效率上是不是太低了。
我看到的例如llava的多轮对话数据集,其实是这样的形式,是不是更合理一些?
你把prompt改成"这张图片里有苹果吗?\n答:有。\n问:有几个苹果?" 把label改成"有2个。" 就相当于训练了多轮对话的第二轮 但是还是有个疑问,如果是这样的形式,那么对话轮次一多,token的数量不断累加了,感觉效率上是不是太低了。 我看到的例如llava的多轮对话数据集,其实是这样的形式,是不是更合理一些?
https://github.com/THUDM/VisualGLM-6B/blob/f4429a009ee533b76e8757dce6917fbf0b0408f9/finetune_visualglm.py#L118-L120
<img>xxx</img>问:xxx
答:xxx
问:xxx
答:xxx
https://github.com/THUDM/VisualGLM-6B/blob/f4429a009ee533b76e8757dce6917fbf0b0408f9/finetune_visualglm.py#L118-L120
<img>xxx</img>问:xxx 答:xxx 问:xxx 答:xxx
这样还是有前面老哥提到的问题,轮数越多越复杂了
但是还是有个疑问,如果是这样的形式,那么对话轮次一多,token的数量不断累加了,感觉效率上是不是太低了。 我看到的例如llava的多轮对话数据集,其实是这样的形式,是不是更合理一些?
你把prompt改成"这张图片里有苹果吗?\n答:有。\n问:有几个苹果?" 把label改成"有2个。" 就相当于训练了多轮对话的第二轮 但是还是有个疑问,如果是这样的形式,那么对话轮次一多,token的数量不断累加了,感觉效率上是不是太低了。 我看到的例如llava的多轮对话数据集,其实是这样的形式,是不是更合理一些?
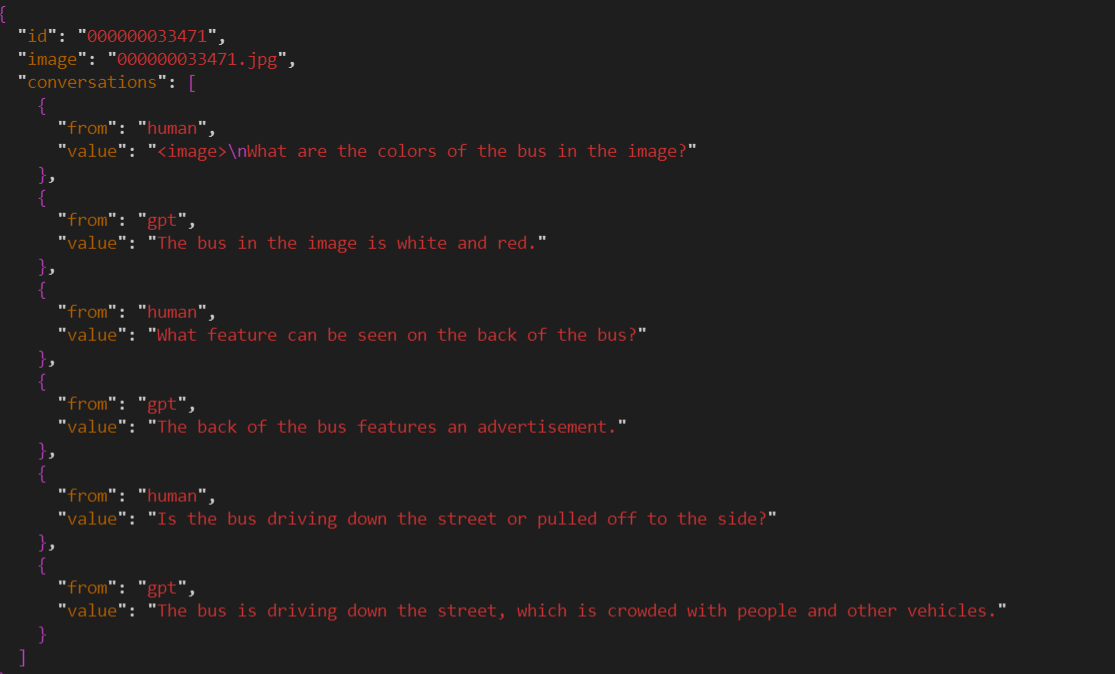
你也可以存成这种格式,数据集存成什么格式取决于你自己的~