Dataflow job (BiqQuery to Elasticsearch) timeouts and aborts the execution
Related Template(s)
BigQuery to Elasticsearch
What happened?
I've created an index pipeline by leveraging the Dataflow template (flex) for BigQuery -> Elasticsearch. The goal is to index the patent dataset which is made available by Google Cloud in BigQuery. I was able to ingest some hundred thousand records after the Dataflow job breaks reporting timeout on the Elasticsearch side. I do not see any errors reported by Elasticsearch through the Elastic Cloud console. Increasing maxRetryAttempts=9, maxRetryDuration=299999 in the Dataflow configuration did not help.
Beam Version
Newer than 2.35.0
Relevant log output
{
"textPayload": "Error message from worker: java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-1 [ACTIVE]\n\torg.elasticsearch.client.RestClient.extractAndWrapCause(RestClient.java:834)\n\torg.elasticsearch.client.RestClient.performRequest(RestClient.java:259)\n\torg.elasticsearch.client.RestClient.performRequest(RestClient.java:246)\n\tcom.google.cloud.teleport.v2.elasticsearch.utils.ElasticsearchIO$Write$WriteFn.flushBatch(ElasticsearchIO.java:1502)\n\tcom.google.cloud.teleport.v2.elasticsearch.utils.ElasticsearchIO$Write$WriteFn.processElement(ElasticsearchIO.java:1462)\nCaused by: java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-1 [ACTIVE]\n\torg.apache.http.nio.protocol.HttpAsyncRequestExecutor.timeout(HttpAsyncRequestExecutor.java:387)\n\torg.apache.http.impl.nio.client.InternalIODispatch.onTimeout(InternalIODispatch.java:92)\n\torg.apache.http.impl.nio.client.InternalIODispatch.onTimeout(InternalIODispatch.java:39)\n\torg.apache.http.impl.nio.reactor.AbstractIODispatch.timeout(AbstractIODispatch.java:175)\n\torg.apache.http.impl.nio.reactor.BaseIOReactor.sessionTimedOut(BaseIOReactor.java:261)\n\torg.apache.http.impl.nio.reactor.AbstractIOReactor.timeoutCheck(AbstractIOReactor.java:502)\n\torg.apache.http.impl.nio.reactor.BaseIOReactor.validate(BaseIOReactor.java:211)\n\torg.apache.http.impl.nio.reactor.AbstractIOReactor.execute(AbstractIOReactor.java:280)\n\torg.apache.http.impl.nio.reactor.BaseIOReactor.execute(BaseIOReactor.java:104)\n\torg.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor$Worker.run(AbstractMultiworkerIOReactor.java:591)\n\tjava.lang.Thread.run(Thread.java:748)\n",
"insertId": "o524g1d13xt",
"resource": {
"type": "dataflow_step",
"labels": {
"project_id": "1059491012611",
"job_name": "dmarx-patent-pubs",
"step_id": "",
"region": "europe-west3",
"job_id": "2022-08-21_12_40_52-600920110293958641"
}
},
"timestamp": "2022-08-21T20:05:24.492885100Z",
"severity": "ERROR",
"labels": {
"dataflow.googleapis.com/log_type": "system",
"dataflow.googleapis.com/region": "europe-west3",
"dataflow.googleapis.com/job_name": "dmarx-patent-pubs",
"dataflow.googleapis.com/job_id": "2022-08-21_12_40_52-600920110293958641"
},
"logName": "projects/[PROJECTNAME_REMOVED]/logs/dataflow.googleapis.com%2Fjob-message",
"receiveTimestamp": "2022-08-21T20:05:24.877736908Z"
}
and
{
"textPayload": "Error message from worker: java.io.IOException: Failed to advance reader of source: name: \"projects/[PROJECTNAME_REMOVED]/locations/us/sessions/CAISDFNVczdaN1RRQzE5UhoCamQaAmpj/streams/CAEaAmpkGgJqYygC\"\n\n\torg.apache.beam.runners.dataflow.worker.WorkerCustomSources$BoundedReaderIterator.advance(WorkerCustomSources.java:625)\n\torg.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation$SynchronizedReaderIterator.advance(ReadOperation.java:425)\n\torg.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation.runReadLoop(ReadOperation.java:211)\n\torg.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation.start(ReadOperation.java:169)\n\torg.apache.beam.runners.dataflow.worker.util.common.worker.MapTaskExecutor.execute(MapTaskExecutor.java:83)\n\torg.apache.beam.runners.dataflow.worker.BatchDataflowWorker.executeWork(BatchDataflowWorker.java:420)\n\torg.apache.beam.runners.dataflow.worker.BatchDataflowWorker.doWork(BatchDataflowWorker.java:389)\n\torg.apache.beam.runners.dataflow.worker.BatchDataflowWorker.getAndPerformWork(BatchDataflowWorker.java:314)\n\torg.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.doWork(DataflowBatchWorkerHarness.java:140)\n\torg.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.call(DataflowBatchWorkerHarness.java:120)\n\torg.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.call(DataflowBatchWorkerHarness.java:107)\n\tjava.util.concurrent.FutureTask.run(FutureTask.java:266)\n\tjava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\n\tjava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\n\tjava.lang.Thread.run(Thread.java:748)\nCaused by: com.google.api.gax.rpc.FailedPreconditionException: io.grpc.StatusRuntimeException: FAILED_PRECONDITION: there was an error operating on 'projects/[PROJECTNAME_REMOVED]/locations/us/sessions/CAISDFNVczdaN1RRQzE5UhoCamQaAmpj/streams/CAEaAmpkGgJqYygC': session expired at 2022-08-22T01:44:03+00:00\n\tcom.google.api.gax.rpc.ApiExceptionFactory.createException(ApiExceptionFactory.java:59)\n\tcom.google.api.gax.grpc.GrpcApiExceptionFactory.create(GrpcApiExceptionFactory.java:72)\n\tcom.google.api.gax.grpc.GrpcApiExceptionFactory.create(GrpcApiExceptionFactory.java:60)\n\tcom.google.api.gax.grpc.ExceptionResponseObserver.onErrorImpl(ExceptionResponseObserver.java:82)\n\tcom.google.api.gax.rpc.StateCheckingResponseObserver.onError(StateCheckingResponseObserver.java:86)\n\tcom.google.api.gax.grpc.GrpcDirectStreamController$ResponseObserverAdapter.onClose(GrpcDirectStreamController.java:149)\n\tio.grpc.PartialForwardingClientCallListener.onClose(PartialForwardingClientCallListener.java:39)\n\tio.grpc.ForwardingClientCallListener.onClose(ForwardingClientCallListener.java:23)\n\tio.grpc.ForwardingClientCallListener$SimpleForwardingClientCallListener.onClose(ForwardingClientCallListener.java:40)\n\tio.grpc.census.CensusStatsModule$StatsClientInterceptor$1$1.onClose(CensusStatsModule.java:802)\n\tio.grpc.PartialForwardingClientCallListener.onClose(PartialForwardingClientCallListener.java:39)\n\tio.grpc.ForwardingClientCallListener.onClose(ForwardingClientCallListener.java:23)\n\tio.grpc.ForwardingClientCallListener$SimpleForwardingClientCallListener.onClose(ForwardingClientCallListener.java:40)\n\tio.grpc.census.CensusTracingModule$TracingClientInterceptor$1$1.onClose(CensusTracingModule.java:428)\n\tio.grpc.internal.DelayedClientCall$DelayedListener$3.run(DelayedClientCall.java:463)\n\tio.grpc.internal.DelayedClientCall$DelayedListener.delayOrExecute(DelayedClientCall.java:427)\n\tio.grpc.internal.DelayedClientCall$DelayedListener.onClose(DelayedClientCall.java:460)\n\tio.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:562)\n\tio.grpc.internal.ClientCallImpl.access$300(ClientCallImpl.java:70)\n\tio.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInternal(ClientCallImpl.java:743)\n\tio.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:722)\n\tio.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)\n\tio.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:133)\n\t... 3 more\n\tSuppressed: java.lang.RuntimeException: Asynchronous task failed\n\t\tat com.google.api.gax.rpc.ServerStreamIterator.hasNext(ServerStreamIterator.java:105)\n\t\tat org.apache.beam.sdk.io.gcp.bigquery.BigQueryStorageStreamSource$BigQueryStorageStreamReader.readNextRecord(BigQueryStorageStreamSource.java:211)\n\t\tat org.apache.beam.sdk.io.gcp.bigquery.BigQueryStorageStreamSource$BigQueryStorageStreamReader.advance(BigQueryStorageStreamSource.java:206)\n\t\tat org.apache.beam.runners.dataflow.worker.WorkerCustomSources$BoundedReaderIterator.advance(WorkerCustomSources.java:622)\n\t\tat org.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation$SynchronizedReaderIterator.advance(ReadOperation.java:425)\n\t\tat org.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation.runReadLoop(ReadOperation.java:211)\n\t\tat org.apache.beam.runners.dataflow.worker.util.common.worker.ReadOperation.start(ReadOperation.java:169)\n\t\tat org.apache.beam.runners.dataflow.worker.util.common.worker.MapTaskExecutor.execute(MapTaskExecutor.java:83)\n\t\tat org.apache.beam.runners.dataflow.worker.BatchDataflowWorker.executeWork(BatchDataflowWorker.java:420)\n\t\tat org.apache.beam.runners.dataflow.worker.BatchDataflowWorker.doWork(BatchDataflowWorker.java:389)\n\t\tat org.apache.beam.runners.dataflow.worker.BatchDataflowWorker.getAndPerformWork(BatchDataflowWorker.java:314)\n\t\tat org.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.doWork(DataflowBatchWorkerHarness.java:140)\n\t\tat org.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.call(DataflowBatchWorkerHarness.java:120)\n\t\tat org.apache.beam.runners.dataflow.worker.DataflowBatchWorkerHarness$WorkerThread.call(DataflowBatchWorkerHarness.java:107)\n\t\tat java.util.concurrent.FutureTask.run(FutureTask.java:266)\n\t\t... 3 more\nCaused by: io.grpc.StatusRuntimeException: FAILED_PRECONDITION: there was an error operating on 'projects/[PROJECTNAME_REMOVED]/locations/us/sessions/CAISDFNVczdaN1RRQzE5UhoCamQaAmpj/streams/CAEaAmpkGgJqYygC': session expired at 2022-08-22T01:44:03+00:00\n\tio.grpc.Status.asRuntimeException(Status.java:535)\n\t... 21 more\n",
"insertId": "o524g1d13xw",
"resource": {
"type": "dataflow_step",
"labels": {
"step_id": "",
"job_id": "2022-08-21_12_40_52-600920110293958641",
"job_name": "dmarx-patent-pubs",
"project_id": "1059491012611",
"region": "europe-west3"
}
},
"timestamp": "2022-08-22T01:44:31.742062353Z",
"severity": "ERROR",
"labels": {
"dataflow.googleapis.com/log_type": "system",
"dataflow.googleapis.com/job_name": "dmarx-patent-pubs",
"dataflow.googleapis.com/job_id": "2022-08-21_12_40_52-600920110293958641",
"dataflow.googleapis.com/region": "europe-west3"
},
"logName": "projects/[PROJECTNAME_REMOVED]/logs/dataflow.googleapis.com%2Fjob-message",
"receiveTimestamp": "2022-08-22T01:44:32.337830356Z"
}
Are you using appropriate sharding on Elasticsearch? Are the instances sizes/heap memory enough to handle the inflow? (Please note that patent dataset can be a couple of TB, depending on the tables that you are importing)
Take a look at https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html, as it may have some good tips.
Disabling the refresh (or changing index.refresh_interval to be much higher than the default), or even disabling the replicas during the load, if possible, can be a good idea.
Did you notice any pattern on the scaling of Dataflow workers and timeouts on Elasticsearch? An alternative, on the template side, would be to set Max workers to a smaller number.
Seening the same issue. Job churns along happy for a few hours and then suddenly just dies with all workers getting timeout exceptions on Elastic Search Write. No error reported in ES logs.
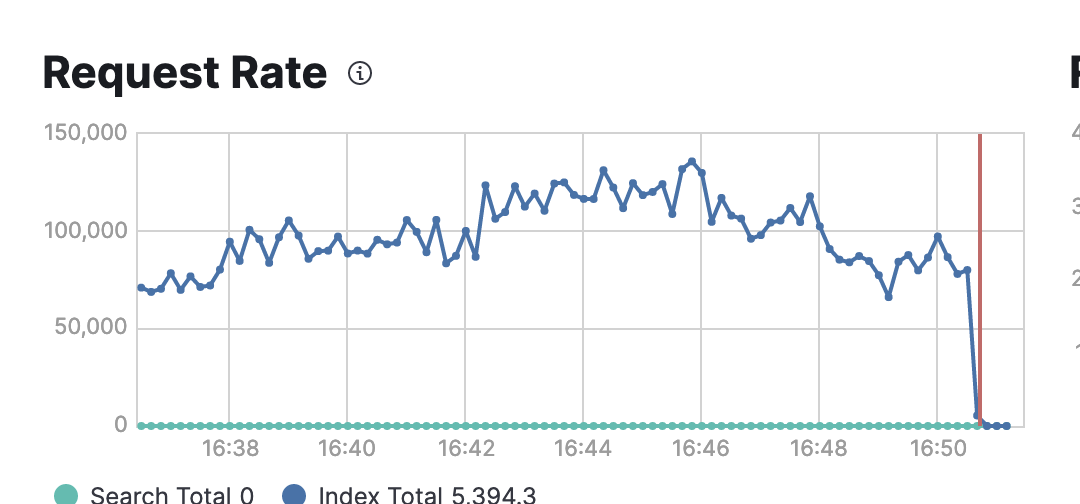
Is it possible to boost the timeout and make it configurable?
Thanks, @bvolpato! I did a mistake in my index configuration leading to large shards and, thus, long latencies in writing/reading data. After reconsidering the number and size (<50GB) of shards, things have started to work smoother. In combination with a rollover policy that can be configured over Index Lifecycle Management, it is even better. It would be OK to close the issue.
Thanks for the feedback, @MarxDimitri.
@melpomene do you think any of that can help you? Or maybe you want to open a separate issue with your details so we can keep track of it? Also interested to see if there's any other event (for example, auto scaling) around the time where it breaks. Configurable timeout may be feasible, but if you got it turn to a no-throughput scenario, sounds like something actually got into a bad state.
Thanks, investigating together with Elastic support now. It doesn't reproduce when I switched up hardware configuration.
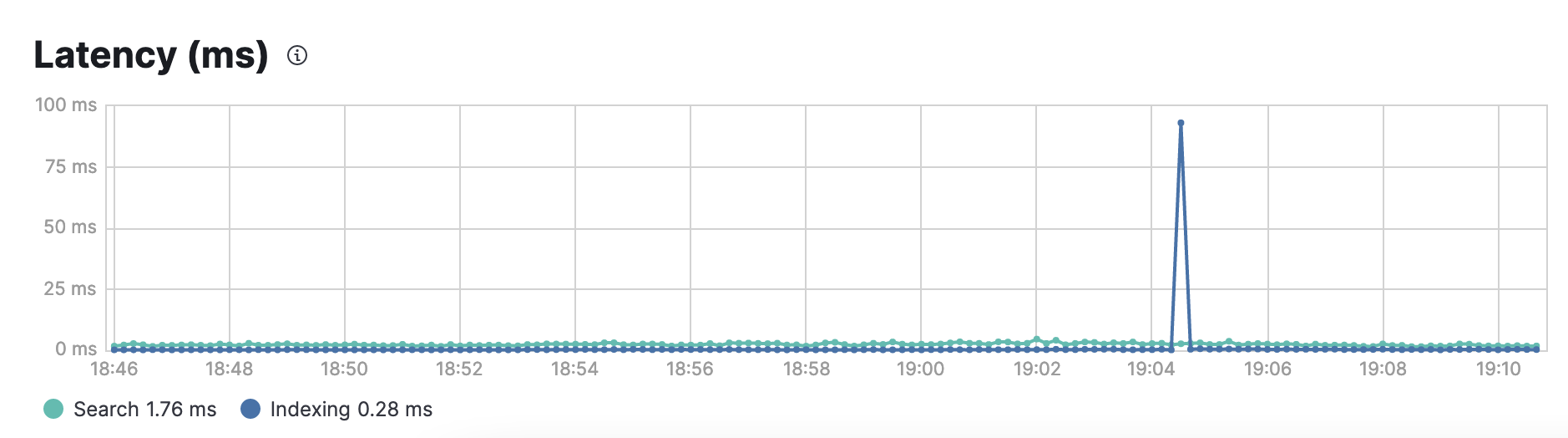
Auto scaling (in terms of the option cloud.elastic.co offers) was turned off. But something like it seems like a likely culprit. Check out the latency graph (peak is where the workers die):
@melpomene what about auto-scaling on the Dataflow job? isn't it being triggered before it gets too overwhelming to Elasticsearch?
It immediately scales up to the max number of workers and that happens hour(s) before I see this error.
This issue has been marked as stale due to 180 days of inactivity. It will be closed in 1 week if no further activity occurs. If you think that’s incorrect or this pull request requires a review, please simply write any comment. If closed, you can revive the issue at any time. Thank you for your contributions.
This issue has been closed due to lack of activity. If you think that is incorrect, or the pull request requires review, you can revive the PR at any time.