Make the validation sets completely separate/not same sitting as the training data
Pulling random samples from the entire set causes over-fitting far too easily. Pulling random 10 second sessions from the sets also causes over-fitting, just to a lesser degree.
Going to try instead to make the validation set the latest n sessions, with the goal of having the validation set be a completely different day/setting as any of the training data.
hey @Sentdex . I didn't have much luck escaping over-fitting either, but I figured I'd still share my results.
I took a slightly different approach and used the average across the channel dimension, resized the resulting image to a 13x13 instead, and flattened that image for input into a mlp. Here's my notebook as a gist.
I also tried:
- averaging the matrices out over 5, 10, and 30 minute intervals; and
- fitting UMAPs to everything, but couldn't get a decent separation on either set, so I didn't include them in the gist.
Anywho, here's 5 samples after the transform for each:
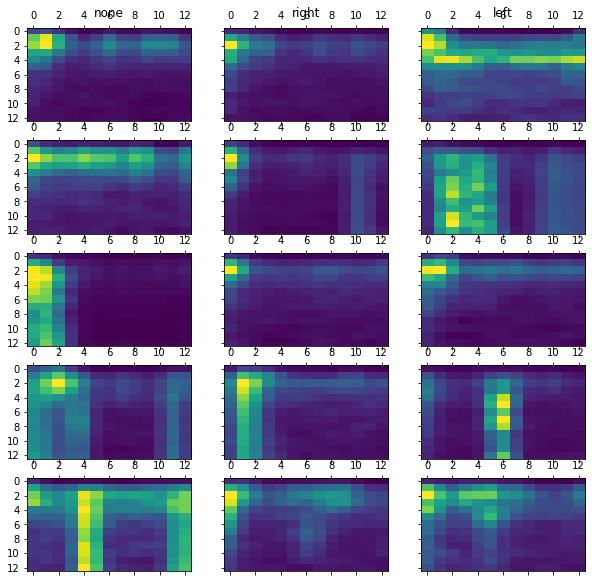
and my confusion matrices:

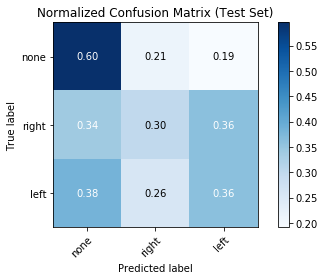
Looking forward to helping test out the next dataset iteration.
-Russell
Hello I am able to hit 70% validation accuracy on the data inside validation_data folder. You can check it out here: https://colab.research.google.com/drive/1v_vis7XpTQE0ANDoxK1Jr8_mzBFSbjF-