Inference speed is weird.
I test inference in GeForce 3090 and Jeston TX2. The env of 3090 is
TensorRT Version: 8.4.1.5
NVIDIA GPU: GeForce 3090
CUDA Version: 11.4
CUDNN Version: 8.4.0
Operating System: ubuntu 18.04
The env of TX2 is
TensorRT Version: 7.1.3-1
CUDA Version: 10.2
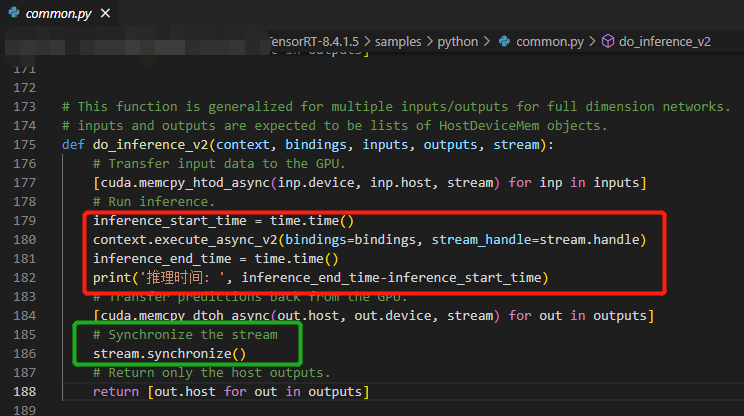
In 3090, I use darknet/yolov3 to inference and the inference time is 0.031s. And I also use yolov3_onnx of Tensorrt samples to inference, but the inference speed, 1.983s, is slower. By the way, the inference time is calculated as follows.
 At the same time,I run the sample, yolov3_onnx of Tensorrt samples in TX2, the inference time is 0.334s. I am very confused, can u help me?
At the same time,I run the sample, yolov3_onnx of Tensorrt samples in TX2, the inference time is 0.334s. I am very confused, can u help me?
Hi @Audrey528 , execute_async_v2() is asynchronous: meaning that it returns immediately without waiting for GPU jobs to complete. Therefore, if your goal is measuring GPU latency, please add a synchronization after execute_async_v2() or use the CUDA event approach.
See our docs for more info about this: https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#measure-performance
@nvpohanh Thanks for your reply. The previous code has added a synchronization after execute_async_v2(). And when I use yolov3_onnx of Tensorrt samples to inference , the occupation of GPU is 1757M, which should provides that used GPU. Am I right. However, when I use darknet/yolov3 to inference, the occupation of GPU is 12789M. I can't find the question.