Issue when using togethercomputer/GPT-JT-6B-v1
Comparing a GPT-JT vs pythia-6.8B model
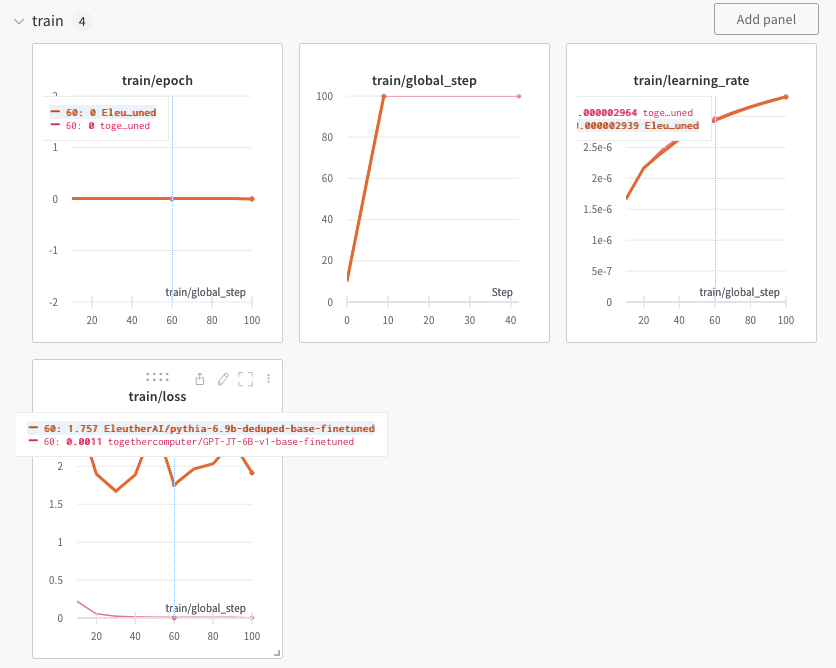
GPT-JT 6B model's training loss is very small, which indicates the model must have using something to "cheat".
Currently I have checked padding and label_mask are working as intended, so I think its likely something is wrong on the casual masking (bidirectional instead of upper triangle ).
Some changes to original get_tokenizer
if tokenizer_config.special_tokens:
if "GPT-JT" in conf.model_name:
tokenizer.add_special_tokens({
'pad_token': tokenizer.eos_token,
'sep_token': tokenizer_config.special_tokens.sep_token
})
...
Config used in configs/config.yaml
defaults:
learning_rate: 1e-5
gradient_checkpointing: false
gradient_accumulation_steps: 32
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
weight_decay: 0.00
warmup_steps: 600
eval_steps: 250
save_steps: 250
max_length: 512
num_train_epochs: 2
logging_steps: 10
max_grad_norm: 2.0
save_total_limit: 4
fp16: true
eval_accumulation_steps:
freeze_layer:
datasets:
- gsm8k_hard
- webgpt
- squad_v2
- adversarial_qa
- private_tuning
- oa_translated
- prosocial_dialogue
- math_qa
- wikihow
- joke
- gsm8k
- ted_trans_en-hi
- ted_trans_de-ja
- ted_trans_nl-en
- ted_trans_en-ja
- ted_trans_en-es
- ted_trans_en-ms
- xsum:
fraction: 0.5
- cnn_dailymail:
fraction: 0.5
- multi_news:
fraction: 0.5
- tldr_news:
fraction: 0.5
- scitldr:
fraction: 0.5
- samsum:
fraction: 0.5
- debate_sum:
fraction: 0.5
- billsum:
fraction: 0.5
- wmt2019_zh-en:
fraction: 0.9
- wmt2019_ru-en:
fraction: 0.9
- wmt2019_de-en:
fraction: 0.9
- wmt2019_fr-de:
fraction: 0.9
- essay_instruction
- reddit_eli5
- reddit_askh
- reddit_asks
cache_dir: /fsx/home-theblackcat02/.cache
loss_fn: CrossEntropyLoss
eval_size:
log_dir: "base"
quantization: false
seq2seqmodel: false
poly_eps: 1.0
fuse_gelu: true
log_wandb: true
samples_mixing: true # uses collator that mixes samples in the batch to create a single sample with possible multiple tasks within
verbose: false
together:
learning_rate: 5e-6
model_name: togethercomputer/GPT-JT-6B-v1
weight_decay: 0.01
max_length: 520
warmup_steps: 1000
gradient_checkpointing: false
gradient_accumulation_steps: 24
per_device_train_batch_size: 3
per_device_eval_batch_size: 6
eval_steps: 100
save_steps: 100
Apply the above changes and you should be able to start training on A100 40G setup
deepspeed trainer_sft.py --configs defaults together --deepspeed
However, I wasn't able to pinpoint the exact issue, but I am pretty sure this is not normal
Hi @theblackcat102 , could you please let me know where we can download Open Assistant private datasets like oa_translated ? Thank you