Test against original VOC Implementation
I would not use these result in a paper until this implementation is compared with the official VOC implementation.
Sorry, I am not sure to understand, could you give me more precision or some reference? Thank you!
@MathGaron did you ever follow up on this? I am getting different results (lower score) than with the official COCO API (assuming it's the same as VOC). Also the precision in PR curve drops to zero early in most cases (although I do not fully understand the theory of the PR curve)
Example of precision dropping to zero
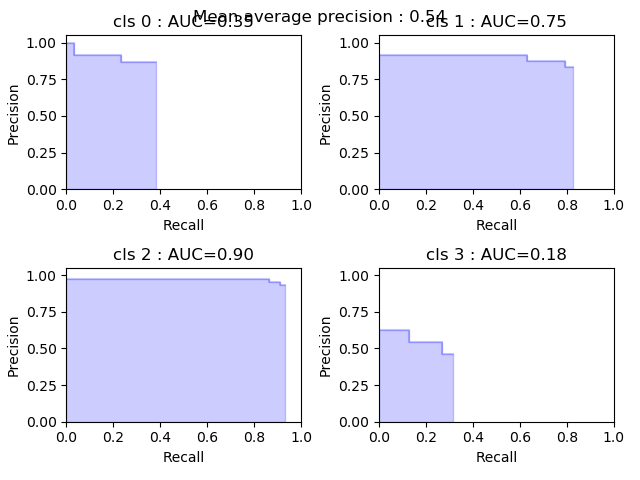
I actually never checked this in details, I am kind of busy with a few projects... I also did not check current coco implementations. It would be awesome if you could provide me some code + samples for the coco evaluation and this evaluation. I could check where my implementation diverges. Also it seems that some people uses this code so I should make it a priority! Thanks for pointing that out, I should have done this before...
I will brush up my PR-curve theory and create an example to check the results against. It is possible that the differences are due to minor differences in the algorithms or possibly how our model is evaluated during training vs after training. Let's see!
The COCO code for mAP score is here https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py (description here)
Awesome thanks so much. I will have some time to check this out in depth next week. Thanks for taking the time to investigate this!
While we did not find an error in this implementation, we discovered a reason for the difference to our existing results. The library we were using, Luminoth, takes all predictions to compute mAP at runtime, then for evaluation the predictions are filtered with confidence > 0.7. If you are interested in their implementation, see calculate_metrics in https://github.com/tryolabs/luminoth/blob/master/luminoth/eval.py
@StephenRUK
Hello,
First of all, thank you for implementing such a useful tool. I am curious if the issues that was brought up previously, precision dropping early & testing with original VOC result have been resolved.
Also relating to the last comment in this thread, I briefly read through calculate_metrics in luminoth but I don't see any filtering related code for predictions with a confidence lower than 0.7.