输入图片尺寸高h和宽w不相等时报错Segmentation Fault
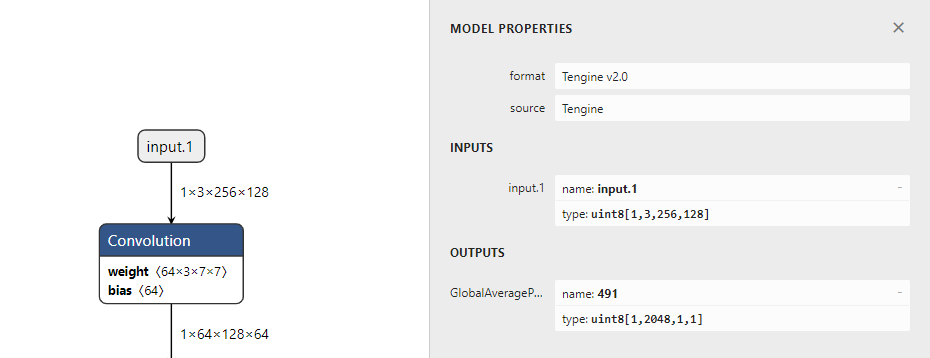
pytorch导出预训练resnet50模型,去掉fc层,输入设置为256x128,经过量化成uint8模型以后,发现在tm_classification_timvx基础上小修改后,-g 256,128时会出现Segmentation Fault,但是-g 256,256或者-g 128,128 却是能正常运行的,明明模型的输入设置是256x128,为什么经过resize的图片大小和模型设置不一致时能正常输出结果,一致的时候却会报错呢orz,下面是我的测试代码以及onnx和uint8模型,目前能够确认是在run_graph函数这里出错了
测试环境是khadas vim3 最新的npu驱动



链接:https://pan.baidu.com/s/1vnkseiQ3EeWeiXpwKfevRA 提取码:lq14 --来自百度网盘超级会员V4的分享
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* License); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* AS IS BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
/*
* Copyright (c) 2020, OPEN AI LAB
* Author: [email protected]
*/
#include <stdlib.h>
#include <stdio.h>
#include "common.h"
#include "tengine/c_api.h"
#include "tengine_operations.h"
#define DEFAULT_IMG_H 256
#define DEFAULT_IMG_W 128
#define DEFAULT_SCALE1 0.0174
#define DEFAULT_SCALE2 0.0175
#define DEFAULT_SCALE3 0.0171
#define DEFAULT_MEAN1 103.53
#define DEFAULT_MEAN2 116.28
#define DEFAULT_MEAN3 123.675
#define DEFAULT_LOOP_COUNT 1
#define DEFAULT_THREAD_COUNT 1
#define DEFAULT_CPU_AFFINITY 255
void get_input_uint8_data(const char* image_file, uint8_t* input_data, int img_h, int img_w, float* mean, float* scale,
float input_scale, int zero_point)
{
image img = imread_process(image_file, img_w, img_h, mean, scale);
float* image_data = (float*)img.data;
for (int i = 0; i < img_w * img_h * 3; i++)
{
int udata = round(image_data[i] / input_scale + (float)zero_point);
if (udata > 255)
udata = 255;
else if (udata < 0)
udata = 0;
input_data[i] = udata;
}
free_image(img);
}
int tengine_reid(const char* model_file, const char* image_file, int img_h, int img_w, float* mean, float* scale,
int loop_count, int num_thread, int affinity)
{
/* set runtime options */
struct options opt;
opt.num_thread = num_thread;
opt.cluster = TENGINE_CLUSTER_ALL;
opt.precision = TENGINE_MODE_UINT8;
opt.affinity = affinity;
/* inital tengine */
if (init_tengine() != 0)
{
fprintf(stderr, "Initial tengine failed.\n");
return -1;
}
fprintf(stderr, "tengine-lite library version: %s\n", get_tengine_version());
/* create VeriSilicon TIM-VX backend */
context_t timvx_context = create_context("timvx", 1);
int rtt = set_context_device(timvx_context, "TIMVX", NULL, 0);
if (0 > rtt)
{
fprintf(stderr, " add_context_device VSI DEVICE failed.\n");
return -1;
}
/* create graph, load tengine model xxx.tmfile */
graph_t graph = create_graph(timvx_context, "tengine", model_file);
if (NULL == graph)
{
fprintf(stderr, "Create graph failed.\n");
return -1;
}
/* set the input shape to initial the graph, and prerun graph to infer shape */
int img_size = img_h * img_w * 3;
int dims[] = {1, 3, img_h, img_w}; // nchw
uint8_t* input_data = (uint8_t*)malloc(img_size);
tensor_t input_tensor = get_graph_input_tensor(graph, 0, 0);
if (input_tensor == NULL)
{
fprintf(stderr, "Get input tensor failed\n");
return -1;
}
if (set_tensor_shape(input_tensor, dims, 4) < 0)
{
fprintf(stderr, "Set input tensor shape failed\n");
return -1;
}
if (set_tensor_buffer(input_tensor, input_data, img_size) < 0)
{
fprintf(stderr, "Set input tensor buffer failed\n");
return -1;
}
/* prerun graph, set work options(num_thread, cluster, precision) */
if (prerun_graph_multithread(graph, opt) < 0)
{
fprintf(stderr, "Prerun multithread graph failed.\n");
return -1;
}
/* prepare process input data, set the data mem to input tensor */
float input_scale = 0.f;
int input_zero_point = 0;
get_tensor_quant_param(input_tensor, &input_scale, &input_zero_point, 1);
get_input_uint8_data(image_file, input_data, img_h, img_w, mean, scale, input_scale, input_zero_point);
/* run graph */
double min_time = DBL_MAX;
double max_time = DBL_MIN;
double total_time = 0.;
for (int i = 0; i < loop_count; i++)
{
double start = get_current_time();
if (run_graph(graph, 1) < 0)
{
fprintf(stderr, "Run graph failed\n");
return -1;
}
double end = get_current_time();
double cur = end - start;
total_time += cur;
if (min_time > cur)
min_time = cur;
if (max_time < cur)
max_time = cur;
}
fprintf(stderr, "\nmodel file : %s\n", model_file);
fprintf(stderr, "image file : %s\n", image_file);
fprintf(stderr, "img_h, img_w, scale[3], mean[3] : %d %d , %.3f %.3f %.3f, %.1f %.1f %.1f\n", img_h, img_w,
scale[0], scale[1], scale[2], mean[0], mean[1], mean[2]);
fprintf(stderr, "Repeat %d times, thread %d, avg time %.2f ms, max_time %.2f ms, min_time %.2f ms\n", loop_count,
num_thread, total_time / loop_count, max_time, min_time);
fprintf(stderr, "--------------------------------------\n");
/* get the result of classification */
tensor_t output_tensor = get_graph_output_tensor(graph, 0, 0);
uint8_t* output_u8 = (uint8_t*)get_tensor_buffer(output_tensor);
int output_size = get_tensor_buffer_size(output_tensor);
/* dequant */
float output_scale = 0.f;
int output_zero_point = 0;
get_tensor_quant_param(output_tensor, &output_scale, &output_zero_point, 1);
float* output_data = (float*)malloc(output_size * sizeof(float));
for (int i = 0; i < output_size; i++)
{
output_data[i] = ((float)output_u8[i] - (float)output_zero_point) * output_scale;
}
// print_topk(output_data, output_size, 5);
// fprintf(stderr, "--------------------------------------\n");
/* release tengine */
free(input_data);
free(output_data);
postrun_graph(graph);
destroy_graph(graph);
release_tengine();
return 0;
}
void show_usage()
{
fprintf(
stderr,
"[Usage]: [-h]\n [-m model_file] [-i image_file]\n [-g img_h,img_w] [-s scale[0],scale[1],scale[2]] [-w "
"mean[0],mean[1],mean[2]] [-r loop_count] [-t thread_count] [-a cpu_affinity]\n");
fprintf(
stderr,
"\nmobilenet example: \n ./classification -m /path/to/mobilenet.tmfile -i /path/to/img.jpg -g 224,224 -s "
"0.017,0.017,0.017 -w 104.007,116.669,122.679\n");
}
int main(int argc, char* argv[])
{
int loop_count = DEFAULT_LOOP_COUNT;
int num_thread = DEFAULT_THREAD_COUNT;
int cpu_affinity = DEFAULT_CPU_AFFINITY;
char* model_file = NULL;
char* image_file = NULL;
float img_hw[2] = {0.f};
int img_h = 0;
int img_w = 0;
float mean[3] = {-1.f, -1.f, -1.f};
float scale[3] = {0.f, 0.f, 0.f};
int res;
while ((res = getopt(argc, argv, "m:i:l:g:s:w:r:t:a:h")) != -1)
{
switch (res)
{
case 'm':
model_file = optarg;
break;
case 'i':
image_file = optarg;
break;
case 'g':
split(img_hw, optarg, ",");
img_h = (int)img_hw[0];
img_w = (int)img_hw[1];
break;
case 's':
split(scale, optarg, ",");
break;
case 'w':
split(mean, optarg, ",");
break;
case 'r':
loop_count = atoi(optarg);
break;
case 't':
num_thread = atoi(optarg);
break;
case 'a':
cpu_affinity = atoi(optarg);
break;
case 'h':
show_usage();
return 0;
default:
break;
}
}
/* check files */
if (model_file == NULL)
{
fprintf(stderr, "Error: Tengine model file not specified!\n");
show_usage();
return -1;
}
if (image_file == NULL)
{
fprintf(stderr, "Error: Image file not specified!\n");
show_usage();
return -1;
}
if (!check_file_exist(model_file) || !check_file_exist(image_file))
return -1;
if (img_h == 0)
{
img_h = DEFAULT_IMG_H;
fprintf(stderr, "Image height not specified, use default %d\n", img_h);
}
if (img_w == 0)
{
img_w = DEFAULT_IMG_W;
fprintf(stderr, "Image width not specified, use default %d\n", img_w);
}
if (scale[0] == 0.f || scale[1] == 0.f || scale[2] == 0.f)
{
scale[0] = DEFAULT_SCALE1;
scale[1] = DEFAULT_SCALE2;
scale[2] = DEFAULT_SCALE3;
fprintf(stderr, "Scale value not specified, use default %.4f, %.4f, %.4f\n", scale[0], scale[1], scale[2]);
}
if (mean[0] == -1.0 || mean[1] == -1.0 || mean[2] == -1.0)
{
mean[0] = DEFAULT_MEAN1;
mean[1] = DEFAULT_MEAN2;
mean[2] = DEFAULT_MEAN3;
fprintf(stderr, "Mean value not specified, use default %.1f, %.1f, %.1f\n", mean[0], mean[1], mean[2]);
}
if (tengine_reid(model_file, image_file, img_h, img_w, mean, scale, loop_count, num_thread, cpu_affinity) < 0)
return -1;
return 0;
}
我看了一下,对应示例,我个人理解,原因可能是默认尺寸是相等的,对应的tensor以及构建gragh,是根据尺寸想等的情况下处理,所以不相等时可能出现异常,而且项目没有对这个异常进行处理(依稀记得虫叔那篇文章提过输入尺寸的规则),更具体的好像要研究一下对应参数,以及run gragh流程了
@LJoson 是的,我尝试了一下khadas自家提供的sdk,它们同样调用的是TIM-VX,没有发现这个问题,应该是Tengine这边出bug了
我看了一下,对应示例,我个人理解,原因可能是默认尺寸是相等的,对应的tensor以及构建gragh,是根据尺寸想等的情况下处理,所以不相等时可能出现异常,而且项目没有对这个异常进行处理(依稀记得虫叔那篇文章提过输入尺寸的规则),更具体的好像要研究一下对应参数,以及run gragh流程了