Multi-page annotation ML backend
I want to make with ~8 images at once This is the view I want to use, how can I modify the tesseract.py API backend for ML-assisted labeling of the example? The biggest problem I'm facing is finding the idx of the image and returning the result This is urgent, please help me :(
<View>
<Repeater on="$document" indexFlag="{{idx}}" mode="pagination">
<Image name="page_{{idx}}" value="$document[{{idx}}].page" inline="true"/>
<Labels name="labels_{{idx}}" toName="page_{{idx}}">
<Label value="Text" background="green"/>
<Label value="Handwriting" background="blue"/>
</Labels>
<Rectangle name="bbox_{{idx}}" smart="true" toName="page_{{idx}}" strokeWidth="3"/>
<TextArea name="transcription_{{idx}}" toName="page_{{idx}}"
editable="true"
perRegion="true"
required="true"
maxSubmissions="1"
rows="5"
placeholder="Recognized Text"
displayMode="region-list"
/>
<View style="display: flex; justify-content: center;">
<Header value=" Rate this page:"/>
<Rating name="rating_{{idx}}" toName="page_{{idx}}"/>
</View>
</Repeater>
</View>
<!-- {
"document": [
{
"page": "https://htx-pub.s3.amazonaws.com/demo/images/demo_stock_purchase_agreement/0001.jpg"
},
{
"page": "https://htx-pub.s3.amazonaws.com/demo/images/demo_stock_purchase_agreement/0002.jpg"
},
{
"page": "https://htx-pub.s3.amazonaws.com/demo/images/demo_stock_purchase_agreement/0003.jpg"
}
]
} -->
Hi @quangvhhe140489 You need to change this line to much your config. Just check annotation created manually and make your prediction alike.
@KonstantinKorotaev
Yes, I see, I need to change the name to "transcription_1" for page 1. However, how can I get the page I'm annotating?
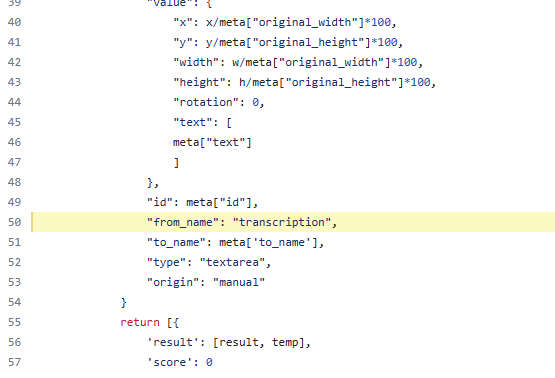
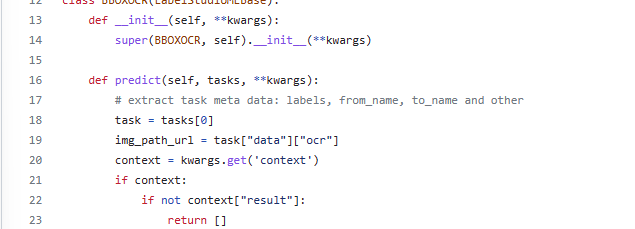 The second thing I need to change is the img_path_url to task["data"]["document"]["page"][idx], right?
The second thing I need to change is the img_path_url to task["data"]["document"]["page"][idx], right?
I'm ok with the manually creation of the annotation, but the input data to the tesseract model with me, it seems a hidden box.
I have tried multiple times, however, the idx I get from the kwargs.get("context") not stable when sometimes I got, another time, I get None :(
I have tried multiple times, however, the idx I get from the kwargs.get("context") not stable when sometimes I got, another time, I get None :(
That's weird, could you please send several examples?
@quangvhhe140489 To answer your question below:
"how can I get the page I'm annotating?"
My answer:
idx = context.get('result')[-1]['to_name'].split("_")[-1]
so you get the page idx you are annotating