Proposal: Unify `REST` API and `GraphQL` read / write access to database
With the introduction of GraphQL (currently in beta) to easily explore dataset and job metadata collected by Marquez, there has been a considerable drift in the REST API spec and the schema for GraphQL. Keeping both specs aligned will be addressed in a separate proposal, but for now, we'd like to propose a simple solution for reading / writing metadata to / from the Marquez database.
What to consider in our design:
- Dataset and job metadata collected via either the Dataset and Job APIs or the Lineage API (used to collect OpenLineage events) should be stored using a common interface to avoid drift in logic
- When reading collected dataset and job metadata using either the REST API or GraphQL, a common interface should be used to avoid drift in logic but also code duplication
With a common read / write interface to access metadata, there's also the added benefit of maintainability and testability.
How will dataset and job metadata be written / read?
We propose a common DAO class MetadataDao (defined below) that would delegate writes to tables using specific underlying DAOs, but also encapsulate any pre-processing steps:
public interface MetadataDao {
BagOfJobInfo upsertLineageEvent(LineageEvent event);
Namespace upsertNamespaceMeta(NamespaceName namespaceName, NamespaceMeta namespaceMeta);
Dataset upsertDatasetMeta(NamespaceName namespaceName, DatasetName datasetName, DatasetMeta datasetMeta);
Job upsertJob(NamespaceName namespaceName, JobName jobName, JobMeta jobMeta);
.
.
}
What are the benefits?
- Clear interface for inserting rows to database
- Maintainability and testability
- Avoids duplicating row insertion logic
Marquez has a mix of layers- a Resource layer, for the dropwizard request handling, a Service layer, which is inconsistently used, and a DAO layer, which handles all the database I/O operations. A unification of the APIs you mentioned seems like a Service layer proposal, not a DAO one.
This proposal seems like a major refactoring of the existing DAO classes. Is that what you're suggesting? E.g., currently, the OpenLineageDao consumes a LineageEvent and decomposes it into the relevant Marquez model classes. Would that logic be ported to the MetadataDao? If so, are you proposing a single DAO class that has all of the SQL needed to upsert/list/get the various model classes? Or is the MetadataDao more of a composite that delegates to the various underlying DAO (which, again, makes it sound more like a service layer API)?
The OpenLineageDao also has completely different logic for writing the Marquez model classes than what was called from the legacy APIs. Will the OpenLineageDao also be refactored? What does this refactoring ultimately look like?
Very good points, @collado-mike. After some thought, and given that Marquez is the reference implementation of OpenLineage, I think we should deprecate the write APIs for REST. Using the /lineage endpoint to consume OpenLineage events has become the standard way of collecting lineage metadata. For now, we will exclude the deprecation of the /namespace endpoint to continue to allow for ownership assignment and contextual grouping of metadata. At some point, when the ownership model for OpenLineage is more defined, the /namespace endpoint would also be deprecated. Similarly, the /tag endpoint will remain as OpenLineage currently does not supported tags.
To your point, there are inconsistencies in how Services are defined and used. This was a result of the initial phases of prototyping OpenLineage. Most, if not all, services delegate calls to an underlying DAO class. That is, there's a one-to-one relationship between a Service and DAO, resulting an increase of Service classes that don't contain any business logic. I don't think it's unreadable to remove these Service classes and have the Resource layer directly access the DAO layer to reduce codebase size and complexity, while increasing overall readability. We can add Service classes as need when it's clear business logic should be encapsulated.
High-level Design
Deprecating the write APIs for REST ensures there are two clear paths for reading and writing metadata. In the diagram below, calls to the GraphQL endpoint will use on the read path, while calls to REST would use the write path for OpenLineage events and the read path for reading dataset, job, and run metadata.
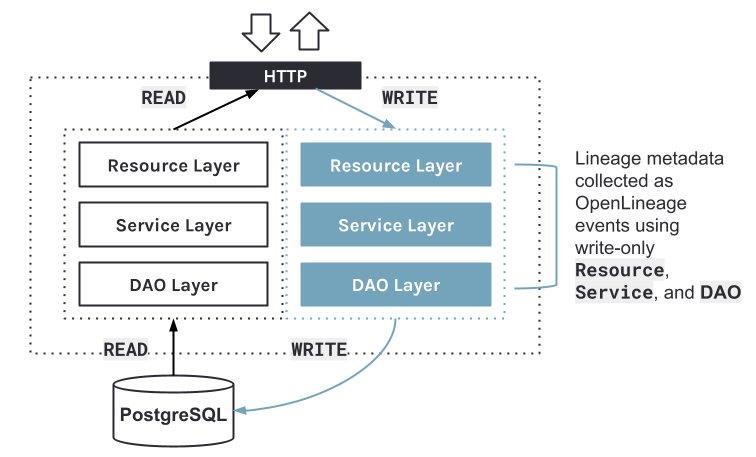
Marquez
read/writepaths to collect / retrieve lineage metadata
Changes by Application Layer
Resource
The read APIs will remain, while the write logic for metadata will be clearly defined. OpenLineage events will be handled and used to store dataset, job, and run metadata in PostgreSQL. The Resource classes will access DAO classes directly to read metadata if no business logic is defined. For example:

Resourceclass accessingDAOclass directly to read dataset metadata
Service
A Service should contain business logic to help with testability. Service classes that delegate a DAO would be removed, with Resource classes accessing DAO classes directly to read metadata. That said, some Service classes will remain. For example, we have an LineageService (used to query lineage metadata) and OpenLineage service (used to process an OpenLineage event). For example:

OpenLineage chain of class invocations to process an
OpenLineageevent
DAO
Encapsulates read and write access to PostgreSQL. We have an OpenLineageDao class that contains logic for dataset and job versioning, while using other DAO classes to write metadata contained within an OpenLineage event to appropriate tables (datasets, jobs, runs, etc).
Next Steps
- Depreciate Dataset Write APIs https://github.com/MarquezProject/marquez/issues/1783
- Depreciate Job Write APIs https://github.com/MarquezProject/marquez/issues/1784
- Depreciate Runs API (in progress, will be removed in Marquez
0.20.0https://github.com/MarquezProject/marquez/pull/1726) - Outline guidelines for when to define a
Serviceand when logic should be self-contained within aResourcehttps://github.com/MarquezProject/marquez/issues/1785 - Outline steps for
GraphQLto useDAOclasses and filter on fields that are only needed (low priority) and models forRESTshould be consistent