Is job piping allowed
Hi,
I never used Marquez yet, but I got one question regarding data modeling. Is it allowed to do process piping ? Is it possible to have 2 jobs without an intermediate dataset between them ? In a context where a /scratch workspace can be shared between jobs for examples
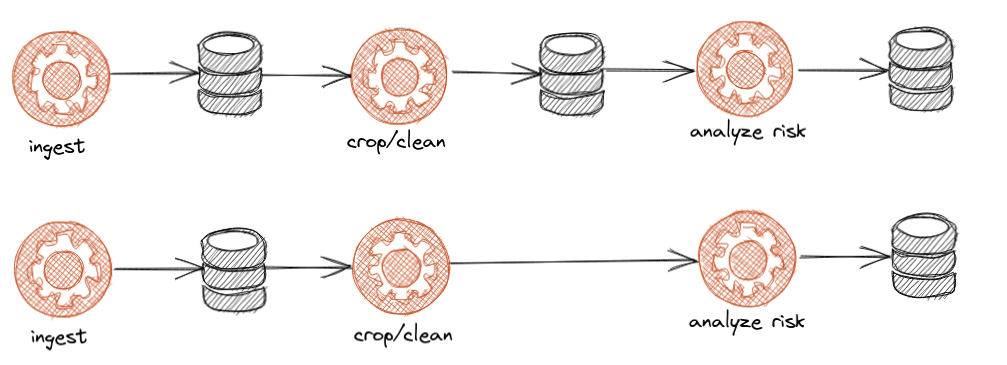
In the current model, that will break lineage. My question to you is, what data is being cropped/cleaned/analyzed in those two middle jobs? Can we model those jobs as reading (and writing to) some common dataset? That would maintain lineage across the entire pipeline
Something like:
analyze risk ➡️ 💾
⬆
Ingest -> 💾 ⬅ ⬅ ⬅
⬇ ⬆
crop/clean ➡ ⬆
Thanks for the answer
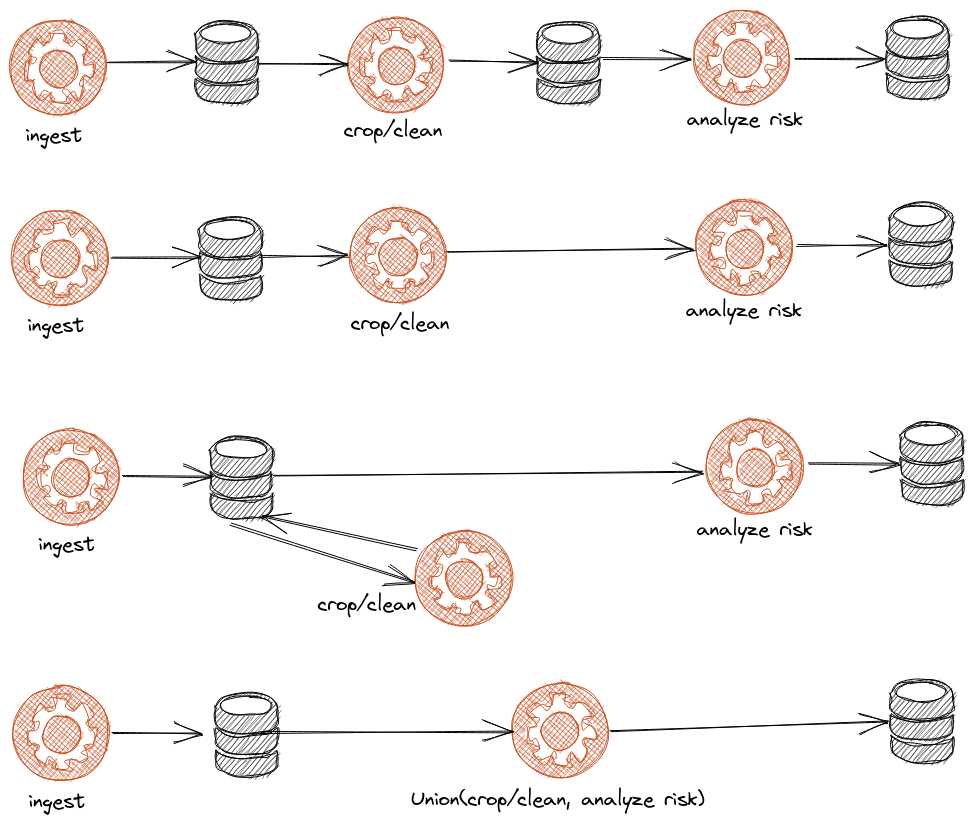
FYI the attached png can be opened in https://excalidraw.com/ for further editing.
I added your proposal, but I am not convinced since the input dataset would not be modified. I would rather suggest modeling that by a new job that would be defined as a Union of two jobs ?