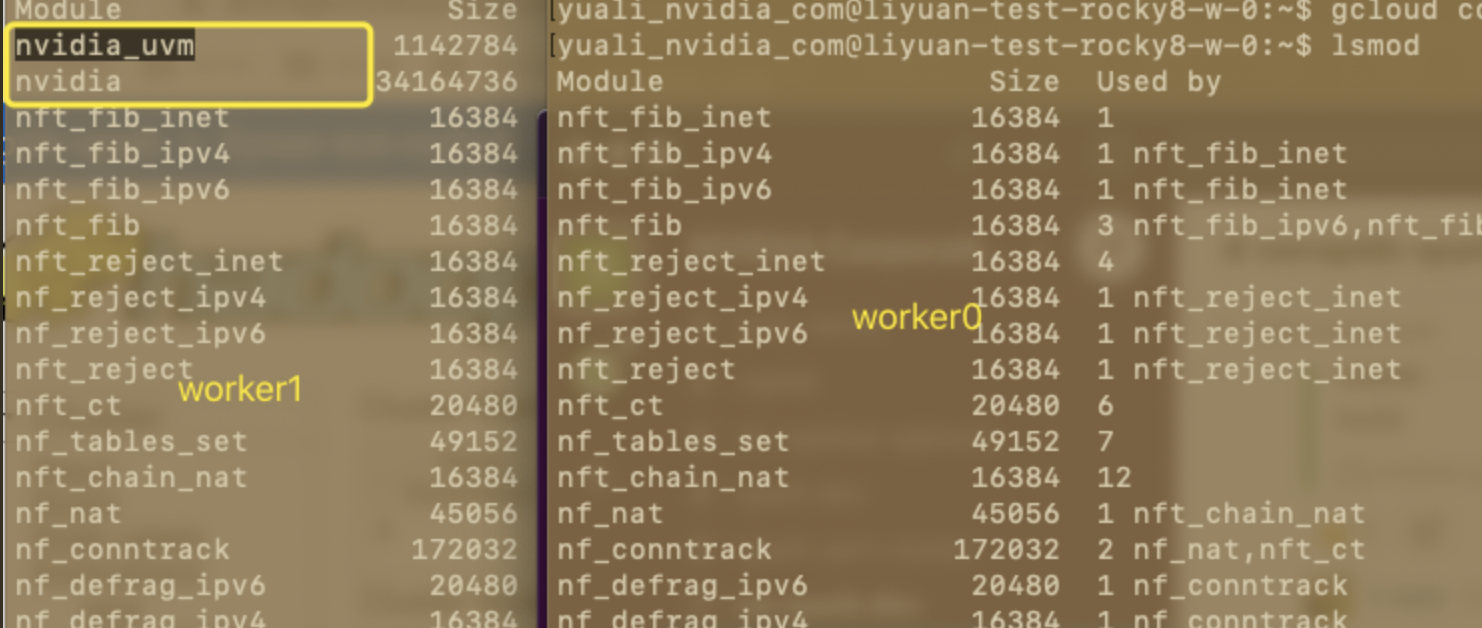
not all worker nodes install modules correctly on 2.0-rocky8 clusters with GPU resource
Command:
gcloud dataproc clusters create $CLUSTER_NAME \
--region $GCS_REGION \
--zone XXX \
--project XXX \
--image-version=2.0-rocky8 \
--master-machine-type n1-standard-4 \
--num-workers $NUM_WORKERS \
--subnet default \
--worker-machine-type n1-standard-4 \
--initialization-actions XXXX/install_gpu_driver.sh,XXXX/rapids.sh \
--metadata gpu-driver-provider="NVIDIA" \
--metadata rapids-runtime=SPARK \
--metadata cuda-version="$CUDA_VER" \
--worker-accelerator type=nvidia-tesla-t4,count=$NUM_GPUS \
--optional-components=JUPYTER,ZEPPELIN \
--bucket $GCS_BUCKET \
--enable-component-gateway \
nvidia_uvm and nvidia module are not installed in work0, the cluster will hang

diff dataproc-initialization-script-0_output ../w-1/dataproc-initialization-script-0_output
119,126d118
< bash-4.4.20-4.el8_6.x86_64
< dbus-1:1.12.8-18.el8_6.1.x86_64
< dbus-common-1:1.12.8-18.el8_6.1.noarch
< dbus-daemon-1:1.12.8-18.el8_6.1.x86_64
< dbus-libs-1:1.12.8-18.el8_6.1.x86_64
< dbus-tools-1:1.12.8-18.el8_6.1.x86_64
< device-mapper-8:1.02.181-3.el8_6.2.x86_64
< device-mapper-libs-8:1.02.181-3.el8_6.2.x86_64
128,132d119
< kernel-headers-4.18.0-372.19.1.el8_6.x86_64
< kernel-tools-4.18.0-372.19.1.el8_6.x86_64
< kernel-tools-libs-4.18.0-372.19.1.el8_6.x86_64
< kpartx-0.8.4-22.el8_6.1.x86_64
< libdnf-0.63.0-8.1.el8_6.x86_64
134,143d120
< openssl-1:1.1.1k-7.el8_6.x86_64
< openssl-devel-1:1.1.1k-7.el8_6.x86_64
< openssl-libs-1:1.1.1k-7.el8_6.x86_64
< pcre2-10.32-3.el8_6.x86_64
< pcre2-devel-10.32-3.el8_6.x86_64
< pcre2-utf16-10.32-3.el8_6.x86_64
< pcre2-utf32-10.32-3.el8_6.x86_64
< python3-hawkey-0.63.0-8.1.el8_6.x86_64
< python3-libdnf-0.63.0-8.1.el8_6.x86_64
< python3-perf-4.18.0-372.19.1.el8_6.x86_64
145,152d121
< rng-tools-6.14-6.git.b2b7934e.el8_6.x86_64
< selinux-policy-3.14.3-95.el8_6.1.noarch
< selinux-policy-targeted-3.14.3-95.el8_6.1.noarch
< systemd-239-58.el8_6.3.x86_64
< systemd-libs-239-58.el8_6.3.x86_64
< systemd-pam-239-58.el8_6.3.x86_64
< systemd-udev-239-58.el8_6.3.x86_64
< tuned-2.18.0-2.el8_6.1.noarch
156,160d124
< vim-minimal-2:8.0.1763-19.el8_6.4.x86_64
< Installed:
< kernel-4.18.0-372.19.1.el8_6.x86_64
< kernel-core-4.18.0-372.19.1.el8_6.x86_64
< kernel-modules-4.18.0-372.19.1.el8_6.x86_64
182c146
< kernel-devel-4.18.0-372.19.1.el8_6.x86_64
---
> kernel-devel-4.18.0-372.16.1.el8_6.0.1.x86_64
427d390
< ++ sed -n 's/.*version[[:blank:]]\+\([0-9]\+\.[0-9]\).*/\1/p'
428a392
> ++ sed -n 's/.*version[[:blank:]]\+\([0-9]\+\.[0-9]\).*/\1/p'
Hi @medb , not sure can you please help with this issue? Since spark-rapids supports Rocky8 since the 22.08 version which will soon release, customers will hit this issue while spinning up the Rocky8 cluster.
@nvliyuan - I created a rocky8 cluster with GPU but did not run the install_gpu_driver.sh script, instead I ran this gpu installation script.
Below is the output from master and workers
Master
Fri Oct 14 11:27:39 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.46 Driver Version: 495.46 CUDA Version: 11.5 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 76C P0 34W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Worker 0
Fri Oct 14 11:27:48 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.46 Driver Version: 495.46 CUDA Version: 11.5 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 77C P0 35W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Worker 1
Fri Oct 14 11:27:54 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.46 Driver Version: 495.46 CUDA Version: 11.5 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 77C P0 34W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Therefore, can we use this script in the install_gpu_driver.sh to setup the drivers with the correct kernel headers and then allow the current logic to configure yarn and spark configurations to remain as it is.
@pulkit-jain-G - FYI.