Guide
Guide
@minpeace 嘿嘿 没事👍
> Dao接口中方法是可以重载的,但是有一些限制。 > 1、无参数方法可以和有参数方法共存。guide哥文中已经写了 > 2、同为有参方法,参数数量必须一致。且使用相同的@param,或者使用param1这种 > > 下面是参数数量不同时,测试如下: > PersonDao.java > 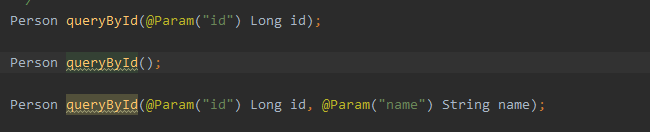 > PersonDao.xml > 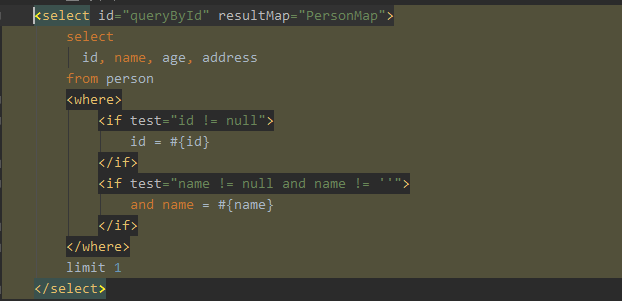 > > `queryById()`执行到DynamicContext中 > 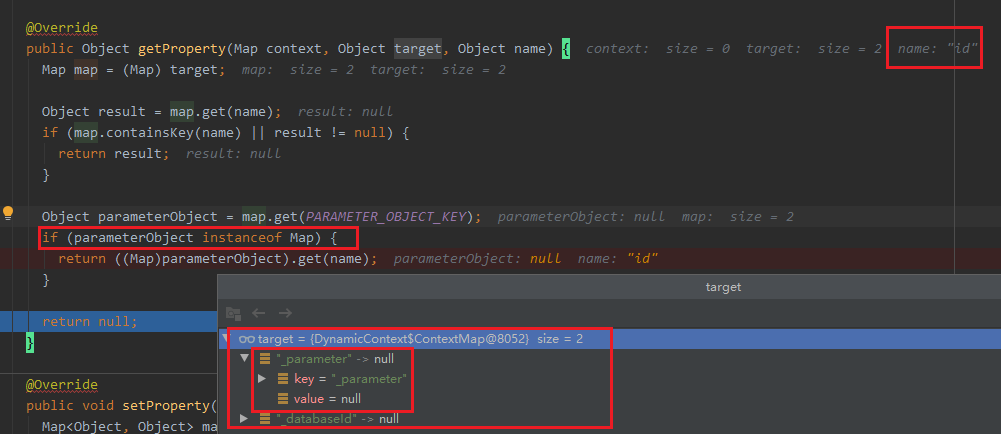 > 因为传的参数为空,所以获取到的parameterObject为空,获取到id和name值为null,标签中条件就不成立了,sql语句可以执行通过。 > > `queryById(1L)`执行到DynamicContext中,当标签获取name的参数值时 >  >...
收到建议👍
赞!老哥。加深了我对常量池的理解。
> 作者在 **JDK1.8之后** 这一小节的开头中写道: > > > JDK1.8之后再解决哈希冲突问题时有了较大的变化,**当链表长度大于阈值(默认为8)时,将链表转化为红黑树**,以减少搜索时间 > > 这段话加粗部分的描述是不准确的,当链表长度大于阈值时,会尝试调用树化方法`treeifyBin`,但这不意味着会将链表转为树: > >  > > 当我们查看树化方法`treeifyBin`(JDK1.8 HashMap源码)时,应注意到这么一行代码(757行): > >  > > 我们发现,**当哈希表的`length`小于`MIN_TREEIFY_CAPACITY` (默认为64)时,并不会真正树化,而只是执行`resize()`,也就是扩容的操作**,这一点在对树化方法`treeifyBin`以及`MIN_TREEIFY_CAPACITY` > 的注释中都有提到: > > ...
这里图片无法显示出来了,建议小伙伴可以提交一个pr
> 建议修改答案如下 > 为什么java中只有值传递: > 1.选择值传递的原因:为了保护实参,牺牲空间做值拷贝 > 2.只保留的原因:统一只用值传递,简单方便安全易懂(这个想法和取消指针不谋而和) > 注:其他语言保留引用传递的原因:方便修改实参,不用拷贝实参,节约空间时间 > (才疏学浅,欢迎斧正) 👍你好,我觉得你分享的挺有道理的!可以简单分享一下这个说法的依据不?比如相关的参考文献。
试试这个在线阅读怎么样:https://snailclimb.gitee.io/javaguide/#/
> 如题,在JDK1.7和JDK14中分别对Arrays.sort()进行了实现上的改变,在JDK1.7引入了双枢纽元快速排序,在JDK14中通过Fork&Join框架引入了多线程归并排序、多线程双枢纽元快速排序、小数组的直接插入排序和混合插入排序、相对有序数组的堆排序,实现变得越来越复杂 hi,老哥,我觉得可以,你可以尝试提一个pr给我,你觉得如何?
> 刚学习到这,有几处问题实在理解不了,希望博主不吝赐教一下: > 1、redlock 中的多个节点跟平时理解的redis的集群模式 是不是一回事呢? > 2、各个节点之间是如何同步数据的呢? 你好 这篇文章是读者投稿的,对于 RedLock实现分布式锁 这部分我的了解不多,可能需要自己详细学习一遍才能为你解答。 希望其他小伙伴知道的话可以为你解答。