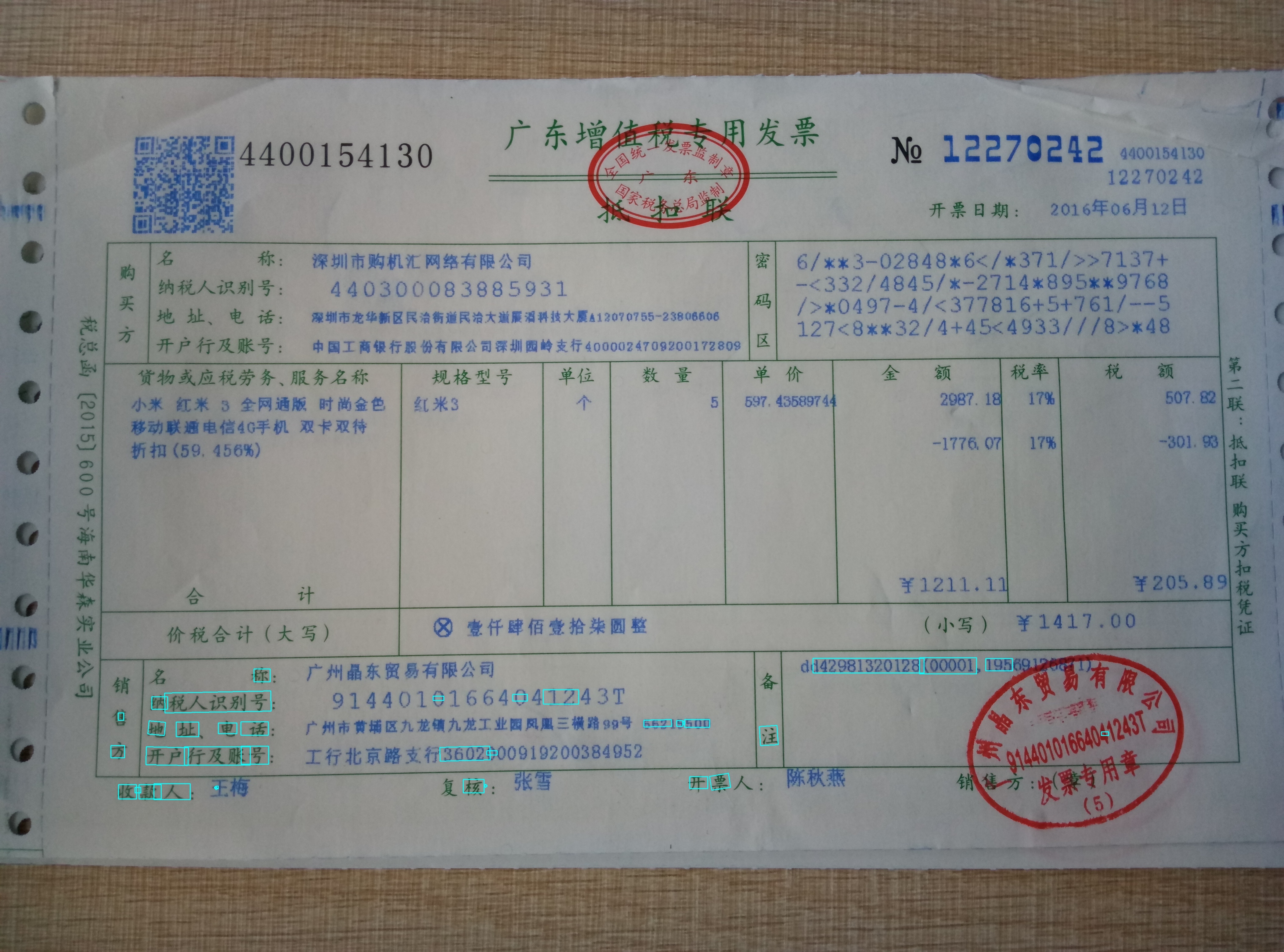
增值税发票文本检测,基于PPOCRv3轻量检测模型的finetune训练,训练精度非常低
场景介绍:增值税发票文本检测
1、首先使用ppocrLabel标注工具对数据进行标注(自动标注后,主要是将一些文字间距较大的字段的标注做修改,多个文本区域进行合并);
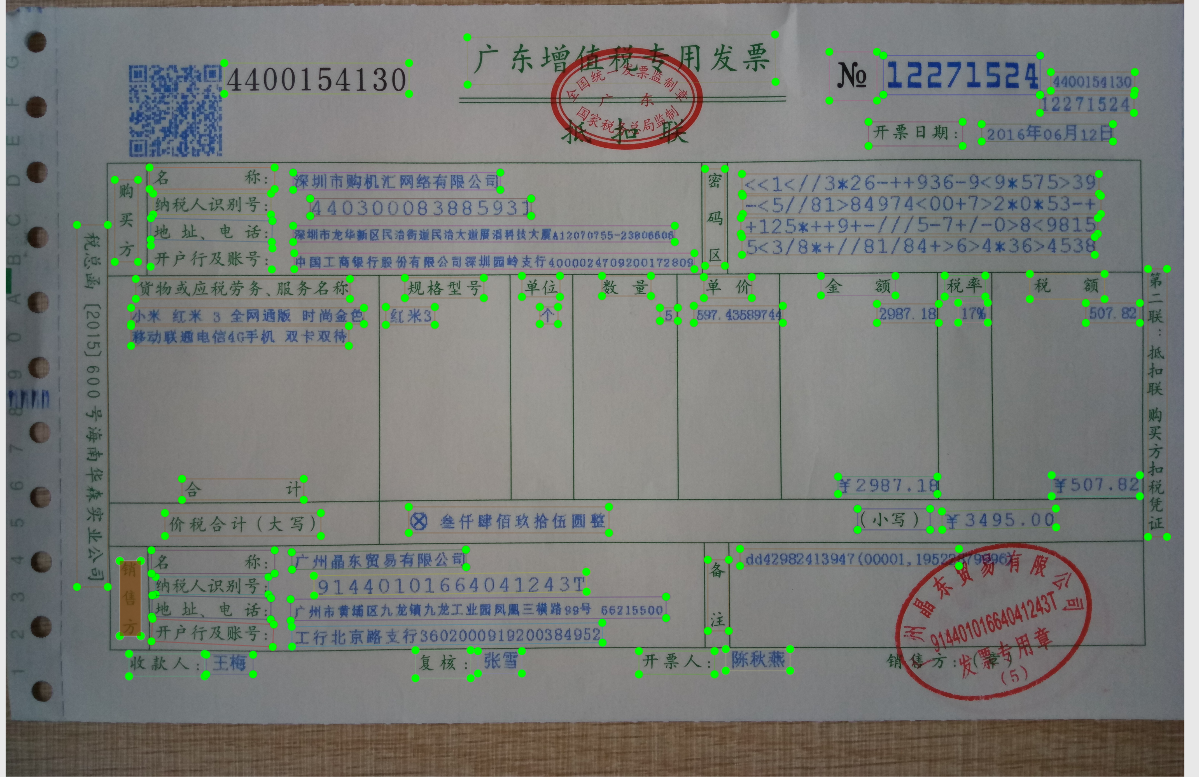
2、基于PPOCRv3轻量检测模型的finetune训练,训练精度非常低
- 系统环境/System Environment:ubuntu18.4,python3.7
- 版本号/Version:Paddle:2.2.0-gpu
使用ch_PP-OCRv3_det_distill_train的student预训练模型进行finetune
-
运行指令: python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
-o Global.pretrained_model=/home/models/pretrained_models/ch_PP-OCRv3_det_distill_train/student
Global.save_model_dir=/home/models/train_models/det_models/ppv3 -
问题:训练精度随epoch增长逐渐降低



ch_PP-OCRv3_det_student.yml配置如下: Global: debug: false use_gpu: true epoch_num: 5000 log_smooth_window: 20 print_batch_step: 10 save_model_dir: /home/models/train_models/det_models/ppv3 save_epoch_step: 100 eval_batch_step:
- 0
- 100 cal_metric_during_train: false pretrained_model: null checkpoints: null save_inference_dir: null use_visualdl: false infer_img: /home/sxct-ocr/static/pic/b201.jpg save_res_path: /home/models/train_models/det_models/ppv3/output/predicts_db.txt distributed: true
Architecture: model_type: det algorithm: DB Transform: Backbone: name: MobileNetV3 scale: 0.5 model_name: large disable_se: True Neck: name: RSEFPN out_channels: 96 shortcut: True Head: name: DBHead k: 50
Loss: name: DBLoss balance_loss: true main_loss_type: DiceLoss alpha: 5 beta: 10 ohem_ratio: 3 Optimizer: name: Adam beta1: 0.9 beta2: 0.999 lr: name: Cosine learning_rate: 0.001 warmup_epoch: 2 regularizer: name: L2 factor: 5.0e-05 PostProcess: name: DBPostProcess thresh: 0.3 box_thresh: 0.6 max_candidates: 1000 unclip_ratio: 1.5 Metric: name: DetMetric main_indicator: hmean Train: dataset: name: SimpleDataSet data_dir: /home/sxct-ocr/static/invoice/train label_file_list: - /home/sxct-ocr/static/invoice/train/train.txt ratio_list: [1.0] transforms: - DecodeImage: img_mode: BGR channel_first: false - DetLabelEncode: null - IaaAugment: augmenter_args: - type: Fliplr args: p: 0.5 - type: Affine args: rotate: - -10 - 10 - type: Resize args: size: - 0.5 - 3 - EastRandomCropData: size: - 960 - 960 max_tries: 50 keep_ratio: true - MakeBorderMap: shrink_ratio: 0.4 thresh_min: 0.3 thresh_max: 0.7 - MakeShrinkMap: shrink_ratio: 0.4 min_text_size: 8 - NormalizeImage: scale: 1./255. mean: - 0.485 - 0.456 - 0.406 std: - 0.229 - 0.224 - 0.225 order: hwc - ToCHWImage: null - KeepKeys: keep_keys: - image - threshold_map - threshold_mask - shrink_map - shrink_mask loader: shuffle: true drop_last: false batch_size_per_card: 4 num_workers: 4 Eval: dataset: name: SimpleDataSet data_dir: /home/sxct-ocr/static/invoice/val label_file_list: - /home/sxct-ocr/static/invoice/val/val.txt transforms: - DecodeImage: img_mode: BGR channel_first: false - DetLabelEncode: null - DetResizeForTest: null - NormalizeImage: scale: 1./255. mean: - 0.485 - 0.456 - 0.406 std: - 0.229 - 0.224 - 0.225 order: hwc - ToCHWImage: null - KeepKeys: keep_keys: - image - shape - polys - ignore_tags loader: shuffle: false drop_last: false batch_size_per_card: 1 num_workers: 2
使用原始ch_PP-OCRv3_det_distill_train/student预训练模型直接预测结果:
finetune 500 epoch之后预测结果:

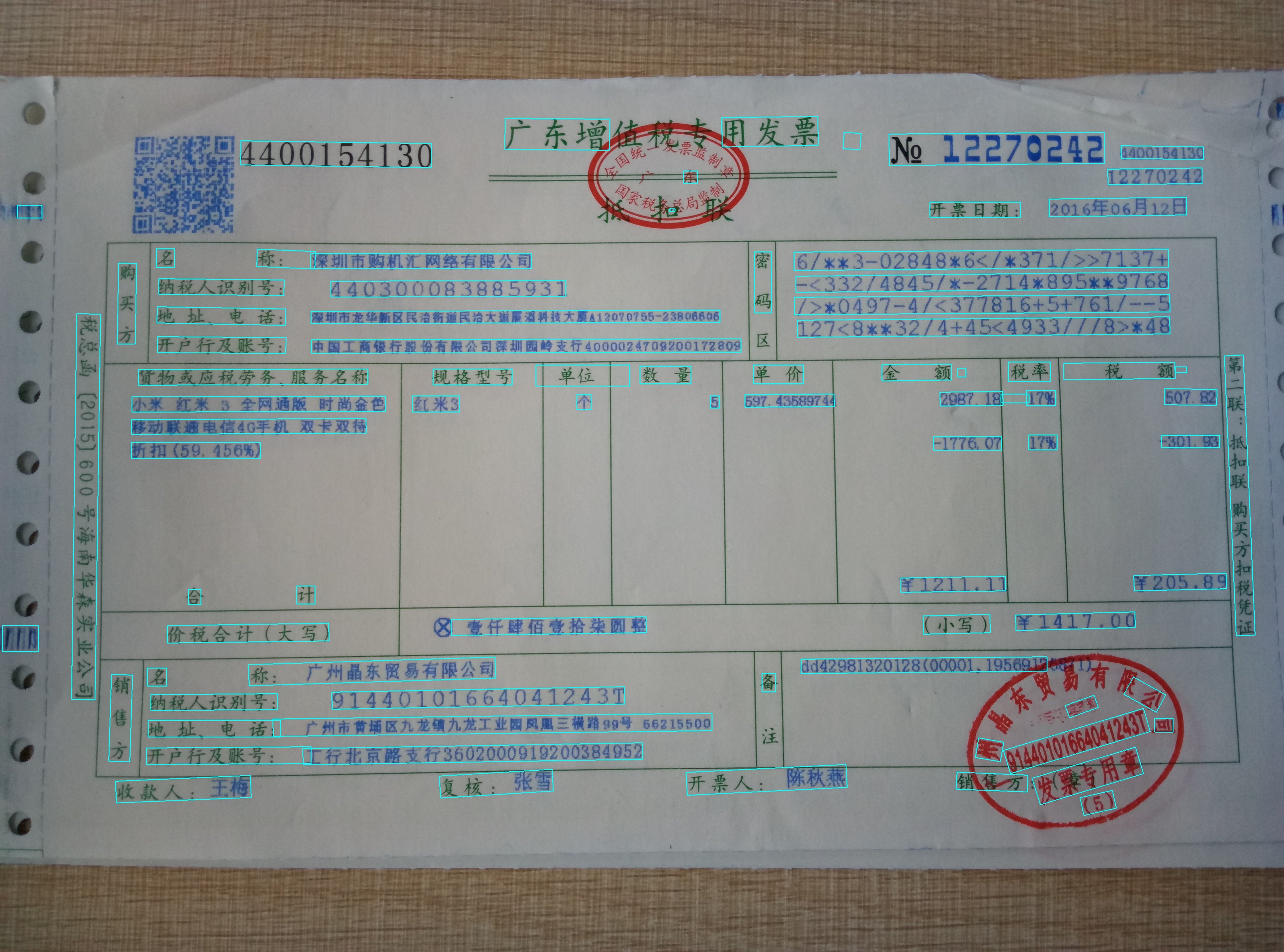
finetune 5000 epoch之后的预测结果: