Dubbo的一点源码知识

Apache Dubbo™ 是一款高性能Java RPC框架,这是一句来自官方的介绍。关于RPC框架的底层原理可以参见以前我写过的一篇文章:《写一个极简的RPC》。
关于dubbo的知识点官方文档已经讲得非常透彻了,做的好的做的不好的文档都有提及,本文将从源码层面理解dubbo的几个设计核心点。
基本格式:无处不在的URL
URL作为dubbo配置信息的统一格式,这是整个框架设计的基本原则,无论是注册中心,还是提供者、消费者都以URL形式存在。
dubbo://172.18.35.230:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=dubbo-demo-api-provider&compiler=jdk&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=91615®ister=true&release=&side=provider×tamp=1568021066716
上面这段URL就是一个典型的服务提供者,通过协议(dubbo)、服务地址(172.18.35.230:20880)和若干参数表达了Provider的信息。
zookeeper://127.0.0.1:7181/org.apache.dubbo.registry.RegistryService?application=dubbo-demo-api-provider&compiler=jdk&dubbo=2.0.2&interface=org.apache.dubbo.registry.RegistryService&pid=91615×tamp=1568021061661
上面这个URL是注册中心。
核心机制:Service Provider Interface
dubbo是一个采取了Microkernel + Plugin模式的框架,提供了很多组件的扩展点,做到这种模式我们就需要设计一套加载插件的方式,这个首要的机制就是SPI。
扩展点 @SPI
dubbo的SPI借鉴了JDK的SPI,但又有些许不同:
- 按需加载扩展特性
- 友好的异常信息
- 扩展服务提供了AOP和IOC功能
不同于JDK SPI的配置,dubbo SPI配置要求为:
扩展点配置文件为 META-INF/dubbo/接口全限定名,内容为:配置名=扩展实现类全限定名,多个实现类用换行符分隔。
于是,我们在源码中可以发现大量的扩展点配置文件,我们以 org.apache.dubbo.rpc.Protocol 接口为例,它的定义如下:
package org.apache.dubbo.rpc;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.extension.Adaptive;
import org.apache.dubbo.common.extension.SPI;
/**
* Protocol. (API/SPI, Singleton, ThreadSafe)
*/
@SPI("dubbo")
public interface Protocol {
/**
* Export service for remote invocation: <br>
* 1. Protocol should record request source address after receive a request:
* RpcContext.getContext().setRemoteAddress();<br>
* 2. export() must be idempotent, that is, there's no difference between invoking once and invoking twice when
* export the same URL<br>
* 3. Invoker instance is passed in by the framework, protocol needs not to care <br>
*
* @param <T> Service type
* @param invoker Service invoker
* @return exporter reference for exported service, useful for unexport the service later
* @throws RpcException thrown when error occurs during export the service, for example: port is occupied
*/
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
/**
* Refer a remote service: <br>
* 1. When user calls `invoke()` method of `Invoker` object which's returned from `refer()` call, the protocol
* needs to correspondingly execute `invoke()` method of `Invoker` object <br>
* 2. It's protocol's responsibility to implement `Invoker` which's returned from `refer()`. Generally speaking,
* protocol sends remote request in the `Invoker` implementation. <br>
* 3. When there's check=false set in URL, the implementation must not throw exception but try to recover when
* connection fails.
*
* @param <T> Service type
* @param type Service class
* @param url URL address for the remote service
* @return invoker service's local proxy
* @throws RpcException when there's any error while connecting to the service provider
*/
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
}
Protocol的默认扩展有很多,在源码的不同maven项目(可以理解为不同jar包内部)下,可以看到有如下这些内容:
registry=org.apache.dubbo.registry.integration.RegistryProtocol
redis=org.apache.dubbo.rpc.protocol.redis.RedisProtocol
## Wrapper扩展点自动包装
filter=org.apache.dubbo.rpc.protocol.ProtocolFilterWrapper
listener=org.apache.dubbo.rpc.protocol.ProtocolListenerWrapper
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol
hessian=org.apache.dubbo.rpc.protocol.hessian.HessianProtocol
injvm=org.apache.dubbo.rpc.protocol.injvm.InjvmProtocol
注意到Protocol的接口定义,所有SPI的服务接口都是用注解@SPI("dubbo")标识,dubbo参数值表示默认的扩展名称,对应配置文件的key。
我们还注意到方法使用了注解@Adaptive标识,这就是扩展自适应功能。
扩展点自适应 @Adaptive
如何理解自适应这个概念呢?我们把它看成是运行时动态决定使用哪种扩展的方式。dubbo会在运行时对扩展服务动态生成一个代理类,这个类会在运行时动态决定使用哪一个扩展。如何动态决定扩展呢?Dubbo 使用 URL 对象(包含了Key-Value)传递配置信息,扩展点方法调用会有URL参数(或是参数有URL成员)。
我们先来看看如何获得自适应类的对象,注意它是一个单例:
private static final Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
现在的重点就是看下如何生成这样的代理类,它是通过运行时生成源码文件,然后调用编译器进行编译后生成,这里贴上生成后的代码:
package org.apache.dubbo.rpc;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class Protocol$Adaptive implements org.apache.dubbo.rpc.Protocol {
public org.apache.dubbo.rpc.Exporter export(org.apache.dubbo.rpc.Invoker arg0)
throws org.apache.dubbo.rpc.RpcException {
if (arg0 == null)
throw new IllegalArgumentException("org.apache.dubbo.rpc.Invoker argument == null");
if (arg0.getUrl() == null) throw new IllegalArgumentException(
"org.apache.dubbo.rpc.Invoker argument getUrl() == null");
org.apache.dubbo.common.URL url = arg0.getUrl();
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null) throw new IllegalStateException(
"Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url ("
+ url.toString() + ") use keys([protocol])");
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol) ExtensionLoader
.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.export(arg0);
}
public org.apache.dubbo.rpc.Invoker refer(java.lang.Class arg0,
org.apache.dubbo.common.URL arg1) throws org.apache.dubbo.rpc.RpcException {
if (arg1 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg1;
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null) throw new IllegalStateException(
"Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url ("
+ url.toString() + ") use keys([protocol])");
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol) ExtensionLoader
.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
}
从代码中读出以下关键信息:
- 类名为:Protocol$Adaptive
- 代码中会尝试从URL中获取扩展点的名称,URL可以是参数,也可以包含URL的参数,比如Invoker
- 获取到扩展点名称后,会调用对应方法加载扩展点
我们看下生成代理类的源码:
private Class<?> createAdaptiveExtensionClass() {
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}
可以看到编译器也是一个扩展点,需要使用扩展的地方都可以通过扩展机制加载。关于如何生成代理类,如何从配置文件中加载扩展类,以及如何实现扩展点AOP和IOC功能的核心源码都在ExtensionLoader类中,这里就不赘述。
领域模型
整个源码中有很多领域封装,有的领域在框架分层设计的某一个层中,有的领域贯穿整个框架。
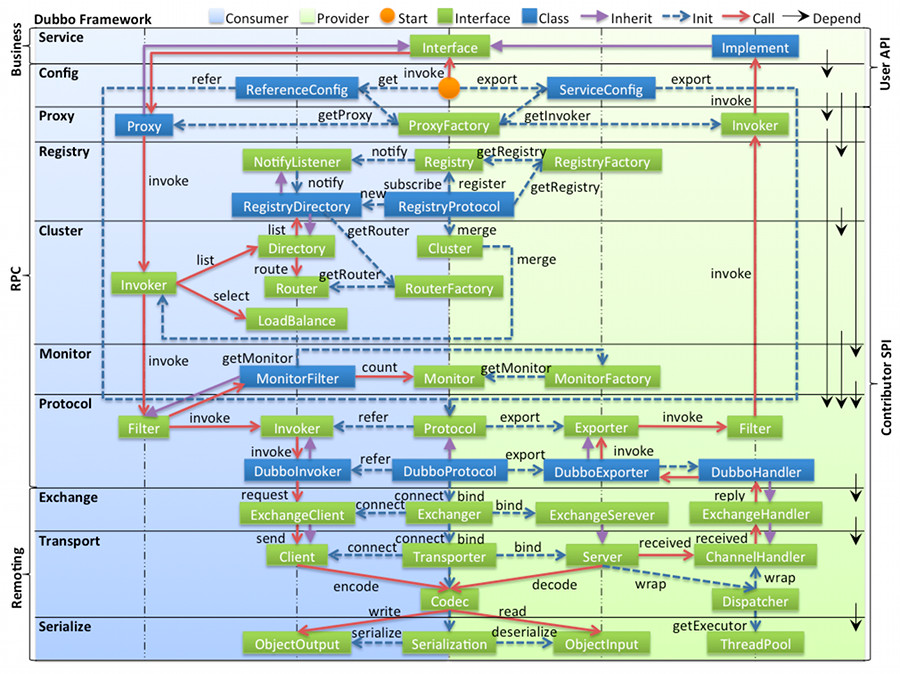
接下来我们将关注几个核心领域模型,它们分别是Protocol、Invoker、Invocation。
Protocol服务域
Protocol是服务导出和服务引入的核心领域模型,再看一次Protocol的方法:
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
这两个方法在整个dubbo的源码中是服务的核心抽象,export方法导出一个服务,refer方法引用一个服务。接口的实现关系如下:
Protocol
AbstractProtocol
DubboProtocol
InjvmProtocol
MemcachedProtocol
RedisProtocol
ThriftProtocol
RegistryProtocol
ProtocolFilterWrapper
ProtocolListenerWrapper
其中RegistryProtocol实现了注册中心相关功能,具体的DubboProtocol则实现了启动netty server和client端相关功能,关于服务导出和引入的流程请参见官网。
Invoker调用实体域
仔细观察Protocol的方法发现,无论是导出或是引入服务都有一个很重要的领域:Invoker,它代表一个可执行体,可向它发起调用。
public interface Invoker<T> extends Node {
/**
* get service interface.
*
* @return service interface.
*/
Class<T> getInterface();
/**
* invoke.
*
* @param invocation
* @return result
* @throws RpcException
*/
Result invoke(Invocation invocation) throws RpcException;
}
invoke方法代表执行一次调用返回结果。服务导出时通过代理工厂生成实例,生成Invoker的源码如下:
Invoker<?> invoker = PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, registryURL.addParameterAndEncoded(EXPORT_KEY, url.toFullString()));
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
Exporter<?> exporter = protocol.export(wrapperInvoker);
服务引入时生成Invoker经过了一些封装,我们先来看下Protocol的refer方法默认实现:
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return new AsyncToSyncInvoker<>(protocolBindingRefer(type, url));
}
AsyncToSyncInvoker是一个异步转同步的Invoker,protocolBindingRefer方法在DubboProtocol的源码如下:
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
optimizeSerialization(url);
// create rpc invoker.
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
可以看到核心的调用逻辑封装在DubboInvoker中,它会发起调用请求,并且返回一个Result结果,关于Result将会在下文的线程派发模型中进一步介绍。
在整个服务引用方调用服务链路中,dubbo还对集群容错做了一些处理,在实际引用中会对AsyncToSyncInvoker进一步的做封装,关于集群容错的默认实现类是:FailOverClusterInvoker,代表故障切换,还有一些可选容错模式:
- Failover Cluster - 失败自动切换
- Failfast Cluster - 快速失败
- Failsafe Cluster - 失败安全
- Failback Cluster - 失败自动恢复
- Forking Cluster - 并行调用多个服务提供者
FailOverClusterInvoker内部通过Directory保存了Invoker的列表,Directory能感知到注册中心Invoker的变化,我们来看下源码:
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// binding attachments into invocation.
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 获取所有的invoker
List<Invoker<T>> invokers = list(invocation);
// 初始化负载均衡策略
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
dubbo负载均衡的原理就从这里开始,进一步的知识可以继续跟进doInvoker的源码。
Invocation会话域
在Invoker实体域的方法invoke拥有一个参数,类型为Invocation,它持有调用过程中的变量,比如方法名,参数等,默认实现是RpcInvocation,底层网络通信都会对Invocation进行编码和解码。
扩展模块
本小节介绍下一些核心的扩展模块,比如网络通信模块、注册中心模块,这些模块在dubbo框架中组合了一些开源的实现方案。
Netty
Netty俨然已经成为现在Java网络通信的首选组件,它是一个高性能的异步事件驱动网络框架。
dubbo缺省采用dubbo协议,当然也是可以扩展的,比如http、hessian等。Dubbo数据包分为消息头和消息体,消息头用于存储一些元信息,比如魔数(Magic),数据包类型(Request/Response),消息体长度(Data Length)等。消息体中用于存储具体的调用消息,比如方法名称,参数列表等。
Dubbo默认使用Netty为底层通信,核心功能是建立网络连接,编解码,发送消息和接受消息。Netty的源码实现为NettyServer和NettyClient,分别对应服务端和消费端。我们看下NettyServer启动的源码:
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
bossGroup = new NioEventLoopGroup(1, new DefaultThreadFactory("NettyServerBoss", true));
workerGroup = new NioEventLoopGroup(getUrl().getPositiveParameter(IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
new DefaultThreadFactory("NettyServerWorker", true));
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// FIXME: should we use getTimeout()?
int idleTimeout = UrlUtils.getIdleTimeout(getUrl());
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))
.addLast("handler", nettyServerHandler);
}
});
// bind
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly();
channel = channelFuture.channel();
}
熟悉Netty的对这段代码应该很熟悉,这是典型的Netty服务端代码:
- 创建ServerBootstrap
- 初始化bossGroup和workGroup
- 增加编码和解码实现
- 增加消息处理器NettyServerHandler
为了做到扩展,NettyServer和NettyClient都被封装到HeaderExchangeServer和HeaderExchangeClient类,我们可以通过扩展自适应机制设置底层通信框架为netty或者mina,Exchange层的实现类为HeaderExchanger,提供了创建服务端和客户端连接服务端方法:
public class HeaderExchanger implements Exchanger {
public static final String NAME = "header";
@Override
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeClient(Transporters.connect(url, new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
@Override
public ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeServer(Transporters.bind(url, new DecodeHandler(new HeaderExchangeHandler(handler))));
}
}
Zookeeper
在RPC或者微服务中服务的管理变得尤为关键,这个时候就需要一个统一服务注册和管理的中心,Zookeeper作为一个高可用的分布式协调服务,默认成为dubbo的注册中心。
dubbo中注册中心的实现为ZookeeperRegistry,提供了注册和订阅变更的功能,它继承了FailbackRegistry类,这是一个失败自动恢复的注册中心实现,恢复的源码如下:
@Override
protected void recover() throws Exception {
// register
Set<URL> recoverRegistered = new HashSet<URL>(getRegistered());
if (!recoverRegistered.isEmpty()) {
if (logger.isInfoEnabled()) {
logger.info("Recover register url " + recoverRegistered);
}
for (URL url : recoverRegistered) {
addFailedRegistered(url);
}
}
// subscribe
Map<URL, Set<NotifyListener>> recoverSubscribed = new HashMap<URL, Set<NotifyListener>>(getSubscribed());
if (!recoverSubscribed.isEmpty()) {
if (logger.isInfoEnabled()) {
logger.info("Recover subscribe url " + recoverSubscribed.keySet());
}
for (Map.Entry<URL, Set<NotifyListener>> entry : recoverSubscribed.entrySet()) {
URL url = entry.getKey();
for (NotifyListener listener : entry.getValue()) {
addFailedSubscribed(url, listener);
}
}
}
}
这里会自动恢复注册和订阅,ZookeeperRegistry在初始化时会监听重连事件,触发恢复机制。
public ZookeeperRegistry(URL url, ZookeeperTransporter zookeeperTransporter) {
// 略
zkClient = zookeeperTransporter.connect(url);
zkClient.addStateListener(state -> {
if (state == StateListener.RECONNECTED) {
try {
recover();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
});
}
注册中心在dubbo框架的位置是举足轻重的,如果它出问题就会产生单点故障,所以必须保证注册中心的高可用。dubbo在注册中心的源码中,提供了注册中心本地缓存机制进行些许的容错,在注册中心抽象实现AbstractRegistry的构造器中加载了本地缓存:
String filename = url.getParameter(FILE_KEY, System.getProperty("user.home") + "/.dubbo/dubbo-registry-" + url.getParameter(APPLICATION_KEY) + "-" + url.getAddress() + ".cache");
File file = null;
if (ConfigUtils.isNotEmpty(filename)) {
file = new File(filename);
if (!file.exists() && file.getParentFile() != null && !file.getParentFile().exists()) {
if (!file.getParentFile().mkdirs()) {
throw new IllegalArgumentException("Invalid registry cache file " + file + ", cause: Failed to create directory " + file.getParentFile() + "!");
}
}
}
this.file = file;
// When starting the subscription center,
// we need to read the local cache file for future Registry fault tolerance processing.
loadProperties();
这里尤其要注意的是,容错的方案是针对订阅的容错,不是针对注册的容错,关于这部分的设计问题个人还有不少疑问,有待进一步考察。
序列化
dubbo默认采用hessian2的序列化方案,这里不深入介绍,贴上序列化接口的源码:
@SPI("hessian2")
public interface Serialization {
/**
* Get content type unique id, recommended that custom implementations use values greater than 20.
*
* @return content type id
*/
byte getContentTypeId();
/**
* Get content type
*
* @return content type
*/
String getContentType();
/**
* Get a serialization implementation instance
*
* @param url URL address for the remote service
* @param output the underlying output stream
* @return serializer
* @throws IOException
*/
@Adaptive
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
/**
* Get a deserialization implementation instance
*
* @param url URL address for the remote service
* @param input the underlying input stream
* @return deserializer
* @throws IOException
*/
@Adaptive
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}
线程派发模型
Dubbo 将底层通信框架中接收请求的线程称为 IO 线程。如果一些事件处理逻辑可以很快执行完,比如只在内存打一个标记,此时直接在 IO 线程上执行该段逻辑即可。但如果事件的处理逻辑比较耗时,比如该段逻辑会发起数据库查询或者 HTTP 请求。此时我们就不应该让事件处理逻辑在 IO 线程上执行,而是应该派发到线程池中去执行。原因也很简单,IO 线程主要用于接收请求,如果 IO 线程被占满,将导致它不能接收新的请求。 《dubbo官方文档》

上面这张图表达的是提供方服务端的线程派发,在消费方客户端也有着类似的线程派发模型。
Dispatcher派发 和 线程池
Dispatcher根据配置来决定线程派发方式,默认的配置为all,所有消息都派发到线程池,Dispatcher的核心功能是创建合适的ChannelHandler,当配置为all时,ChannelHandler为AllChannelHandler。
// all
// direct
// message 只有请求和响应消息派发到线程池
// execution 只有请求消息派发到线程池
// connection
ChannelHandler ch = ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url)
我们进入AllChanelHandler看下里面的代码:
public class AllChannelHandler extends WrappedChannelHandler {
@Override
public void received(Channel channel, Object message) throws RemotingException {
// 获取线程池
ExecutorService executor = getExecutorService();
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
//TODO A temporary solution to the problem that the exception information can not be sent to the opposite end after the thread pool is full. Need a refactoring
//fix The thread pool is full, refuses to call, does not return, and causes the consumer to wait for time out
if(message instanceof Request && t instanceof RejectedExecutionException){
Request request = (Request)message;
if(request.isTwoWay()){
String msg = "Server side(" + url.getIp() + "," + url.getPort() + ") threadpool is exhausted ,detail msg:" + t.getMessage();
Response response = new Response(request.getId(), request.getVersion());
response.setStatus(Response.SERVER_THREADPOOL_EXHAUSTED_ERROR);
response.setErrorMessage(msg);
channel.send(response);
return;
}
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
// 略
}
这段可以看到获取线程池执行任务的代码,那么问题来了:这是一个什么样的线程池,我该如何优化它?
这个线程池是在NettyServer和NettyClient启动时创建ChannelHandler的同时初始化的,我们先来看下NettyServer中创建ChannelHandler的代码:
public NettyServer(URL url, ChannelHandler handler) throws RemotingException {
// you can customize name and type of client thread pool by THREAD_NAME_KEY and THREADPOOL_KEY in CommonConstants.
// the handler will be warped: MultiMessageHandler->HeartbeatHandler->handler
super(url, ChannelHandlers.wrap(handler, ExecutorUtil.setThreadName(url, SERVER_THREAD_POOL_NAME)));
}
ChannelHandlers.wrap方法用来创建合适的ChannelHandler。
protected ChannelHandler wrapInternal(ChannelHandler handler, URL url) {
return new MultiMessageHandler(new HeartbeatHandler(ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url)));
}
我们以AllChannelHandler为例,在初始化时会调用父类WrappedChannelHandler的构造函数:
public WrappedChannelHandler(ChannelHandler handler, URL url) {
this.handler = handler;
this.url = url;
executor = (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url);
}
看到这里已经很明朗了,线程池是ThreadPool的一个扩展,它拥有一个返回线程池的方法Executor getExecutor(URL url);。dubbo提供方服务端默认的线程池采用的是fixed类型,默认线程个数为200,我们看下构造线程池的代码:
public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
// 200
int threads = url.getParameter(THREADS_KEY, DEFAULT_THREADS);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
同理,很重要的一点是消费客户端方也拥有类似的线程模型,通过线程池执行响应处理等任务,那么它的线程池是什么样的呢?答案默认是cached,原理是在构造NettyClient的时候会默认给URL添加threadpool=cached参数,这样在自适应扩展时就会获取CachedThreadPool实例,NettyClient构造代码如下:
protected static ChannelHandler wrapChannelHandler(URL url, ChannelHandler handler) {
url = ExecutorUtil.setThreadName(url, CLIENT_THREAD_POOL_NAME);
// threadpool=cached
url = url.addParameterIfAbsent(THREADPOOL_KEY, DEFAULT_CLIENT_THREADPOOL);
return ChannelHandlers.wrap(handler, url);
}
DefaultFuture
线程派发模型中有个很重要的问题需要解决,就是线程池处理的响应结果如何传递给用户线程并且唤醒用户线程?带着这个问题我们先来看下DubboInvoker是如何调用远程服务的:
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation) invocation;
final String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment(PATH_KEY, getUrl().getPath());
inv.setAttachment(VERSION_KEY, version);
ExchangeClient currentClient;
if (clients.length == 1) {
currentClient = clients[0];
} else {
currentClient = clients[index.getAndIncrement() % clients.length];
}
try {
boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
int timeout = getUrl().getMethodPositiveParameter(methodName, TIMEOUT_KEY, DEFAULT_TIMEOUT);
if (isOneway) {
boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
currentClient.send(inv, isSent);
return AsyncRpcResult.newDefaultAsyncResult(invocation);
} else {
// 这里是核心代码
AsyncRpcResult asyncRpcResult = new AsyncRpcResult(inv);
CompletableFuture<Object> responseFuture = currentClient.request(inv, timeout);
asyncRpcResult.subscribeTo(responseFuture);
// save for 2.6.x compatibility, for example, TraceFilter in Zipkin uses com.alibaba.xxx.FutureAdapter
FutureContext.getContext().setCompatibleFuture(responseFuture);
return asyncRpcResult;
}
} catch (TimeoutException e) {
throw new RpcException(RpcException.TIMEOUT_EXCEPTION, "Invoke remote method timeout. method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
} catch (RemotingException e) {
throw new RpcException(RpcException.NETWORK_EXCEPTION, "Failed to invoke remote method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
}
}
AsyncRpcResult继承了CompletableFuture<Result>类,从而实现异步编程。responseFuture也是一个CompletableFuture<Result>类型的对象,默认实现是DefaultFuture,所以上面的问题就变成了:当有响应结果返回时,如何唤醒合适的DefaultFuture?
答案就在DefaultFuture源码中,这是一个比较重的对象,存储了所有的DefaultFuture实例,当接受到响应时,会调用静态方法received:
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap<>();
public static void received(Channel channel, Response response) {
received(channel, response, false);
}
FUTURES存储了所有实例,是一个Map结构,key是一个long类型的编号,而这个编号就是关键:
public static void received(Channel channel, Response response, boolean timeout) {
try {
// 通过编号获取future
DefaultFuture future = FUTURES.remove(response.getId());
if (future != null) {
Timeout t = future.timeoutCheckTask;
if (!timeout) {
// decrease Time
t.cancel();
}
future.doReceived(response);
} else {
logger.warn("The timeout response finally returned at "
+ (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date()))
+ ", response " + response
+ (channel == null ? "" : ", channel: " + channel.getLocalAddress()
+ " -> " + channel.getRemoteAddress()));
}
} finally {
CHANNELS.remove(response.getId());
}
}
所以唤醒用户线程是通过一个编号来关联的。
DefaultFuture 被创建时,会要求传入一个 Request 对象。此时 DefaultFuture 可从 Request 对象中获取调用编号,并将 <调用编号, DefaultFuture 对象> 映射关系存入到静态 Map 中,即 FUTURES。线程池中的线程在收到 Response 对象后,会根据 Response 对象中的调用编号到 FUTURES 集合中取出相应的 DefaultFuture 对象,然后再将 Response 对象设置到 DefaultFuture 对象中。最后再唤醒用户线程,这样用户线程即可从 DefaultFuture 对象中获取调用结果了。 《官方文档》
写在最后
成年人的世界里设计总没有对错,dubbo有它独特的整体设计,虽然某些细节还不能尽善尽美。理解dubbo内部的工作细节,才能对一个框架的使用保持最合适的态度。