[BERT/PyTorch] How to get the inference performance with INT8
Related to BERT/PyTorch
Describe the bug:
I want to reproduce the inferencing performance with INT8 on T4 or A2, but I don't know how to reproduce and compare with the inferencing performance NVIDIA updated monthly in following page, could someone give some instructions, thanks.
https://developer.nvidia.com/deep-learning-performance-training-inference
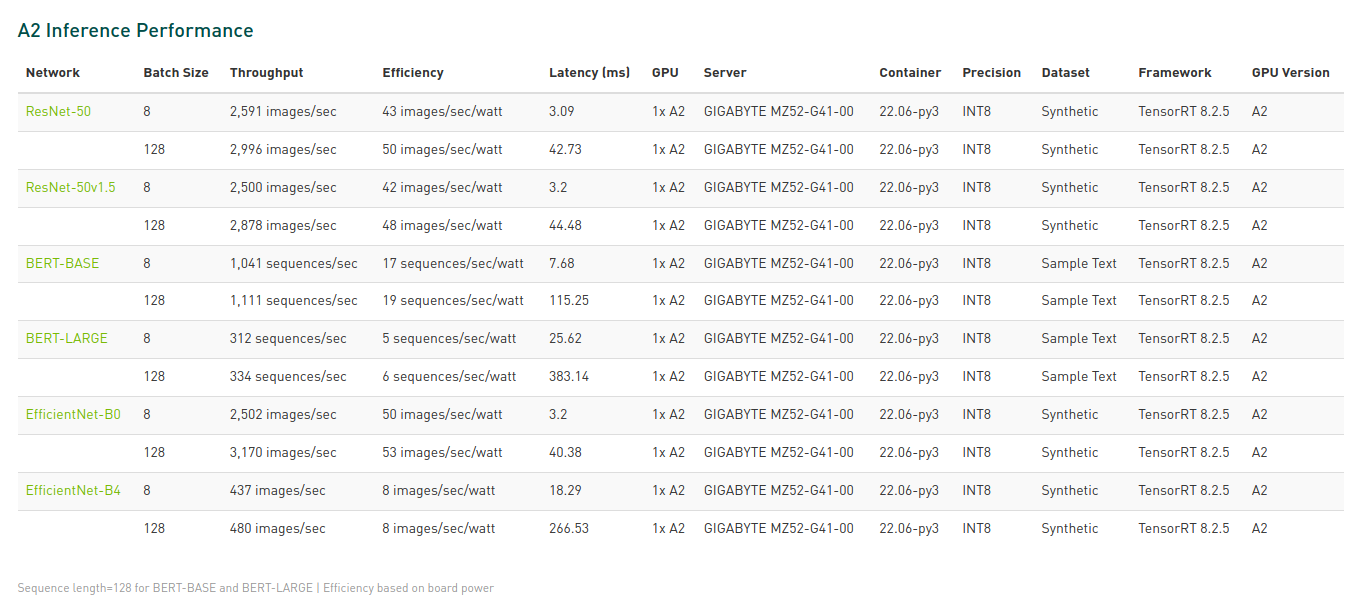
Hi @Zack0617, have you tried following repro instructions in the guide referenced in your link? It says "Reproduce on your systems by following the instructions in the Measuring Training and Inferencing Performance on NVIDIA AI Platforms Reviewer’s Guide"
Hi @mk-nvidia , thank you for your feedback. I have tried following the "Measuring Training and Inferencing Performance on NVIDIA AI Platforms Reviewer’s Guide" before, the Inference Performances precision are FP32 or FP16, so it is not easy to compare with NVIDIA provided as above picture, which is INT8 precision.