Feature Request: Add INT8 support
https://huggingface.co/blog/hf-bitsandbytes-integration
As I understand it, this would allow loading 6B models (minus context etc. of course) with 6GB VRAM.
I've implemented this on my machine. My RTX 3080 12GB can now load the Nerys v2 6B model & run it with full 2048 context.
The speed is lower than with FP16 - or at least it seems that way - but far, far faster than breakmodel. The author of BNB commented that newer versions (0.32 for example) would improve the speed, but, unfortunately, transformers only worked with 0.30.0
Basically, it consists of appending load_in_8bit=True to the end of every pipeline. I disabled lazy loader and breakmodel entirely to simplify things.
BNB only works in Linux btw, so use WSL if you're on Windows.
device_map="auto" too or not? I already tried appending those to all the AutoModelForCausalLM.from_pretrained(...) calls, with --nobreakmodel --lowmem, but I'm not seeing any reduction in memory usage. Do you have to add something to the model's config.json too? I'm on Windows but I was able to pip install bitsandbytes and I'm not getting any errors. Are those arguments just silently ignored on Windows? I'll try WSL now.
This is what you need to append.
load_in_8bit=True,
device_map="auto",
and this is the specific version of BNB you need. pip install -i https://test.pypi.org/simple/ bitsandbytes-cudaXXX
bnb-cudaxxx is too old in regular pypi and normal bnb is too new. The command above will install the required version.
Disable lazyloader too. IIRC it conflicts with either 8bit or device_map. It could be made to work, but I couldn't be bothered as CPU ram usage for loading isn't a priority for me.
Got it to work thanks. Disabling lazy loading did it. Now able to fully load 6B models on my 3080 10GB in WSL. Definitely slower than smaller models in fp16 but way faster than 6B with breakmodel. By the way it seems to be working ok for me with Python 3.10.6, PyTorch 1.12.1, Transformers 4.22.1, and regular PyPI bitsandbytes 0.34.0, but I haven't tested extensively.
It should work even faster with the 40 series as they support FP8, so no quantization needed. Just cast to FP8 - when PyTorch adds support for it, of course :)
If it is of any interest: BNB 0.34 actually does work just fine. My issue was apparently a well-known Windows side bug where the driver sets up libcuda.so for WSL incorrectly.
Tried loading 13B on a 4090, failed due to running out of CPU RAM. Hilarious
@green-s Loading OPT 13B is possible (and 20B too, most likely, but I haven't tested):
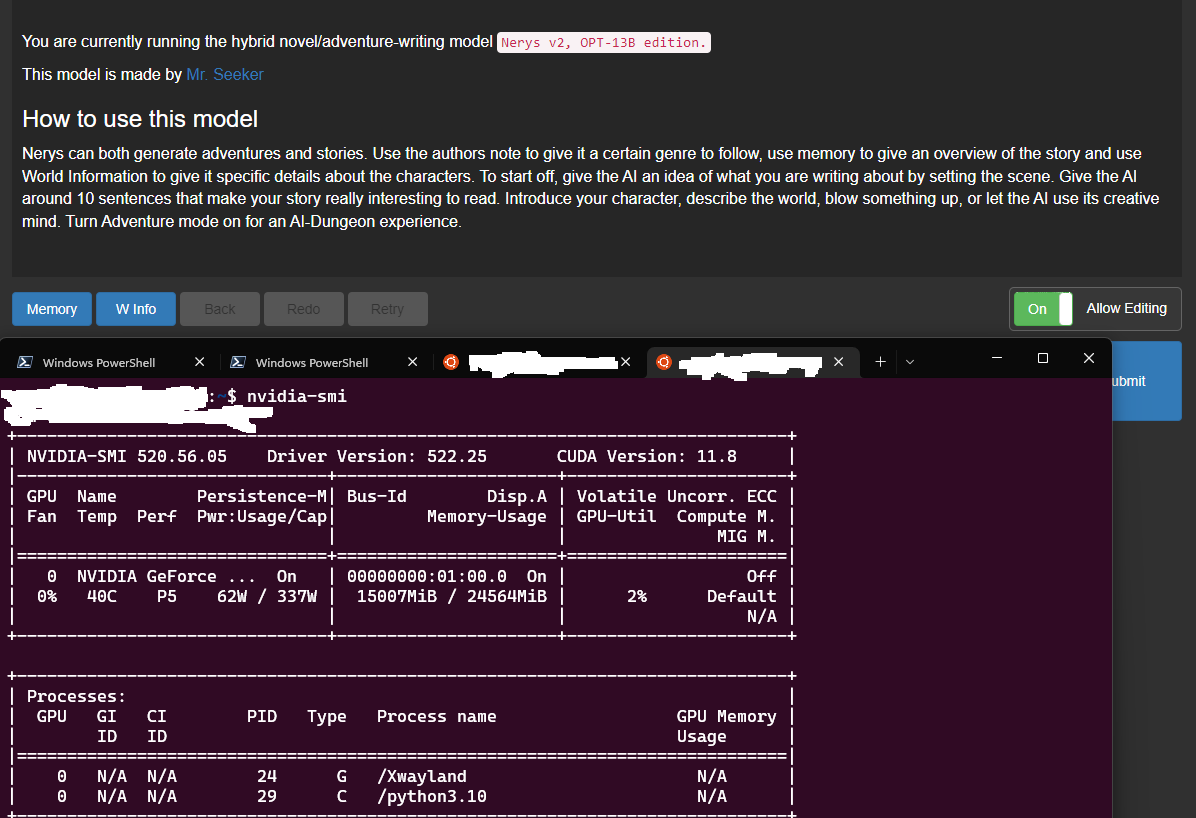
Enough VRAM for 5-gen of 160 tokens.
I have tried adding load_in_8bit=True, device_map="auto" to the relevant
model = AutoModelForCausalLM.from_pretrained
call, and I also can't get it to load the model successfully because the script runs out of CPU RAM. Lazy load is set to false.
I have a RTX 3090 and can load OPT-13B-Erebus normally in my own personal scripts with
model = AutoModelForCausalLM.from_pretrained(f"models/{model_name}", device_map='auto', load_in_8bit=True)
There is something inside KoboldAI that causes it to use much more CPU RAM than the default usage of transformers and AutoModelForCausalLM, even though the function calls are the same.
Any ideas how to fix this? @C43H66N12O12S2
@oobabooga I don't think this works with OPT models unfortunately. When I tried this modification, it only worked for me with GPT-Neo models of which there's a 2.7B model (which I could load without this anyway) and then a massive jump to GPT neo 20B which I can't get working even with this optimization due to not enough RAM or something.
@LoopControl, thanks for your response. I also couldn't find a satisfactory solution, so I increased the size of my swap on Linux to 32 GB. After that, I was able to load and use the model, although the loading process was slow.
Here's a potentially useful page I found that describes steps for running Kobold AI in 8-bit mode:
https://gist.github.com/whjms/2505ef082a656e7a80a3f663c16f4277
Another interesting development that is worth looking into - int4 and int8, supports multi-gpu, splitting gpu/cpu ram, etc:
https://github.com/FMInference/FlexGen
I am wondering if these 4/8 bit models would run well on older Pascal cards, which supported int8 but had very meager support for FP16.
Flexgen is to limiting (Hardcoded OPT models with only a temperature slider), but 8-bit is still being worked on. Flexgen so far I haven't had positive feedback on from the people who tried it, otherwise it can be worth doing with an external program and API.
FWIW, and i may be repeating you here, i'm not sure - it appears that Flexgen can support fine-tuned OPT models, like Erebrus (sp); here's a link to a fellow who is considering submitting a PR against FlexGen to add such support:
https://github.com/FMInference/FlexGen/issues/40
It should work even faster with the 40 series as they support FP8, so no quantization needed. Just cast to FP8 - when PyTorch adds support for it, of course :)
If it is of any interest: BNB 0.34 actually does work just fine. My issue was apparently a well-known Windows side bug where the driver sets up libcuda.so for WSL incorrectly.
You can use FP8 today on 40 series (Ada) with Transformer Engine. It's a bit more involved than just autocast but it supports both PyTorch and JAX/FLAX models today.