Swin graph 3d 并行,打开 acc grad 报错
实验分支:https://github.com/Oneflow-Inc/libai/pull/215
文件 swin_cifar100.py 关键配置
train.train_micro_batch_size = 8
train.num_accumulation_steps = 2
train.test_micro_batch_size = 16
# parallel strategy settings
train.dist.data_parallel_size = 2
train.dist.tensor_parallel_size = 2
train.dist.pipeline_parallel_size = 2
train.dist.pipeline_num_layers = sum(model.depths)
train.output_dir="./output"
# Set fp16 ON
train.amp.enabled = False
train.activation_checkpoint.enabled = False
graph.enabled = True
bash tools/train.sh tools/train_net.py configs/swin_cifar100.py 8
报错信息
F20220329 17:22:55.548020 41348 task_node.cpp:385] Check failed: lbi2data_regst.size() == lbis_.size() (1 vs. 0)
TaskEdge lbi and regst NOT match. TaskEdge: edge_id = 139009 From: [System-GradientAccumulation-VariableRepeat-model.layers.3.blocks.1.attn.relative_position_bias_table-500] To: [kBoxingZeros\n5:84955136\n178163833374140]
*** Check failure stack trace: ***
@ 0x7febda2b92ea (unknown)
@ 0x7febda2b95d2 (unknown)
@ 0x7febda2b8e57 (unknown)
@ 0x7febda2bb9c9 (unknown)
@ 0x7febd3755466 oneflow::TaskEdge::CheckRegstLbiValid()
@ 0x7febd37b3e1b oneflow::Compiler::Compile()
@ 0x7febd327fd17 oneflow::NNGraph::CompileAndInitRuntime()
@ 0x7febd1c43f6f (unknown)
@ 0x7febd16d3344 (unknown)
@ 0x55f88f4caed4 _PyCFunction_FastCallDict
@ 0x55f88f552c4e call_function
@ 0x55f88f5752ca _PyEval_EvalFrameDefault
@ 0x55f88f54bdc4 _PyEval_EvalCodeWithName
@ 0x55f88f54d358 _PyFunction_FastCallDict
@ 0x55f88f4cb29f _PyObject_FastCallDict
@ 0x55f88f4cfda3 _PyObject_Call_Prepend
@ 0x55f88f4cacde PyObject_Call
@ 0x55f88f576952 _PyEval_EvalFrameDefault
@ 0x55f88f54bdc4 _PyEval_EvalCodeWithName
@ 0x55f88f54d358 _PyFunction_FastCallDict
@ 0x55f88f4cb29f _PyObject_FastCallDict
@ 0x55f88f4cfda3 _PyObject_Call_Prepend
@ 0x55f88f4cacde PyObject_Call
@ 0x55f88f523971 slot_tp_call
@ 0x55f88f4cacde PyObject_Call
验证这个分支:
是否解决上述问题。
这个 BUG 的原因是: swin Variable Op 后面有一个 B2P 的 boxing,该 boxing 会插入 zero boxing task node。但是在 :NaiveB2PSubTskGphBuilder 中, B2P 构造的 task edge 没有 add lbi。由于之前的 case 里没有 B2P 的单测,导致个 BUG 隐藏到现在才暴露。
@liujuncheng @Ldpe2G @strint @leaves-zwx
不过我有一个问题,B2P 是一个不太常见的 boxing, swin 开 3-D 并行,Variable 后面跟一个 B2P 的消费,是否符合预期? @Ldpe2G @strint @leaves-zwx @L1aoXingyu
这组配置可以跑起来
train.train_micro_batch_size = 8
train.num_accumulation_steps = 2
train.test_micro_batch_size = 16
这组配置虽然不会报错,但是会卡住,有几张卡利用率 100%,其他为0%
train.train_micro_batch_size = 32
train.num_accumulation_steps = 4
train.test_micro_batch_size = 128
num_accumulation_steps 的设置是不是不能超过 网络流水的 stage 数量?8卡3d并行是分成两个stage。
num_accumulation_steps的设置是不是不能超过 网络流水的 stage 数量?8卡3d并行是分成两个stage。
不是,相反,grad acc 的次数,应该是至少 stage 数量的 2 倍。
这组配置可以跑起来
train.train_micro_batch_size = 8 train.num_accumulation_steps = 2 train.test_micro_batch_size = 16这组配置虽然不会报错,但是会卡住,有几张卡利用率 100%,其他为0%
train.train_micro_batch_size = 32 train.num_accumulation_steps = 4 train.test_micro_batch_size = 128
那可能是网络结构上有问题。 @leaves-zwx 文骁辅助德澎 debug 一下吧。 这个跟中兴那边的 swin-T 有交集。
这组配置虽然不会报错,但是会卡住,有几张卡利用率 100%,其他为0%
8卡3D并行也就是 2+2+2 吗?这种现象很大可能跟 nccl 启动顺序不一致所致。nccl_use_compute_stream 这个选项开启了吗?
这组配置虽然不会报错,但是会卡住,有几张卡利用率 100%,其他为0%
8卡3D并行也就是 2+2+2 吗?这种现象很大可能跟 nccl 启动顺序不一致所致。nccl_use_compute_stream 这个选项开启了吗?
是的,我看下
这组配置虽然不会报错,但是会卡住,有几张卡利用率 100%,其他为0%
8卡3D并行也就是 2+2+2 吗?这种现象很大可能跟 nccl 启动顺序不一致所致。nccl_use_compute_stream 这个选项开启了吗?
这个在 libai 里是默认开启的。 @L1aoXingyu
第一步,先确认各 rank 运行卡在什么位置(也就是什么 op 上),基本上有2种方法:
- log 大法,在 kernel 的关键函数上(比如 forward)添加合适的 debug code,LOG(INFO) 打印 op 的信息(最重要肯定是 op_name),运行卡住后,从各rank不同的 INFO 文件里面查看都运行到什么 kernel 了
- gdb 大法,运行 oneflow distributed 卡住后,使用 gdb attach -p pid 进入相应的进程,pid 可以从 *.INFO 的名字中查看到,也可以通过 ps aux | grep ... 来搜索出来。进入 gdb 后,主要思路是找到卡住的线程,但我们有100个左右的线程。但上面的报错表现来看,最有可能的原因就是 nccl 卡住,所以我们要找 nccl 所在线程。如果 nccl_use_compute_stream 为开启,则 nccl 在单独的 nccl stream 线程中,如果 nccl_use_compute_stream 未开启,则 nccl 在 compute stream 的线程中。在 gdb 中我们可以通过 info thread 来打印所有的线程信息,这时我们要找到我们想要的线程,需要知道线程的 LWP,我们可以在创建的线程的地方增加 debug code 来打印出不同的 stream 所对应的线程号。
简单的说就是先确认各 rank 各 stream 卡在何处。
我怎么记得这个 BUG 之前出现过。。。 上次是触发 1024 的上限,导致异步变同步死锁的
偏序执行不一定唯一是 nccl 调用顺序不同的原因
void Kernel::Launch(KernelContext* ctx) const {
LOG(INFO) << "before: " << this->kernel_conf_.op_attribute().op_conf().name();
ctx->WillForward(ctx, this);
Forward(ctx);
ctx->DidForward(ctx, this);
LOG(INFO) << "after: " << this->kernel_conf_.op_attribute().op_conf().name();
}
所有 Log 文件:
https://oneflow-static.oss-cn-beijing.aliyuncs.com/log.tar.gz
~~log 里面所有 kernel 的 before 和 after 都成对出现,至少说明不是卡在 kernel launch 上的,自然就不会是到达了 ‘1024’ 软上限导致 kernel launch 异步变同步的问题。~~
仔细看了一下,不是所有的 kernel 都有成对的 before 和 after
~log 里面所有 kernel 的 before 和 after 都成对出现,至少说明不是卡在 kernel launch 上的,自然就不会是到达了 ‘1024’ 软上限导致 kernel launch 异步变同步的问题。~
仔细看了一下,不是所有的 kernel 都有成对的 before 和 after
I20220419 11:42:17.453923 2726812 kernel.cpp:51] before: System-Src-WaitAndSendIds_1157
I20220419 11:42:17.458292 2726812 kernel.cpp:55] after: System-Src-WaitAndSendIds_1157
I20220419 11:42:17.458362 2726812 kernel.cpp:51] before: System-Src-WaitAndSendIds_1157
看了下 rank 0 的 INFO,在最开始,System-Src-WaitAndSendIds_1157 有两个 before,但是只有一个 after
I20220419 11:41:22.487932 2724642 eager_boxing_logger.cpp:42] Boxing route: symmetric-acyclic-nd-sbp-to-nd-sbp -> naive-b-to-1 -> naive-1-to-1 -> naive-1-to-p -> symmetric-acyclic-nd-sbp-to-nd-sbp
I20220419 11:41:22.488044 2724642 eager_boxing_logger.cpp:43] Logical shape: (256,100)
I20220419 11:41:22.488057 2724642 eager_boxing_logger.cpp:44] Altered state of sbp: (S(0), B) -> (B, B) -> (B, B) -> (B, B) -> (P, P) -> (S(0), B)
I20220419 11:41:22.488121 2724642 eager_boxing_logger.cpp:45] Altered state of placement: oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]) -> oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]) -> oneflow.placement(type="cuda", ranks=[[0]]) -> oneflow.placement(type="cuda", ranks=[[4]]) -> oneflow.placement(type="cuda", ranks=[[4, 5], [6, 7]]) -> oneflow.placement(type="cuda", ranks=[[4, 5], [6, 7]])
看 rank 0 LOG 的时候发现这一段,包含了 B -> P 的 boxing
看起来是的
I20220419 11:41:22.487932 2724642 eager_boxing_logger.cpp:42] Boxing route: symmetric-acyclic-nd-sbp-to-nd-sbp
-> naive-b-to-1
-> naive-1-to-1
-> naive-1-to-p // ?
-> symmetric-acyclic-nd-sbp-to-nd-sbp
I20220419 11:41:22.488044 2724642 eager_boxing_logger.cpp:43] Logical shape: (256,100)
I20220419 11:41:22.488057 2724642 eager_boxing_logger.cpp:44] Altered state of sbp: (S(0), B)
-> (B, B)
-> (B, B)
-> (B, B)
-> (P, P) // (S(0), S(0)) 是不是更好?
-> (S(0), B)
I20220419 11:41:22.488121 2724642 eager_boxing_logger.cpp:45] Altered state of placement:
oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]])
-> oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]])
-> oneflow.placement(type="cuda", ranks=[[0]])
-> oneflow.placement(type="cuda", ranks=[[4]])
-> oneflow.placement(type="cuda", ranks=[[4, 5], [6, 7]]) // ?
-> oneflow.placement(type="cuda", ranks=[[4, 5], [6, 7]])
System-GradientAccumulation-VariableRepeat-model.layers.1.blocks.0.attn.relative_position_bias_table-366,model.layers.1.blocks.0.attn-gather_nd-162_grad,{0:cuda:0-0 1:cuda:1-1 2:cuda:2-2 3:cuda:3-3 (2 2)},{0:cuda:0-0 1:cuda:1-1 2:cuda:2-2 3:cuda:3-3 (2 2)},(B, B),(P, P),System-GradientAccumulation-VariableRepeat-model.layers.1.blocks.0.attn.relative_position_bias_table-366/out_0,kFloat,(169 6),NaiveB2PSubTskGphBuilder,-
看 boxing cvs 里面是有 B->P 的
relative_position_bias_table 这个参数,构造的时候是 B
看了下 rank 0 的 INFO,在最开始,System-Src-WaitAndSendIds_1157 有两个 before,但是只有一个 after
这个是正常现象,因为整个集群都还在第1个 micro-batch 内,没运行到第2个 micro-batch,所以第2个 System-Src-WaitAndSendIds_1157 在等待用户触发。
所有 rank 运行状况:
- rank0: 运行完2个forward(这里单位是 mini-batch,后文不再复述),第3个forward卡在中途;第1个backward只执行了第一个 op (buffer op),该 op 不在 backward stream 上,所以 backward stream 还没执行任何 op
- rank1: 运行完2个forward,第3个forward卡在中途;第1个backward只执行了一部分(执行到 System-NCCL-Logical-(*S0)2(*B)-1210 只有 before 没有 after),但第2个backward的起点也就是 buffer op 因为是在 forward stream 上,也被调度了。
- rank2: 执行了4个完整的 forward,2个完整的 backward
- rank3: 同上
- rank4: 2个完整 forward,2个完整 backward
- rank5: 同上
- rank6: 3个完整 forward,第4个 forward 只调用了第1个op (buffer op);2个完整 backward
- rank7: 同上
比较异常的点:
- 对于 stage0 的2个stream (forward and backward),backward 所依赖的起始 buffer op 被放置在 forward stream 上执行
- rank1 卡在 nccl 上
- rank6,rank7 好像没有遵循 1F1B
接下来可以尝试的:
- 接续分析整个执行的 timeline
- gdb 找到具体的卡住的位置
- 在上面 gdb debug 的同时,分析 log 看是否卡在同样的情况,也就是错误复现的稳定性,看是卡在同样的位置还是其他位置
gdb 进入 rank 1 ,然后切到 System-NCCL-Logical-(*S0)2(*B) 这个操作对应的 thread ,看样子是卡在 NcclLogical2DSameDim0AllGather compute 函数里:
#2 pollset_work (pollset=0x7f6215d1b9e8, worker_hdl=<optimized out>, deadline=<optimized out>) at src/core/lib/iomgr/ev_epollex_linux.cc:11[30/1921]#3 0x00007f670981d64d in cq_pluck (cq=0x7f6215d1b8b0, tag=0x7f64d17fd150, deadline=..., reserved=<optimized out>)
at src/core/lib/surface/completion_queue.cc:1302 #4 0x00007f67062d96cc in grpc_impl::CompletionQueue::Pluck (tag=<optimized out>, this=<optimized out>)
at third_party_install/grpc/include/grpcpp/impl/codegen/completion_queue_impl.h:314
#5 grpc::internal::BlockingUnaryCallImpl<oneflow::LoadServerRequest, oneflow::LoadServerResponse>::BlockingUnaryCallImpl (result=<optimized out>,
request=..., context=<optimized out>, method=..., channel=<optimized out>, this=<optimized out>)
at third_party_install/grpc/include/grpcpp/impl/codegen/client_unary_call.h:72 #6 grpc::internal::BlockingUnaryCall<oneflow::LoadServerRequest, oneflow::LoadServerResponse> (result=<optimized out>, request=...,
context=<optimized out>, method=..., channel=<optimized out>) at third_party_install/grpc/include/grpcpp/impl/codegen/client_unary_call.h:43
#7 oneflow::CtrlService::Stub::CallMethod<(oneflow::CtrlMethod)0> (response=<optimized out>, request=..., context=<optimized out>, this=<optimized out>) at ../oneflow/core/control/ctrl_service.h:47 #8 oneflow::RpcClient::LoadServer (this=<optimized out>, request=..., stub=<optimized out>) at ../oneflow/core/control/rpc_client.cpp:185 #9 0x00007f67062d1a8b in grpc::internal::BlockingUnaryCallImpl<oneflow::PullKVRequest, oneflow::PullKVResponse>::BlockingUnaryCallImpl (
result=0x7f64d17fce20, request=..., context=0x7f64d17fcf50, method=..., channel=<optimized out>, this=0x7f64d17fceb0)
at third_party_install/grpc/include/grpcpp/impl/codegen/client_unary_call.h:72
#10 grpc::internal::BlockingUnaryCall<oneflow::PullKVRequest, oneflow::PullKVResponse> (result=0x7f64d17fce20, request=..., context=0x7f64d17fcf50,
method=..., channel=<optimized out>) at third_party_install/grpc/include/grpcpp/impl/codegen/client_unary_call.h:43
#11 oneflow::CtrlService::Stub::CallMethod<(oneflow::CtrlMethod)7> (response=0x7f64d17fce20, request=..., context=0x7f64d17fcf50,
this=<optimized out>) at ../oneflow/core/control/ctrl_service.h:47
#12 oneflow::(anonymous namespace)::ClientCall<(oneflow::CtrlMethod)7>::operator() (this=this@entry=0x7f64d17fd3b0, stub=0x5637848a9f70)
at ../oneflow/core/control/rpc_client.cpp:40
#13 0x00007f67062d5578 in oneflow::RpcClient::PullKV(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::function<void (std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)>) (this=this@entry=0x5637848b1fd0, k=...,
VGetter=...) at ../oneflow/core/control/rpc_client.cpp:129
#14 0x00007f67062bc77c in oneflow::GrpcCtrlClient::PullKV(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::function<void (std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)>) (this=0x5637848b1f20, k=..., VGetter=...)
at ../oneflow/core/control/ctrl_client.cpp:98
#15 0x00007f67075969fa in oneflow::(anonymous namespace)::CreateNcclComm (comm=comm@entry=0x7f64d17fd830, dev=<optimized out>, key=...,
device_vec=...) at ../oneflow/core/job/eager_nccl_comm_manager.cpp:66
#16 0x00007f6707597a0c in oneflow::EagerNcclCommMgr::GetCommForDeviceAndStreamName (this=0x563784a47550, device_set=..., stream_name=...)
at ../oneflow/core/job/eager_nccl_comm_manager.cpp:130
#17 0x00007f6708e36f47 in oneflow::(anonymous namespace)::NcclLogical2DSameDim0KernelCommState::Init (this=this@entry=0x7f6215cb5b20)
at ../oneflow/user/kernels/nccl_logical_2d_sbp_kernels.cpp:75
#18 0x00007f6708e37b78 in oneflow::(anonymous namespace)::NcclLogical2DSameDim0KernelCommState::num_ranks (this=0x7f6215cb5b20)
at ../oneflow/user/kernels/nccl_logical_2d_sbp_kernels.cpp:49
#19 oneflow::(anonymous namespace)::NcclLogical2DSameDim0AllGather::Compute (this=<optimized out>, ctx=0x7f6215ca2af0, state=<optimized out>)
- 在上面 gdb debug 的同时,分析 log 看是否卡在同样的情况,也就是错误复现的稳定性,看是卡在同样的位置还是其他位置
对比了下两次运行的Log,貌似每个rank都是卡在同个地方,Log文件行数都一样
死锁原因是:stage0 的 backward buffer op 被放置在 forward stream 上了
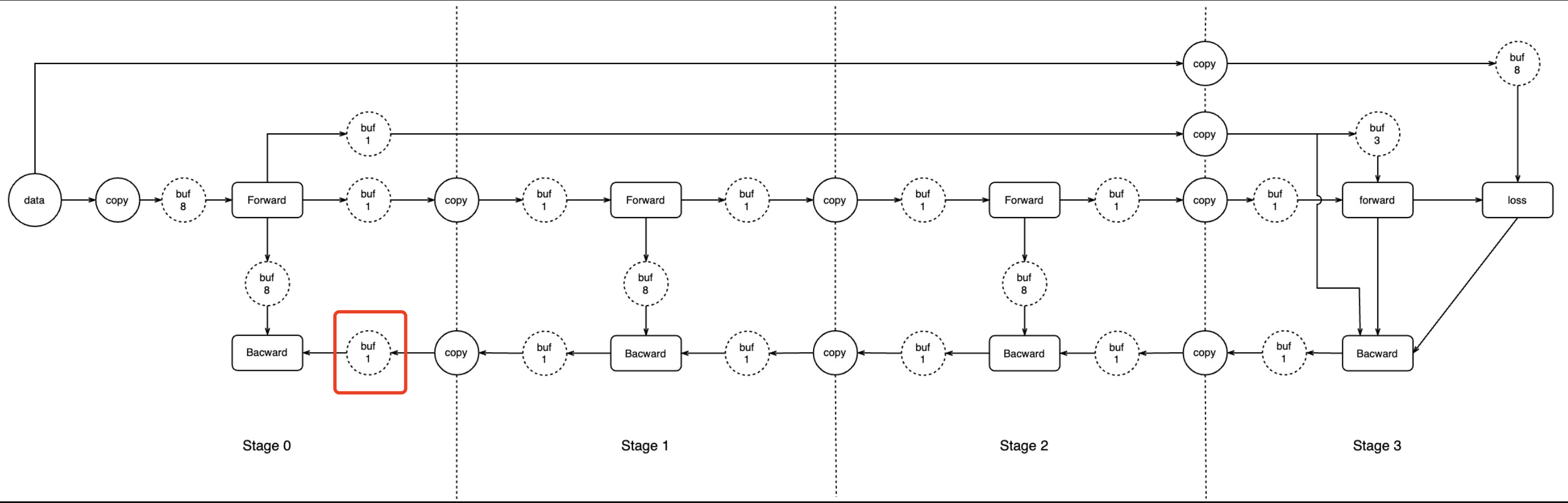
即上图红色框所标识的 buffer op 本应该放在 backward stream 上,但却被放置到 forward stream 上了。应该是在 pipeline buffer pass 里面插入 buffer op 的时候需要考虑上下游的 op 的 stream name hint 但没考虑。
死锁的现象
swin-T 2x2x2 的并行。根据 https://github.com/Oneflow-Inc/libai/issues/232#issuecomment-1103438000 的描述,backward source buffer op of stage0 被放置在了 forward stream 上,但它可能出现在 forward 的任何位置。下面是死锁时,相关 rank 和 thread 的运行时序。
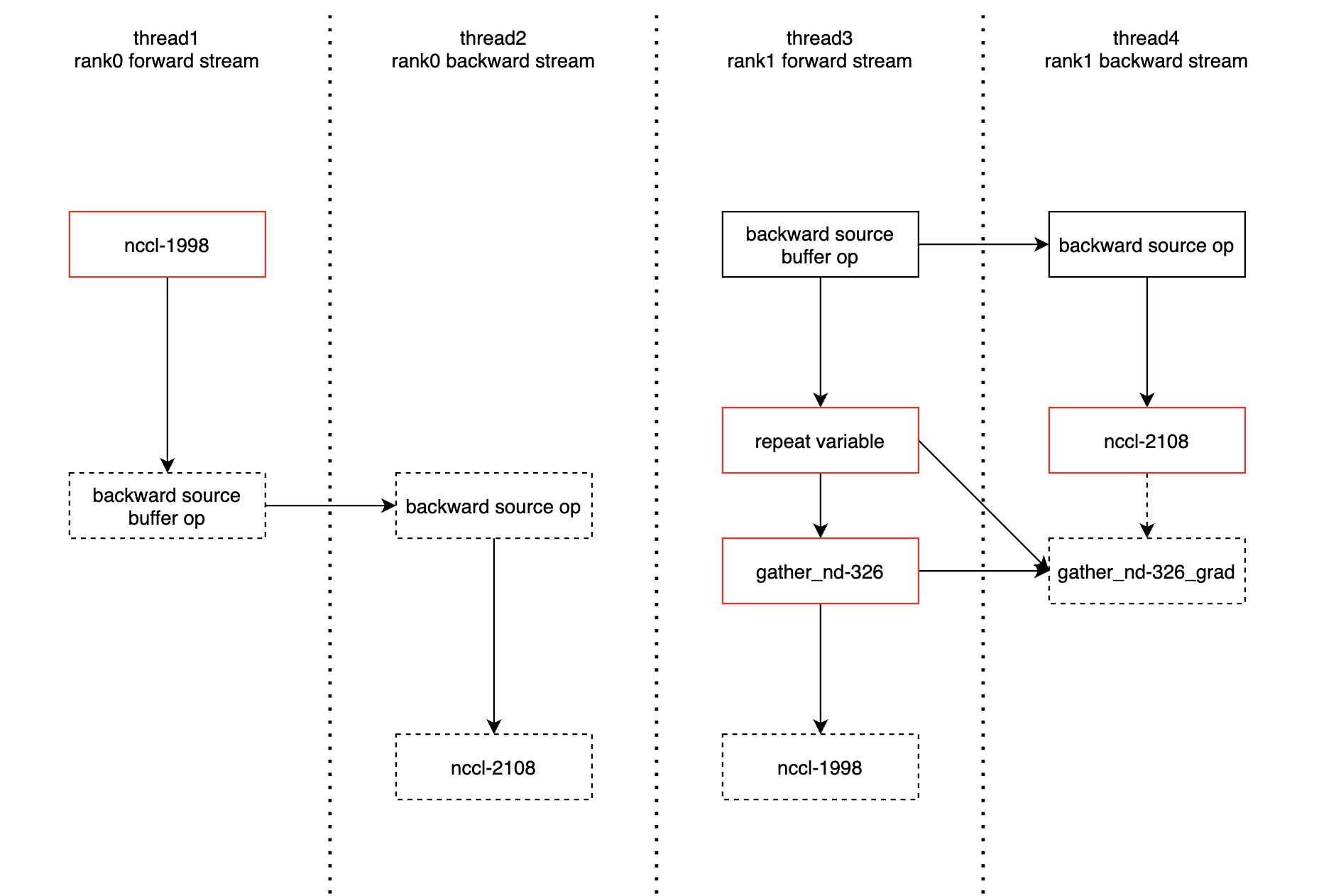
- thread1: 卡在 nccl-1998 无法继续执行,依赖于 thread3 上的 nccl-1998
- thread2: 由于放置于 forward stream 上的 source buffer op 没执行,整个 backward 都被阻塞
- thread3: source buffer op 执行了,并且触发了部分后向的执行,但执行到 nccl-2108 被阻塞,因为 thread2 上的 nccl-2108 无法被执行。nccl-2108 之后的 gather_nd-326_grad 未执行,它消费的 repeat actor 不会收到 consumed 消息,而 repeat regst num = 1,所以它在执行1次后也被阻塞,导致其后的 nccl-1998 也得不到执行。
- thread4: nccl-2108 被阻塞,因为 thread2 上的 nccl-2108 得不到执行。
整个死锁过程中,只有 thread3 的死锁比较难以理解,为什么后向会阻塞前向的执行。这里实际上 rank1 的 forward 已经执行过 2 轮,第 3 轮的 forward 被第 1 轮的 backward 卡住,因为第 1 轮的 backward 如果不执行下去,第 2 轮的 forward 中的那个 repeat 是无法被还回那个 out regst 的。抽象的说,其他3个thread的死锁是发生在1个时间平面上的,而thread3被阻塞是由于不同时间点的冲突。