Jiepai
 Jiepai copied to clipboard
Jiepai copied to clipboard
Jiepai Pictures of Toutiao

# 做了简单的修改 1. 原图(大图)之前使用的lager方法只能获取很少的图片部分(几张图片),修改后的代码现在测试都能正常获取下载全部的图片 2. 之前构建的url地址获取的 json做了下修改,加入cookies能正常获取网页提取的url地址(如果大量爬取或许需要加入cookies池),我不能理解为什么是那样去获取(很神奇他竟然不需要cookies能获取完整的json,虽然和我们访问网页获取的不一致),希望有人解释一下. 见附件 [Jiepai-master.zip](https://github.com/Python3WebSpider/Jiepai/files/3274941/Jiepai-master.zip)
我观察到 ajax 的url 带有app_name参数 加入以后,params为 params = { 'aid': '24', 'app_name':'web_search' 'offset': offset, 'format': 'json', 'keyword': '街拍', 'autoload': 'true', 'count': '20', 'cur_tab': '1', 'from': 'search_tab', 'pd': 'synthesis' } 但是 返回为NONE,...
``` import os from multiprocessing.pool import Pool import requests from urllib.parse import urlencode from hashlib import md5 from requests import codes def get_page(offset): params = { 'offset': offset, 'format': 'json',...
def get_page(offset): t=int(time.time()) params={ 'aid':'24', 'app_name':'web_search', 'offset':offset, 'format':'json', 'keyword':'%E8%A1%97%E6%8B%8D', 'autoload':'true', 'count':'20', 'en_qc':'1', 'cur_tab':'1', 'from':'search_tab', 'pd':'synthesis', 'timestamp':t } url='https://www.toutiao.com/api/search/content/?'+urlencode(params) try: response=requests.get(url) response.raise_for_status() return response.json() except requests.ConnectionError: return None
现在这个解析方式取到的街拍文章大多都不是正常的街拍美图   取出`data`中`article_url`再对`article_url`进行爬取解析出来取得的图片质量和数量都很不错  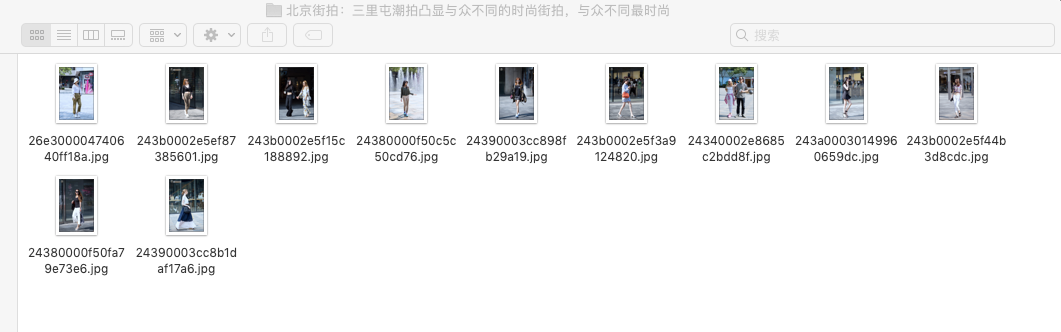
38 for image in images: 39 origin_image = re.sub("list", "origin",image.get('url') “origin”后面的逗号是中文的,最后位置缺个反括号
需要从浏览器中拷贝cookie 否则只加载基本网页结构 ```python import requests import re import json import os from urllib.parse import urlencode from requests import codes from multiprocessing.pool import Pool heardes = { "user-agent": "Mozilla / 5.0(Windows...