Hibernate / resume (and discussing other ideas)
A neat feature that would probably be easier here than a real VM would be dumping memory and state to a hibernate file and allowing the VM to be resumed from that file. Would enable hot migrate of VMs, sleep/wake, etc.
Indeed it is very easy to do for CPU/memory state, and have been done previously for testing sake.
Device suspend is more complicated tho: Devices not only have notion of "state" that can be dumped somewhere
- They also have complex relationship with each other: NVMe is connected into specific PCI slot which also drives specific PLIC interrupt etc, this needs to be tracked & re-created somehow
- There are handles to in-kernel structures (files, sockets, etc) that not always can be properly recreated
Those requirements might be shifted to librvvm user side, and demand building the same machine manually before loading a savefile. For CLI VM this would be very easy since it builds the same machine each time anyways.
Will look into this further, thanks.
Speaking of that, another idea is to allow this to be harnessed and embedded and for the caller to provide callbacks or other interfaces for I/O. That would allow a lightweight linux VM to be embedded as a library into an app without requiring special OS privileges to use hypervisors, etc.
My general thought is that this represents a far simpler and less over-specified and over-engineered approach than the current WASM ecosystem for basically shipping a container as an application. WASM requires that you rebuild everything in this new WASI paradigm while this basically gives you a Linux box with a Linux kernel that you can just run stuff on. You have to rebuild as RISC-V but otherwise it's bog standard Linux. In addition other OSes can be run too if they have RISC-V ports.
With some additional work on the JIT it could probably be at least as fast as WASM too if not faster. The RISC-V instruction set has relatively good code density and if things like vector instructions are supported and properly JITed could take advantage of at least basic vector features in CPUs too.
I have some thoughts about use cases for this in areas like shipping cloud apps to the edge or even the endpoint.
Also please add a sponsorship option if you are serious about this. Will consider sponsoring the project.
Speaking of that, another idea is to allow this to be harnessed and embedded and for the caller to provide callbacks or other interfaces for I/O
There is blk_dev abstraction layer that may be used to replace the default "raw image file" with other image formats / in-ram or remote storage, etc if you meant that.
My general thought is that this represents a far simpler and less over-specified and over-engineered approach than the current WASM ecosystem for basically shipping a container as an application. WASM requires that you rebuild everything in this new WASI paradigm while this basically gives you a Linux box with a Linux kernel that you can just run stuff on. You have to rebuild as RISC-V but otherwise it's bog standard Linux. In addition other OSes can be run too if they have RISC-V ports.
It would also be cool to extend userspace emulation (See #56) and implement some kind of Linux-syscall translation over host primitives. It would work kinda like WSL but with RISC-V binaries as well. This would provide much better performance (Perhaps near-native on generic code) and better integration with the host. Isolation won't be as good however (RVVM as a userspace emulator gives no isolation of process memory).
With some additional work on the JIT it could probably be at least as fast as WASM too if not faster. The RISC-V instruction set has relatively good code density and if things like vector instructions are supported and properly JITed could take advantage of at least basic vector features in CPUs too.
Performance could be much better if running as a userspace emulator as I already said: Most overhead comes not just from the fact that we are translating RISC-V instructions, but from MMU emulation. MMU emulation is a necessity for machine-mode emulation and proper isolation without any requirements from the host.
There are ways for hardware-accelerated MMU emulation without that much overhead, but they ultimately require KVM or some non-portable mmap() hacks, and they are veery complicated. No idea if such thing will be implemented at all, but I hope at some point yes...
JIT improvements are also a good thing but don't expect the perf to skyrocket, at most it'll be somewhere 1.5-2x faster. MMU emulation is really the thing killing the perf here. As for vector JITting: yes, this is planned, but a low priority yet since the ecosystem isn't mature (upstream GCC doesn't even support vectors yet, LLVM support is not stable)
It would also be cool to extend userspace emulation (See https://github.com/LekKit/RVVM/issues/56) and implement some kind of Linux-syscall translation over host primitives. It would work kinda like WSL but with RISC-V binaries as well. This would provide much better performance (Perhaps near-native on generic code) and better integration with the host. Isolation won't be as good however (RVVM as a userspace emulator gives no isolation of process memory).
Might be useful but IMHO having it as a true VM that requires no privileges is what makes it unique. It lets you run containers with no special OS privileges, and if it were like a library it'd allow containerized code to be part of applications. This allows all our "cloud native" code to be reused locally as part of app development.
There's another option to get rid of MMU overhead too. Linux kernels can be built with a dummy MMU (no-mmu) and could then probably be run in RVVM with MMU disabled or an equally "dummy" MMU. This would give you a Linux VM with no memory protection which could still run most apps but would totally crash if anything wrote to an incorrect location in memory. Wouldn't be good for running arbitrary code but might be fine for running curated containerized code and would provide higher performance.
Expanding on the first part above -- what I'm saying is NOT integrating with the host OS is what makes this special. It would allow you to take a containerized Linux application and ship it as a single binary for Linux, macOS, Windows, etc. without requiring special privileges.
There are a million different projects to run containerized code on a managed server, run apps in an architecture-neutral way (e.g. WASM/WASI), etc. Nobody is doing this.
I've been looking for something like this that is well designed and fast for some time with the idea of using it as a basis for a concept I'm toying around with called "progressive cloud apps." (Think progressive web apps but dragging the backend with you.) I don't have time to write such a thing but would absolutely support it if it let us get there.
This could let you do totally insane things like drag a Kubernetes cluster to your desktop. The fact that you run a whole OS in there imposes some overhead but allows all the code to just be reused, which is a big deal. People aren't going to rewrite the universe.
I'm the founder of this whole thing and we have... ideas.
Linux kernels can be built with a dummy MMU (no-mmu)
Most POSIX applications simply don't work under such configuration, sadly. You can't just put nginx or a database there and expect it to work. They also aren't compatible with usual MMU Linux binaries (Need recompile), so that breaks some of your points.
Shortly put my previous explanations: Either there is MMU emulation overhead or no isolation or some help from the host (KVM support) is needed
Hrm... didn't realize that since I have seen people do no-mmu in embedded. I guess they are running only certain application code with that.
In any case my only point is that I wouldn't want you to remove the ability to run a full normal VM in a box. But supporting a usage similar to qemu-user too would be fine and might be useful given that it'd probably be faster than lighter than qemu. If you got the performance really good it would make RISC-V an option as a universal binary format... again simpler and less overwrought than WASM.
WASM was supposed to be our savior but I'm getting icked out by how complex it seems and how it looks like you can almost but not quite just port stuff... or maybe I'm not getting it and maybe the docs are just bad.
Hrm... didn't realize that since I have seen people do no-mmu in embedded. I guess they are running only certain application code with that.
Yes, they are using very primitive subset of Linux APIs. Many things that are defined by POSIX are broken (mmap(), shared memory, proper dynamic linkage) so they use minimal libc instead of glibc and ditch many OS features. It also brings overhead inside the guest itself (which might be a surprise, but virtual memory is a very powerful thing you cannot simply take away).
In any case my only point is that I wouldn't want you to remove the ability to run a full normal VM in a box. But supporting a usage similar to qemu-user too would be fine and might be useful given that it'd probably be faster than lighter than qemu. If you got the performance really good it would make RISC-V an option as a universal binary format... again simpler and less overwrought than WASM.
WASM was supposed to be our savior but I'm getting icked out by how complex it seems and how it looks like you can almost but not quite just port stuff... or maybe I'm not getting it and maybe the docs are just bad.
Full VM emulation always will be there, RVVM just has an optional user emulation API that allows you to load RISC-V code into your process and execute it seamlessly, like a portable bytecode really (And I had the similar idea of RISC-V as a portable bytecode for a long time).
The caveat is that you can't easily isolate it unless you instrument each memory operation & make each host interaction safe. Machine emulation does exactly that because of the MMU, User emulation doesn't even try yet (It only solves binary portability & aims for highest perf possible).
WASM is somewhat similar to user emulation with isolation. They simply use a single host memory buffer as entire heap for the executable so that it cannot touch other host process memory, and for host interaction they implement the whole swarm of system calls themselves. This is important because malicious syscalls are also an attack vector, but this makes "unsafe" syscalls hard to emulate / unsupported at all, and the whole infrastructure is very complicated because of that.
Also please add a sponsorship option if you are serious about this. Will consider sponsoring the project.
I considered this, but I'm questioning myself how to do it properly/ethical in respect to other contributors. If they are OK with that / will simply want some part of it, that's great. Would be a nice way to encourage more people contributing as well)
Beware though, that I don't like GH sponsorship feature much, but perhaps for paying for CI and stuff would be fine. For other use cases I prefer crypto.
Nice, well keep up the great work! I'm very excited about this project as I play with it.
The top thing I'd like to see is the ability to more easily embed it as a library and provide features like:
- My own block storage provider.
- My own network provider, such as via libzt.
- My own display provider / frame buffer
- The ability to suspend/resume or limit the CPU usage of the VM from the application, which might require something special in the JIT code to occasionally check something or similar.
- etc...
As I said, this would make it a viable way for us to explore the idea of "progressive cloud apps" or similar things for edge or endpoint computing.
The hibernate/resume idea would enable hot VM migration around a cluster, which could also be interesting.
My own network provider, such as via libzt.
This is compatible with POSIX sockets somewhat I assume? If you want to put VM guest traffic through such P2P network, that's easily doable (But beware that guests will want to connect with outside world anyways). Perhaps it is possible to directly convert ethernet packets to your P2P network packet format.
My own display provider / frame buffer
See src/devices/framebuffer.h for framebuffer context API. You just need to allocate raw image buffer in memory, then pass it to the guest. For input devices, hid_api is used.
My own block storage provider
Will investigate how to move blk_dev abstractions to public API. Initially they were supposed to be used internally for different image formats, but accessing it from lib side is also great.
Some funky VM suspend/hibernate/pause issues (Monotonic CPU timer was stopped, and the guest doesn't realize real time has passed ever since) Will have to work around that somehow...
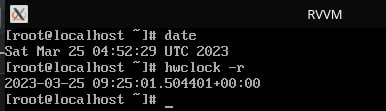
Currently working on blk-dedup which will deduplicate block device contents across multiple VMs for major storage savings. It is also usable for RAM dumps which means saved VM state will be deduplicated against other machines and their storage drives (Aka KSM on disk).
This also means that saving a VM state over previous one would only write back changed data in RAM - idle VMs would just re-hash their RAM content, barely busy ones might write a couple megabytes. One brilliant idea that arises is atomicity across storage & state saves - if you have a power outage, you are rolled back to last VM save both in terms of RAM & storage. It could seamlessly continue where it left off, without a possibility of files/swap/etc being desynced.