gerapy.spider文件是有问题吗?
看了大佬发的视频,我按照同样的步骤配置了相同网站的爬虫,但是爬虫每次都爬取不到信息。后面我将生成的scrapy项目中的爬虫文件里的
from gerapy.spiders import CrawlSpider
改成了
from scrapy.spiders import CrawlSpider
才能够正常爬取,不知道原因是啥?
CrawlSpider 里面是对 Scrapy 的 CrawlSpider 进行了改写,变动还不少,增加了一些参数,这些可配置化功能不太敢保证一定稳定,如果方便的话,看能否将生成的 Scrapy 项目上传一下,我来排查下是什么问题。
麻烦大佬了!
------------------ 原始邮件 ------------------ 发件人: "崔庆才丨静觅"<[email protected]>; 发送时间: 2020年1月30日(星期四) 上午10:38 收件人: "Gerapy/Gerapy"<[email protected]>; 抄送: "1839938674"<[email protected]>;"Author"<[email protected]>; 主题: Re: [Gerapy/Gerapy] gerapy.spider文件是有问题吗? (#135)
CrawlSpider 里面是对 Scrapy 的 CrawlSpider 进行了改写,变动还不少,增加了一些参数,这些可配置化功能不太敢保证一定稳定,如果方便的话,看能否将生成的 Scrapy 项目上传一下,我来排查下是什么问题。
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub, or unsubscribe.
测试了下,的确发现是我 Gerapy 的 Rule 编写的问题,估计你之前的错误是:
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spidermiddlewares/urllength.py", line 37, in <genexpr>
return (r for r in result or () if _filter(r))
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable
for r in iterable:
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spidermiddlewares/depth.py", line 58, in <genexpr>
return (r for r in result or () if _filter(r))
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spiders/crawl.py", line 112, in _parse_response
for request_or_item in self._requests_to_follow(response):
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/gerapy/spiders/crawl.py", line 151, in _requests_to_follow
r = self._generate_request(index, rule, link, response)
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/gerapy/spiders/crawl.py", line 108, in _generate_request
url = furl(link.url).add(rule.params).url if rule.params else link.url
AttributeError: 'Rule' object has no attribute 'params'
我进行了一些修复,放在了 master,之前的错误没有了,但现在测着还是有点小问题:
2020-02-11 03:01:53 [scrapy.core.scraper] ERROR: Spider error processing <GET https://tech.china.com/article/20190520/20190520293312.html> (referer: None)
Traceback (most recent call last):
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spiders/crawl.py", line 101, in _response_downloaded
rule = self._rules[response.meta['rule']]
KeyError: 'rule'
我会再修复一下试试,尽快发布一个较为稳定的版本,发布之后回复您。
期间您可以先临时将 gerapy 改成 scrapy 来使用。
好的,非常感谢!
------------------ 原始邮件 ------------------ 发件人: 崔庆才丨静觅 <[email protected]> 发送时间: 2020年2月11日 03:15 收件人: Gerapy/Gerapy <[email protected]> 抄送: hellokuls <[email protected]>, Author <[email protected]> 主题: 回复:[Gerapy/Gerapy] gerapy.spider文件是有问题吗? (#135)
测试了下,的确发现是我 Gerapy 的 Rule 编写的问题,估计你之前的错误是: File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spidermiddlewares/urllength.py", line 37, in <genexpr> return (r for r in result or () if _filter(r)) File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/core/spidermw.py", line 84, in evaluate_iterable for r in iterable: File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spidermiddlewares/depth.py", line 58, in <genexpr> return (r for r in result or () if _filter(r)) File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spiders/crawl.py", line 112, in _parse_response for request_or_item in self._requests_to_follow(response): File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/gerapy/spiders/crawl.py", line 151, in _requests_to_follow r = self._generate_request(index, rule, link, response) File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/gerapy/spiders/crawl.py", line 108, in _generate_request url = furl(link.url).add(rule.params).url if rule.params else link.url AttributeError: 'Rule' object has no attribute 'params'
我进行了一些修复,放在了 master,之前的错误没有了,但现在测着还是有点小问题: 2020-02-11 03:01:53 [scrapy.core.scraper] ERROR: Spider error processing <GET https://tech.china.com/article/20190520/20190520293312.html> (referer: None) Traceback (most recent call last): File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks current.result = callback(current.result, *args, **kw) File "/usr/local/Caskroom/miniconda/base/envs/gerapy/lib/python3.6/site-packages/scrapy/spiders/crawl.py", line 101, in _response_downloaded rule = self._rules[response.meta['rule']] KeyError: 'rule'
我会再修复一下试试,尽快发布一个较为稳定的版本,发布之后回复您。
期间您可以先临时将 gerapy 改成 scrapy 来使用。
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub, or unsubscribe.
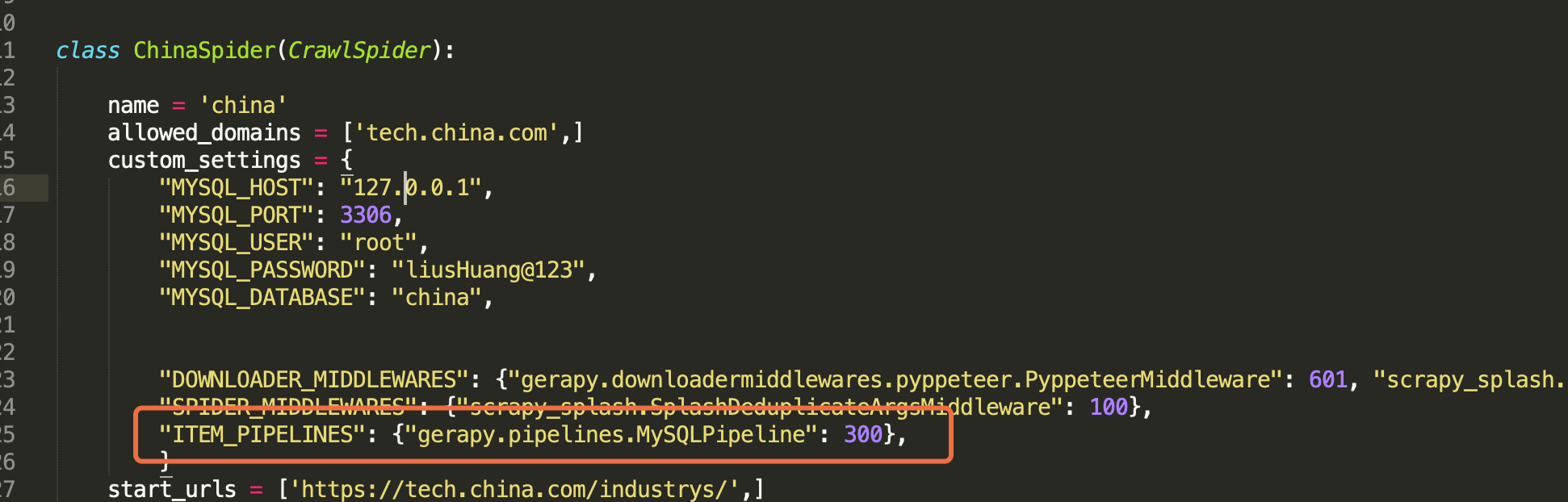 发现了个新的错误,经过简单的排查,发现是下面红框这句话报错
发现了个新的错误,经过简单的排查,发现是下面红框这句话报错
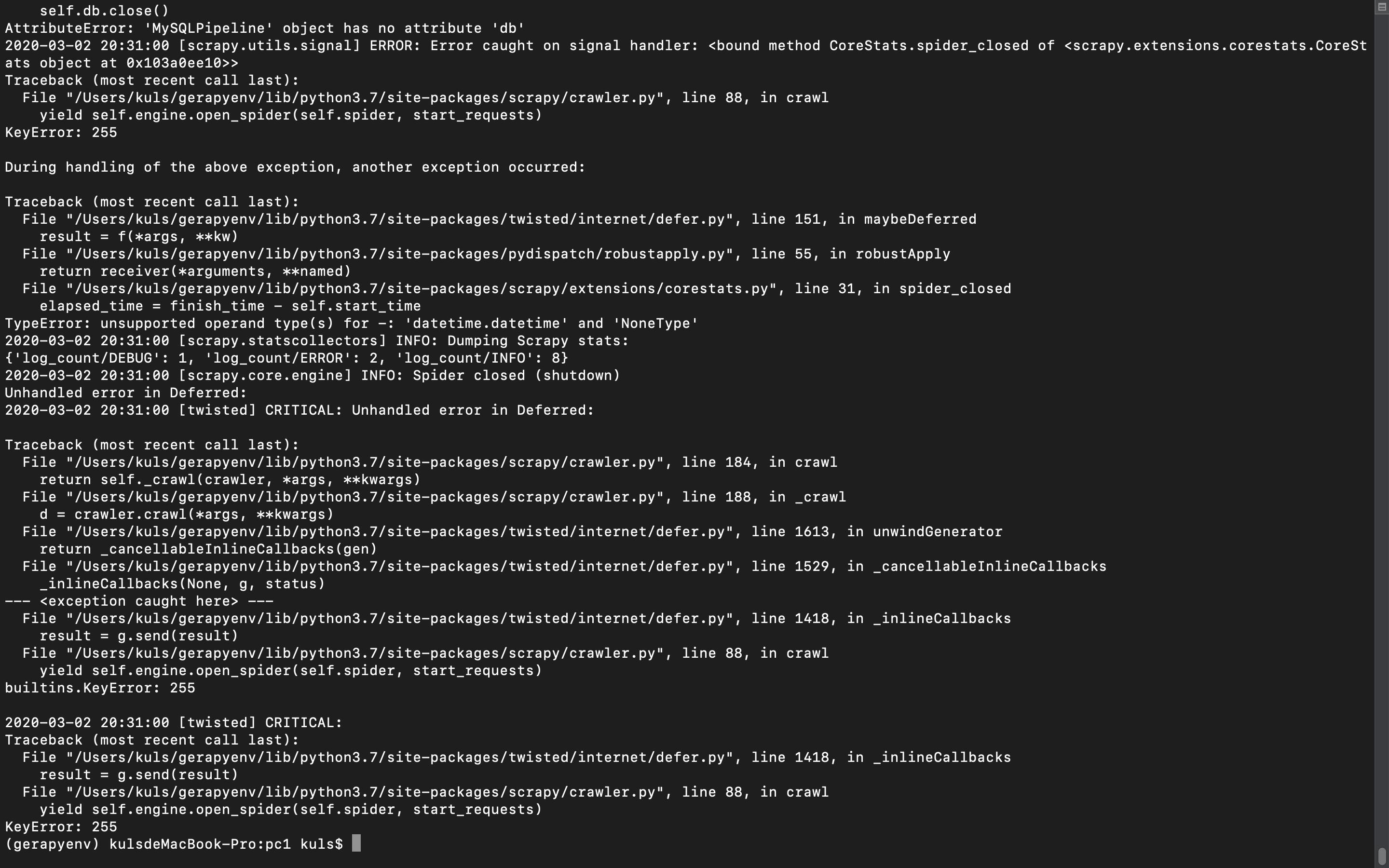
mysql的中间件出问题,我用scrapy运行爬虫,无法保存到数据库。
我之前说的gerapy.spider文件,麻烦大佬尽快修复一下,感谢!