Refactor SubqueryIterator and the way we handle multiple index queries
When LimitAdjustingIterator is disabled, limit is given, and there is more than one index query, we progressively execute index queries with proper limit rather than Query.NO_LIMIT. The optimization in average provides better performance, especially when the limit is much smaller than total number of indexed elements.
Closes #2032
As I mentioned in https://github.com/JanusGraph/janusgraph/issues/2032#issuecomment-596083134, this PR tries to reinstate the original query before https://github.com/JanusGraph/janusgraph/pull/481. The difference is this PR tries to estimate the 'appropriate' subLimit in a smarter way and tries to pick up queries that are more likely to be the bottlenecks first. It doesn't mean it is necessarily better than the original logic though.
When only one query is given, or the given limit is infinity, or the LimitAdjustingIterator is enabled, the logic in https://github.com/JanusGraph/janusgraph/pull/481 and https://github.com/JanusGraph/janusgraph/pull/1330 is (mostly) retained. Note that when LimitAdjustingIterator is enabled, we must ensure the order, i.e. limit(i) results = the first i results of limit(j), if i < j. Therefore, we must use the current logic under this circumstance.
There are a few enhancements that can be done in the future, and not included in this PR. I will add more test cases, but before that, I would like to collect some initial feedback.
Thank you for contributing to JanusGraph!
In order to streamline the review of the contribution we ask you to ensure the following steps have been taken:
For all changes:
- [x] Is there an issue associated with this PR? Is it referenced in the commit message?
- [x] Does your PR body contain #xyz where xyz is the issue number you are trying to resolve?
- [x] Has your PR been rebased against the latest commit within the target branch (typically
master)? - [x] Is your initial contribution a single, squashed commit?
For code changes:
- [ ] Have you written and/or updated unit tests to verify your changes?
- [ ] If adding new dependencies to the code, are these dependencies licensed in a way that is compatible for inclusion under ASF 2.0?
- [ ] If applicable, have you updated the LICENSE.txt file, including the main LICENSE.txt file in the root of this repository?
- [ ] If applicable, have you updated the NOTICE.txt file, including the main NOTICE.txt file found in the root of this repository?
For documentation related changes:
- [ ] Have you ensured that format looks appropriate for the output in which it is rendered?
- [ ] If this PR is a documentation-only change, have you added a
[doc only]tag to the first line of your commit message to avoid spending CPU cycles in Travis CI when no code, tests, or build configuration are modified?
Note:
Please ensure that once the PR is submitted, you check Travis CI for build issues and submit an update to your PR as soon as possible.
I wrote a simple program to compare the performance improvement. I used Elasticsearch and Cassandra. The test code is as below:
@Test
public void testMultipleIndexQueryWithHeavyLoad() {
final PropertyKey name = makeKey("name", String.class);
final PropertyKey weight = makeKey("weight", Double.class);
final PropertyKey text = makeKey("text", String.class);
final PropertyKey flag = makeKey("flag", Boolean.class);
final JanusGraphIndex composite1 = mgmt.buildIndex("composite1", Vertex.class).addKey(name).buildCompositeIndex();
final JanusGraphIndex composite2 = mgmt.buildIndex("composite2", Vertex.class).addKey(weight).buildCompositeIndex();
final JanusGraphIndex mixed1 = mgmt.buildIndex("mixed1", Vertex.class).addKey(text, getTextMapping()).buildMixedIndex(INDEX);
final JanusGraphIndex mixed2 = mgmt.buildIndex("mixed2", Vertex.class).addKey(flag).buildMixedIndex(INDEX);
mixed1.name();
mixed2.name();
composite1.name();
composite2.name();
finishSchema();
final int numV = 100000;
final String[] strings = {"houseboat", "humanoid", "differential", "extraordinary"};
final int modulo = 5;
for (int i = 0; i < numV; i++) {
final JanusGraphVertex v = tx.addVertex();
v.property("name", strings[i % 4]);
v.property("text", strings[i % 3]);
v.property("weight", (i % modulo) + 0.5);
v.property("flag", Boolean.valueOf(i % 2 == 0));
}
tx.commit();
long startTimeMs;
long measuredTimeMs;
for (int noOfSubqueries : Arrays.asList(1, 2, 3, 4)) {
System.out.println("############################");
System.out.println("Number of index subqueries is: " + noOfSubqueries);
for (boolean adjustLimit : Arrays.asList(true, false)) {
clopen(option(ADJUST_LIMIT), adjustLimit);
System.out.println("ADJUST_LIMIT is: " + adjustLimit);
for (int limit : Arrays.asList(1, 10, 100, 1000, Query.NO_LIMIT)) {
GraphTraversalSource g = graph.traversal();
startTimeMs = System.currentTimeMillis();
GraphTraversal<Vertex, Vertex> query = g.V().has("name", "houseboat");
if (noOfSubqueries > 1) query = query.has("text", Text.textContains("houseboat"));
if (noOfSubqueries > 2) query = query.has("weight", 0.5);
if (noOfSubqueries > 3) query = query.has("flag", true);
Long count = query.limit(limit).count().next();
measuredTimeMs = System.currentTimeMillis() - startTimeMs;
System.out.println(limit + " limit search time: " + measuredTimeMs + ", count = " + count);
g.tx().rollback();
}
}
}
}
And here are the statistics for running the program above:
LimitAdjustingIterator enabled
Current Algorithm Latency in ms
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | 83 | 31556 | 19241 | 51687 |
| 10 | 5 | 21903 | 19260 | 56719 |
| 100 | 13 | 20877 | 19741 | 54802 |
| 1000 | 70 | 20858 | 20755 | 52204 |
| NO_LIMIT | 727 | 71448 | 20851 | 52170 |
New Algorithm Latency in ms
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | 106 | 27399 | 19824 | 52782 |
| 10 | 8 | 19814 | 19979 | 52543 |
| 100 | 18 | 20103 | 19744 | 51225 |
| 1000 | 76 | 19228 | 19943 | 52541 |
| NO_LIMIT | 586 | 59260 | 19821 | 52287 |
Throughput improvement
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | -21.70% | 15.17% | -2.94% | -2.07% |
| 10 | -37.50% | 10.54% | -3.60% | 7.95% |
| 100 | -27.78% | 3.85% | -0.02% | 6.98% |
| 1000 | -7.89% | 8.48% | 4.07% | -0.64% |
| NO_LIMIT | 24.06% | 20.57% | 5.20% | -0.22% |
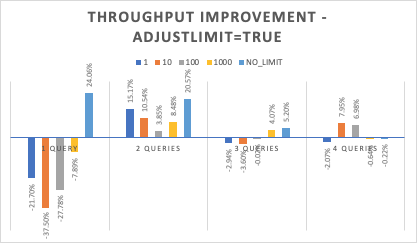
Basically, the logic is almost the same as the current logic when LimitAdjustingIterator is enabled, thus the performances are almost the same.
Note that currently LimitAdjustingIterator is essentially 'enabled' only when the given limit is Query.NO_LIMIT, as shown below:
https://github.com/JanusGraph/janusgraph/blob/c01bfea2ce602696163aa50fde9be1cdeea13fc1/janusgraph-core/src/main/java/org/janusgraph/graphdb/query/graph/GraphCentricQueryBuilder.java#L356-L358
Thus, theoretically, we have to ensure the order and (thus use the old logic) ONLY when 'smart-limit' is enabled, and when the limit is Query.NO_LIMIT. In other words, ideally, the performance improvement here should be the same as the improvement shown in the next section when limit is not Query.NO_LIMIT. However, this would require changes to more files or more refactoring, thus I am not including this improvement in this PR, but I can do if requested.
LimitAdjustingIterator disabled
Current Algorithm Latency in ms
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | 40 | 21976 | 20084 | 51594 |
| 10 | 8 | 19461 | 19498 | 51003 |
| 100 | 8 | 19243 | 19803 | 52355 |
| 1000 | 18 | 20029 | 19807 | 51816 |
| NO_LIMIT | 217 | 22600 | 21265 | 51955 |
New Algorithm Latency in ms
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | 35 | 2861 | 20699 | 2226 |
| 10 | 7 | 3624 | 20074 | 22451 |
| 100 | 7 | 21123 | 25991 | 51887 |
| 1000 | 15 | 28149 | 19918 | 52550 |
| NO_LIMIT | 198 | 19805 | 18752 | 53373 |
Throughput improvement
| Limit | 1 query | 2 queries | 3 queries | 4 queries |
|---|---|---|---|---|
| 1 | 14.29% | 668.12% | -2.97% | 2217.79% |
| 10 | 14.29% | 437.00% | -2.87% | 127.17% |
| 100 | 14.29% | -8.90% | -23.81% | 0.90% |
| 1000 | 20.00% | -28.85% | -0.56% | -1.40% |
| NO_LIMIT | 9.60% | 14.11% | 13.40% | -2.66% |
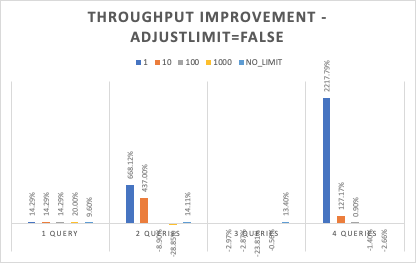
The improvement can be huge when the limit is small.
I only ran the program on my laptop once, so the statistics above are just for reference only. I would be happy to run more tests if any other specific use case is suggested by reviewers.
 Here is an overview of what got changed by this pull request:
Here is an overview of what got changed by this pull request:
Complexity increasing per file
==============================
- janusgraph-core/src/main/java/org/janusgraph/graphdb/util/SubqueryIterator.java 7
See the complete overview on Codacy