Evaluate a better algorithm for the check scheduler logic
Is your feature request related to a problem? Please describe.
How our checks scheduler works:

Describe the solution you'd like
How our checks scheduler shall work:

Describe alternatives you've considered
None.
Additional context
A lot of checks run every 5m, but they don't have to run exactly every 5m.
Tasks
- [ ] Complete your current tasks not related to this issue
- [ ] Design an algorithm ~(yes, structure charts on paper! 😜)~ how Icinga shall transform the situation shown in the first picture into the one shown in the second picture (keep in mind that there are different check intervals – 1s-24h, different retry intervals and hosts/services may be added/removed at run time)
- [ ] Present that algo @lippserd and me and get green light from us
- [ ] Implement that check scheduler "on the green meadow" (not in Icinga 2) ~in Go~
Shouldn't this already be handled by Checkable::GetSchedulingOffset() (which might not work as expected, I didn't try anything in this regard, I just know that it exists in the code)?
We have worked on a concept, but nothing related to Icinga code itself, and this issue isn't being currently worked on.
Hi, I recently stumbled over the scheduling algorithm because of an (for us at least) unexpected behaviour.
While the reason for this Issue here, an even distribution of checks over time, is a important concern, there is another aspect resulting from the current algorithm: the measured interval between checks is often. almost always, less than the check_interval defined. I did collect some data on this, and the measured interval is usually (median) within 1% of the configured check_interval, but a difference of up to 5% is possible under normal circumstances.
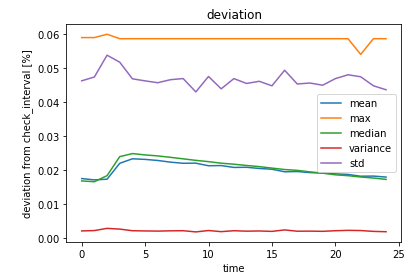 (Diagram 1: Summary of deviation of all checks over time, approx. 3 hours. When deviation=0, measured interval=check_interval. deviation=0.05, means a deviation of 5%)
(Diagram 1: Summary of deviation of all checks over time, approx. 3 hours. When deviation=0, measured interval=check_interval. deviation=0.05, means a deviation of 5%)
As you can see above, there is a mechanism which reduces the deviation over time, but I have yet to understand this better.
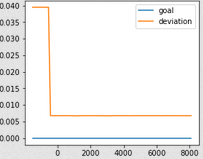 (Diagram 2: Example of a check where the measured interval arbitrarily gets closer to the configured interval. 0.01=1% deviation.)
(Diagram 2: Example of a check where the measured interval arbitrarily gets closer to the configured interval. 0.01=1% deviation.)
The time and height of this "step" seems to be arbitrary and both are different for each check. Some checks don't change their deviation at all. Since this behaviour happens randomly to some checks, the average deviation overall gets smaller over time. The descrease stalls after some time, but I only have one datapoint for this yet. (16 hours)
While all of this is probably not a problem in most cases, it would be pleasing to have an algorithm that aims for the configured check_interval instead of creating an unpredictable interval on it's own. Maybe even make the execution times (more) predictable...
Also, while evaluating the data, I found out that the distribution of checks over a minute is not as imbalanced as suggestest in the original comment.
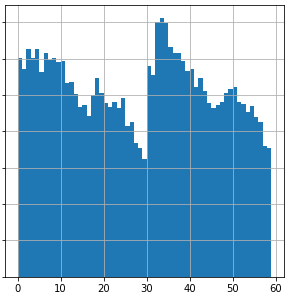 (Diagram 3: Distribution of executed checks over any minute. Each bin is 1 second.)
(Diagram 3: Distribution of executed checks over any minute. Each bin is 1 second.)
Each bar represents the sum of checks executed in that second of an minute. Since this is the sum over several minutes, it is possible that some minutes are significantly more imbalanced than others. I will try to find out more about this.
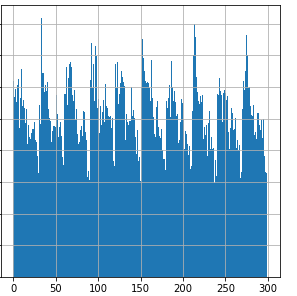 (Diagram 4: Distribution of executed checks over 5 minutes, each bin is 1 second.)
(Diagram 4: Distribution of executed checks over 5 minutes, each bin is 1 second.)
This is the same data over 5 minutes. You can see that the underlying frequency seems to be 30 seconds. I am currently trying to understand this. The nature of the current algorithm therefore seems to balance the execution already. I think this is because the algortihm assigns somwhat-random intervals, slightly smaller than the check_interval. This sum of random frequencies prevents the "resonance" of checks described in the first post.
While I pointed out that the scheduler actually doesn't seem to have the problem described in this issue, to the expected extend, I'm currently thinking about how one could improve the scheduling and I do have some ideas. I'm open to share further data and maybe discuss some ideas surrounding this. There also could be a misinterpretation of the data I collected on my side.
I'm looking into testing some algorithms myself, but this is the first time working on a application of this size, so I'm not sure how much time this will take :)
The data here is based on a low 5-digit count of service checks. There are 8 check_intervals used, all of them a multiple of 60s, most of them also multiples of each other. (5m,10m,60m,12h,1d)
I did some further digging into the current algorithm and I think I found the reason for the underlying behaviour. I will try to explain it, so everyone has a basic (or deeper) understanding. The algorithm relies on the following parameters:
- Interval, either
checkIntervalorretryInterval, depending on state. (I will usecheckIntervalfor both for now) - current time. This will be after the check execution started, but not after the execution is done. (I think)
- scheduling offset. A random number generated at startup (will be different after each deployment or restart) Also documented here
note: the "Initial Check", while similar, is only done once after startup.
lastCheck is not used. Therefore, it is already unlikely that we match the check interval to the second at any point.
A simplified way of the calculation is nextCheck = now + interval. This would be more than the checkInterval though, since the nextCheck is calculated after execution (start?) of the previous check. nextCheck would be as late as interval + computing + queing. This could add some time, which wouldn't be great for smaller interval checks. On the other hand, I don't think it would be longer than a few seconds at most, in the worst of cases.
(I am not 100% sure about this part. I am not sure when the calculation is executed.)
To mitigate this, two calculations for a adjust, short adj, value are made. Both are (almost) always calculated. The smaller result is used and will be inserted into the following calculation: nextCheck = now - adj + interval. The smaller adj is, the later nextCheck will be. Since lastCheck is already in the past, we want to roughly cover the time between lastCheck and now, but if adj is too big, we will execute the check earlier, therefore more often, than needed.
- Calculation I. is based on the current timestamp, the
schedulingOffsetand thecheckInterval.adj = fmod(now * 100 + GetSchedulingOffset(), interval * 100) / 100.0;The modulo operations limits the maximum value of this to be smaller thaninterval. But it could be almost as big as theintervalitself, which would mean there is a chance that thenextCheckis executed almost instantly. - Calculation II. is a more basic operation
0.5 + fmod(GetSchedulingOffset(), interval * 5) / 100.0This time, the modulo calculation limits the value to be smaller than 5% of thecheckInterval. The calculation is based on theSschedulingOffsetand the numeric value0.5. It is rather crude, but probably is okay for more than 90% of checks in a standard environment.
Therefore the nextCheck is, assuming an executionTime of 0, at earliest now - 0.5 - interval*0.05 + checkInterval (assuming Calculation I. is the same as Calculation II.). And that is exactly what one can see in my data, checks can have an measuredInterval up to 5-and-a-bit% of checkInterval (I have to admit, I am a bit proud I got this :D)
What I did notice is that Calculation I. method gets overwritten very often, even though it is the more complicated one. While Calculation I. could be as high as checkInterval, the second one is always up to 5% + 0.5s or less.
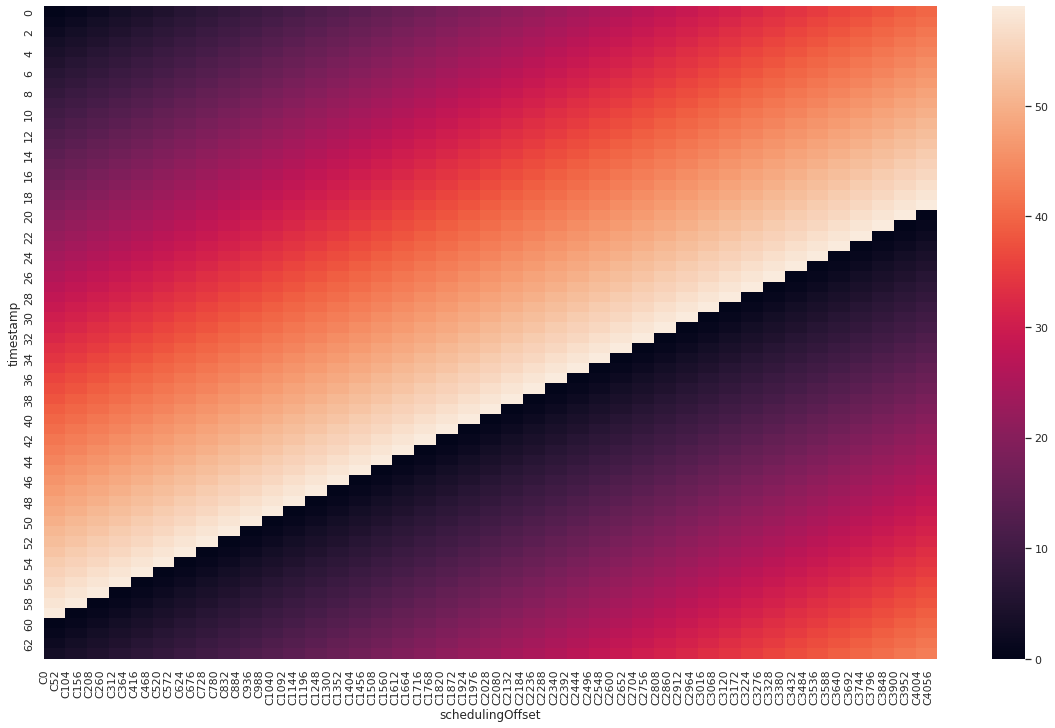 (Diagram 1: Heatmap of adj values with the first method)
(Diagram 1: Heatmap of adj values with the first method)
Here you can see a small part of possible values of Calculation I.. A significant portion of the values is greater than Calculation II. Interval is 60 here, 5% are 3, add 0.5 and every value greater than 3.5 is always ignored. Remember, thesmaller value is used always.
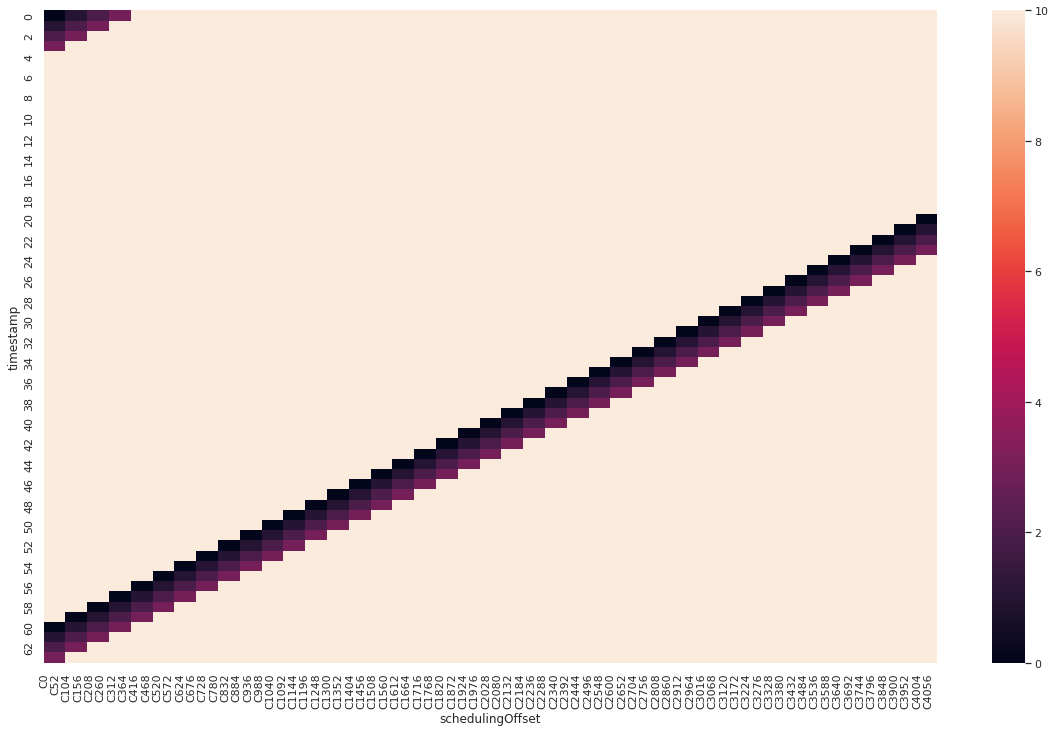 (Diagram 2: Same as 1, but the combinations, when the value is not used, are set to 10)
(Diagram 2: Same as 1, but the combinations, when the value is not used, are set to 10)
And here you can see in which cases Calculation I. is used. It is, you guessed it, around 5%. Even in those 5% of cases, there is a chance that Calculation II. is used instead, because Calculation II. could still be smaller than Calculation I.
In the other 95% of cases, Calculation II. is used to get an adj value in the 5% range.
Given all of this, and I could be wrong here, Calculation I. has probably a very limited use. My gut says it is used more, when the checkInterval is shorter, but I am not quite sure.
The not quite 30 lines, where this calculation is made, can be found here
After talking to a colleague, he rightly asked "Is it so bad?". In general, I have to agree. We noticed it because we have a check that should not have been made the way it is and can't handle the deviation. But the current algorithm is still not the best way to handle it in my opinion.
After startup, the "Initial Check" Phase is only one minute long. All Checks during that phase will be executed in the following minute, additionally to the ones scheduled. This "block" will randomly distribute over time again, but it seems that this doesn't work too good. (See distribution of checks over time, but I also checked this and it doesn't seem to improve over time. I can provide more data on this.) To conclude this, I think there is a way to ensure three of the goals the scheduling has:
- Adhering to the
checkIntervalto the second - Distributing checks evenly over time
- Recovering from different states
Therefore I propose scheduling based on the schedulingOffset and lastCheck instead. I'm looking into testing an algorithm soon and will get back when I have some results.