About the pretrained model.
The training of the first layer of HCTransformer requires a lot of computational resources overhead. Limited by computing resources, I can only reproduce your results on a single Nvidia 3090 GPU , but the results are far worse than the reported. Could you please provide the pre-trained checkpoint of the HCTransformer? Thanks.
Such a good job! But could you please release the pretrained models? Thank u very much~
Thanks for your attention! Now we have provided the pre-trained weights and sample command-line instructions for evaluation. If there are any mistakes, please feel free to inform us.
Thanks for your attention! Now we have provided the pre-trained weights and sample command-line instructions for evaluation. If there are any mistakes, please feel free to inform us.
Thanks very much!
thank you for your work! i have a question about pretiained_model as follow: when i use the pretrained_model to eval the miniimagenet data,i got the acc about 72%, the result
the results are far worse than the reported,where is the problem? thank you again.
- We have updated the checkpoints_pooling, you can download it now.
- Since we train three Transformers, features extracted from them are three times larger than those in the first stage. We have reported the best performance using ONLY the features extracted from the second stage in our paper, which can be manipulated in: https://github.com/StomachCold/HCTransformers/blob/6e37cece1365a7fa6c158470195a349dd33c7d34/testCos.py#L44
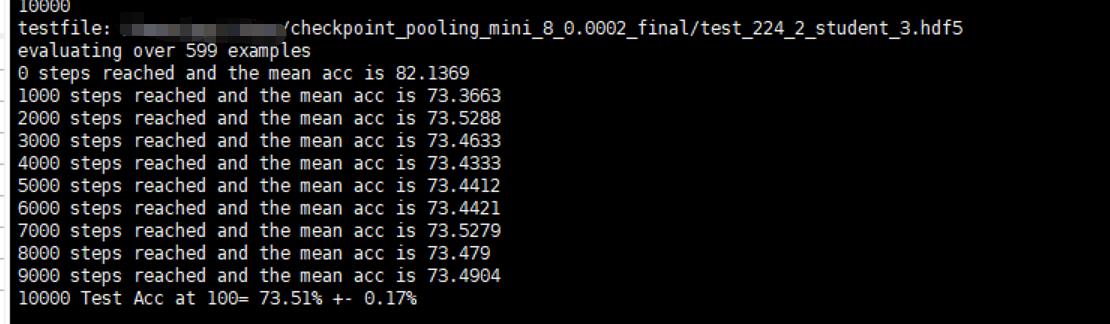
Our default implementation concatenates all features and the corresponding result is: 73.51%
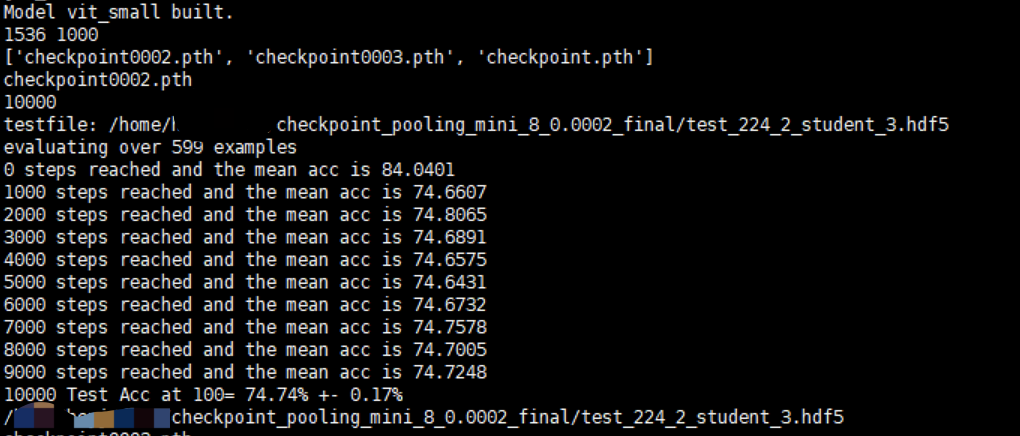
When we specify to use features extracted from the second stage, it matches the reported result in our paper: 74.74%
thank you for your work! i have a question about pretiained_model as follow: when i use the pretrained_model to eval the miniimagenet data,i got the acc about 72%, the result
- We have updated the checkpoints_pooling, you can download it now.
- Since we train three Transformers, features extracted from them are three times larger than those in the first stage. We have reported the best performance using ONLY the features extracted from the second stage in our paper, which can be manipulated in: https://github.com/StomachCold/HCTransformers/blob/6e37cece1365a7fa6c158470195a349dd33c7d34/testCos.py#L44
Our default implementation concatenates all features and the corresponding result is: 73.51%
When we specify to use features extracted from the second stage, it matches the reported result in our paper: 74.74%
thank you for your reply
Thanks for your attention! Now we have provided the pre-trained weights and sample command-line instructions for evaluation. If there are any mistakes, please feel free to inform us.
@StomachCold Thanks a lot for sharing this !!
@StomachCold 请问如何复现使用 checkpoints_pooling在mini-imagenet上5-shot的结果?
--num_shots 设5
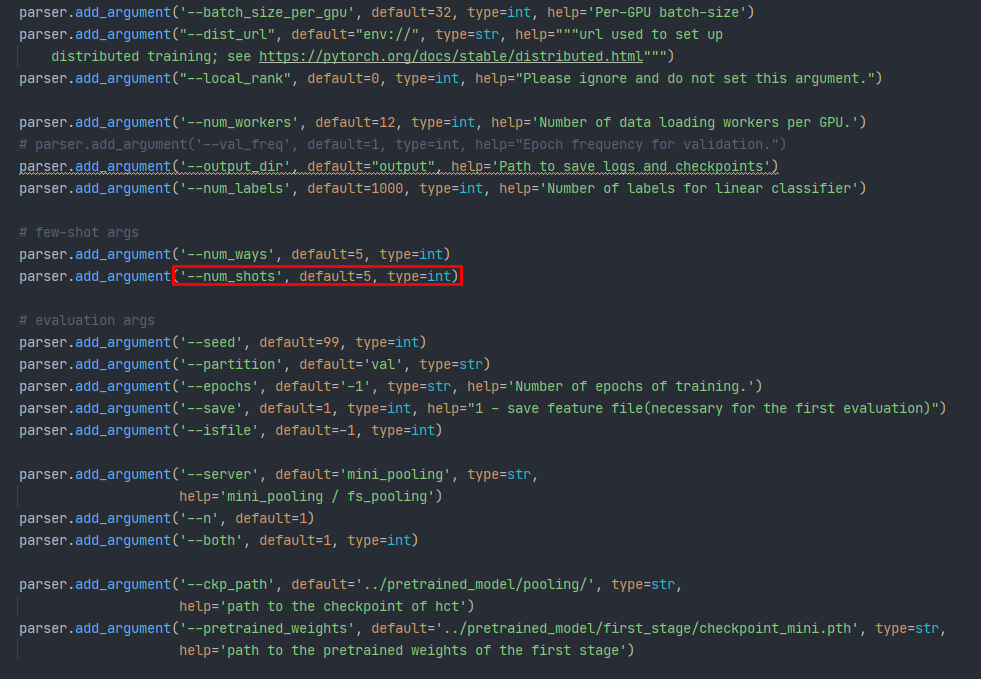
你好,参数--num_shots 设置的是5,
但是得到的结果如下:
不知道是什么原因?
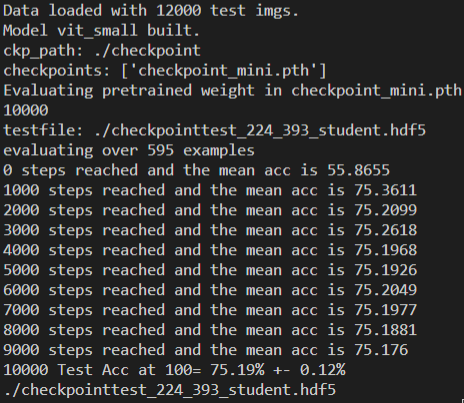
I have the same problem with you. Using the checkpoint "checkpoint_mini.pth", the 1-shot result is 60.61% ,the 5-shot result is 75.19%, which are worse than the reported. I'm sure I do not make any changes to the code and use the command lines as recommended. So strange.
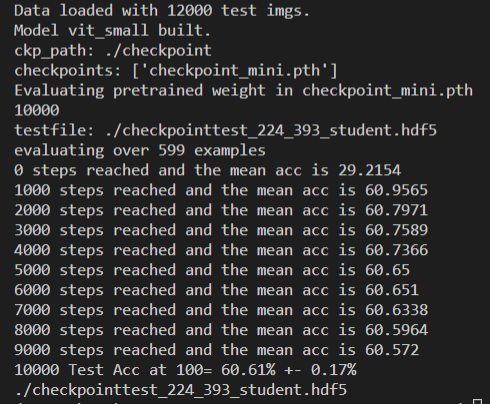
@kylewangt @Jamine-W We guess it is because the dataset you are using has an image resolution of 84, which is different from what we use (480), both for mini- and tiered-. Actually, our HCTransformers prefer to take images of the original resolution, and we resize them to 480 when generating mini- and tiered ImageNet. To reproduce our results, you may try to follow the guidelines in the Datasets Section to generate a compatible version of 𝒎𝒊𝒏𝒊ImageNet and evaluate on it. Please feel free to inform us if you have any difficulties.
@kylewangt @Jamine-W We guess it is because the dataset you are using has an image resolution of 84, which is different from what we use (480), both for mini- and tiered-. Actually, our HCTransformers prefer to take images of the original resolution, and we resize them to 480 when generating mini- and tiered ImageNet. To reproduce our results, you may try to follow the guidelines in the Datasets Section to generate a compatible version of 𝒎𝒊𝒏𝒊ImageNet and evaluate on it. Please feel free to inform us if you have any difficulties.
Thanks a lot! I changed the image resolution to 480 * 480 and it works.
Hi, thanks for the code and the paper they are really useful.
I evaluated mini-imagenet 5-ways 1-shot with the folllowing command:
python eval_hct_pooling.py --arch vit_small --server mini_pooling --partition test --checkpoint_key student --ckp_path ~/data/models/mini_pooling --pretrained_weights ~/data/models/checkpoints_first/checkpoint_mini.pth --num_shots 1
and I am getting accuracy ~1% lower than what is in the paper (73.7% vs 74.7%). This is what I did:
- cloned the repo
- downloaded the pretrained weights
- prepared mini-imagenet with size 480x480
- changed
testCos.pyto use the 2nd stage features:z_all = torch.from_numpy(np.array(z_all))[:,:,384:768] # second stage(in line 42)
Did you use seed 99 for the paper? granted, 73.7% is a very good accuracy but I'm wondering if I'm missing something