Blog
 Blog copied to clipboard
Blog copied to clipboard
如何构建可靠的Twitter实时广告计费架构
原文:How we fortified Twitter's real time ad spend architecture
推特是广告商与受众接触的一个热门平台。当广告商发起一个新的计划(campaign)时,他们会指定一个广告预算(budget),限制他们将花费多少钱。Twitter的Ad Server校验计划的预算,以确定是否继续出广告。如果没有这种校验,我们可能会在计划达到其预算限制后继续出广告,但却无法对账户扣费(charged)。这种情况我们称为超支或超投(overspend)。
超支可能导致Twitter的收入损失(因为机会成本,比如:本来我们可以在这个广告位(slot)显示其他广告),所以建立可靠的系统来防止超支是非常重要的
名词解释
- campaing - 计划层级
- budget - 预算,指的是广告主在campaign(计划)中设置的预算
- spend - 消耗,指的是一个广告事件触发后广告平台应该收取广告主的费用,消耗并不完全等于实际消费
- engagement - 行为/交互/参与:指的是客户看见广告后与之产生的任何互动,比如点击、评论、分享
- overspend - 超支、超投,指消耗总额已经到达预算上限后继续产生的消耗
- slot - 广告位
- audiences - 广告受众
- pipline - 数据流,本意是流水线,但是为了避免和CI中的流水线作区分,这里翻译成数据流我觉得更恰当
- Data Center - 缩写:DC,数据中心或者叫机房也行
背景
广告服务数据流(ad serving pipline)的简单架构图如下:
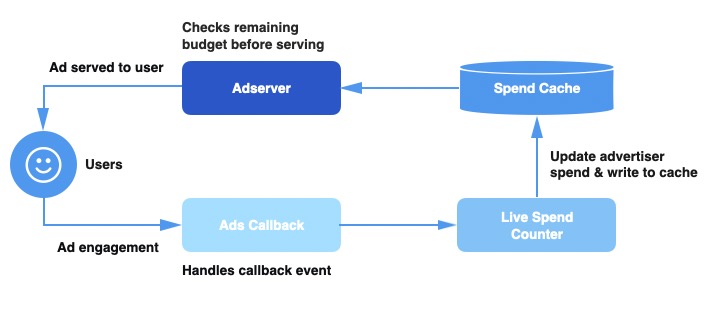
- 消耗缓存(Spend Cache):用于跟踪每个计划当前预算消耗的分布式缓存
- 实时消耗Conuter(Live Spend Counter, LSC):于聚合广告行为(engagement)更新消耗缓存,服务构建在Apache Heron
- 广告回调(Ads Callback):一个数据流,处理输入的行为事件(engagement event)并为事件补充一些上下文信息,然后把它们发送到LSC中
- 广告服务(Ad Server):也是一个数据流,决定一个广告是否展现。对于每一个广告请求(ad request),会从Spend Cache中获取当前广告所在计划的消费。(Note:Ad Server是一个术语,但在这里我们用它指代把广告输出给用户的多个服务,通过这个链接可以了解这些服务)
- 当用户在Twitter上广告进行交互,我们会下发一个行为事件到Ads Callback数据流。当LSC收到了这个事件,就会根据事件计算消耗,然后更新到Spend Cache中。每个输入的广告请求Ad Server会请求Spend Cache获取当前计划的总消耗,然后根据剩余预算(budget)决定是否展示这个广告。
超支(overspend)
给定我们需要处理的一定范围的广告事件(Twitter每秒需要处理上百万个跨所有数据中心(data center)的广告事件),在整个数据流中高延迟(latencies)或者硬件故障可能在任何时候发生。如果Spend Cache不能精确累加消耗然后更新计划消耗,那么Ad Server就会拿到过期的消耗信息,继续出一些已经到达最大预算的计划。但广告平台却不能扣减超出预算的余额,与此同时而我们本可以出一些还没有将预算耗尽的计划下的广告,最终导致Twitter收入的损失。
举个例子,假如有一个计划每天的预算是¥100,CPC价格(price-per-click,这里用国内通用术语“CPC价格”替代)是$0.01。在没有任何超支的理想情况下,每天可以为这个计划产出1w次点击。
 假如Ads Callback数据流或Live Spend Counter发生故障,导致Spend Cache没有更新,丢了价值$10的广告事件。那么Spend Cache中就会只有$90的消耗,而实际在计划上已经消耗了$100。这个计划就会免费拿到1k次额外点击
假如Ads Callback数据流或Live Spend Counter发生故障,导致Spend Cache没有更新,丢了价值$10的广告事件。那么Spend Cache中就会只有$90的消耗,而实际在计划上已经消耗了$100。这个计划就会免费拿到1k次额外点击
跨DC一致性(Consistency Across Data Centers)
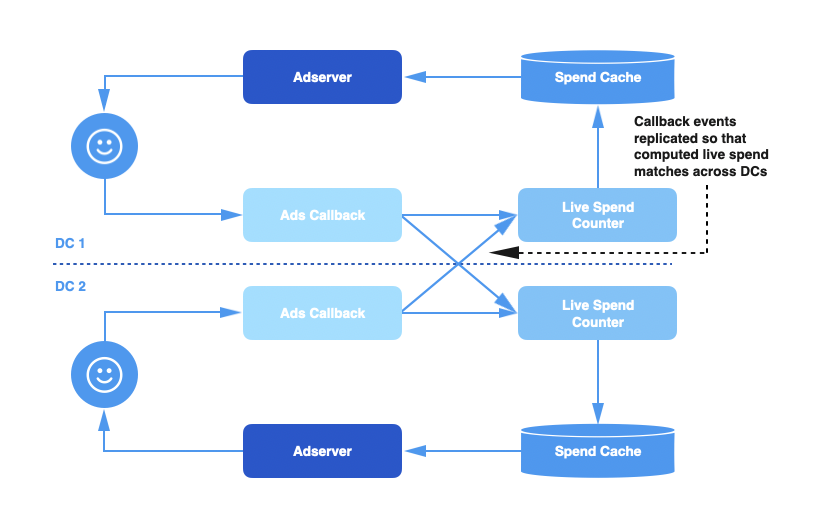
Twitter有多个DC(Data Center),每个DC都有一整份广告服务数据流(ad serving pipline)的副本,包含了Ads Callback Pipline、Live Spend Counter、Spend Cache。当用户和广告发生交互行为,广告回调事件就会被路由到一个DC中,然后首先被Ads Callback数据流处理
这就带来一个问题,每个DC都独立计算自己接收到的广告行为(engagment)事件和总消耗,而广告主的预算是跨数据中心的,这意味着每个DC中的消耗信息是不完整的,任何广告主的实际消耗可能被低估了。
为了解决这个问题,我们在回调事件队列(callback event queue)中加入了跨DC复制机制,所以每个DC都处理全量的广告行为事件,这样可以保证每个DC的消耗数据都是准确的。
PS:从图中看就是Ads Callback和Live Spend Counter采用MQ进行通信,原来用的是单个Queue,这个Queue只由同DC的Live Spend Counter消费。改进后增加了N个Queue,N等于DC数,每个Queue由对应DC的Live Spend Counter消费,每个DC中Spend Cache存储的都是全量计划消耗。这种方案可以提供最终一致性。
单DC故障(Singele Data Center Failures)
尽管复制广告交互事件可以为我们提供更好的一致性和更精确的消耗信息,但系统容错性(fault tolarant)仍然不太好。比如在某几周,跨DC复制故障了,就会有一些事件丢了或者延迟了(lagging),那么Spend Cache中的数据就会被污染。Ads Callback数据流会在GC停顿或单DC网络抖动(unreliable network connection)的时候发生事件处理延迟。但既然这是单DC问题,同DC部署的Live Spend Counter和Spend Cache也会有同等比例的延迟,最终导致超支。
之前我们通过停用故障DC的Live Spend Counter来实现故障转移,然后让另一个DC的Live Spend Counter双写Spend Cache(既写自己的Spend Cache,也写故障DC的Spend Cache),直到Ads Callback和Live Spend Counter没有延迟,并追上了当前的事件消费速度。
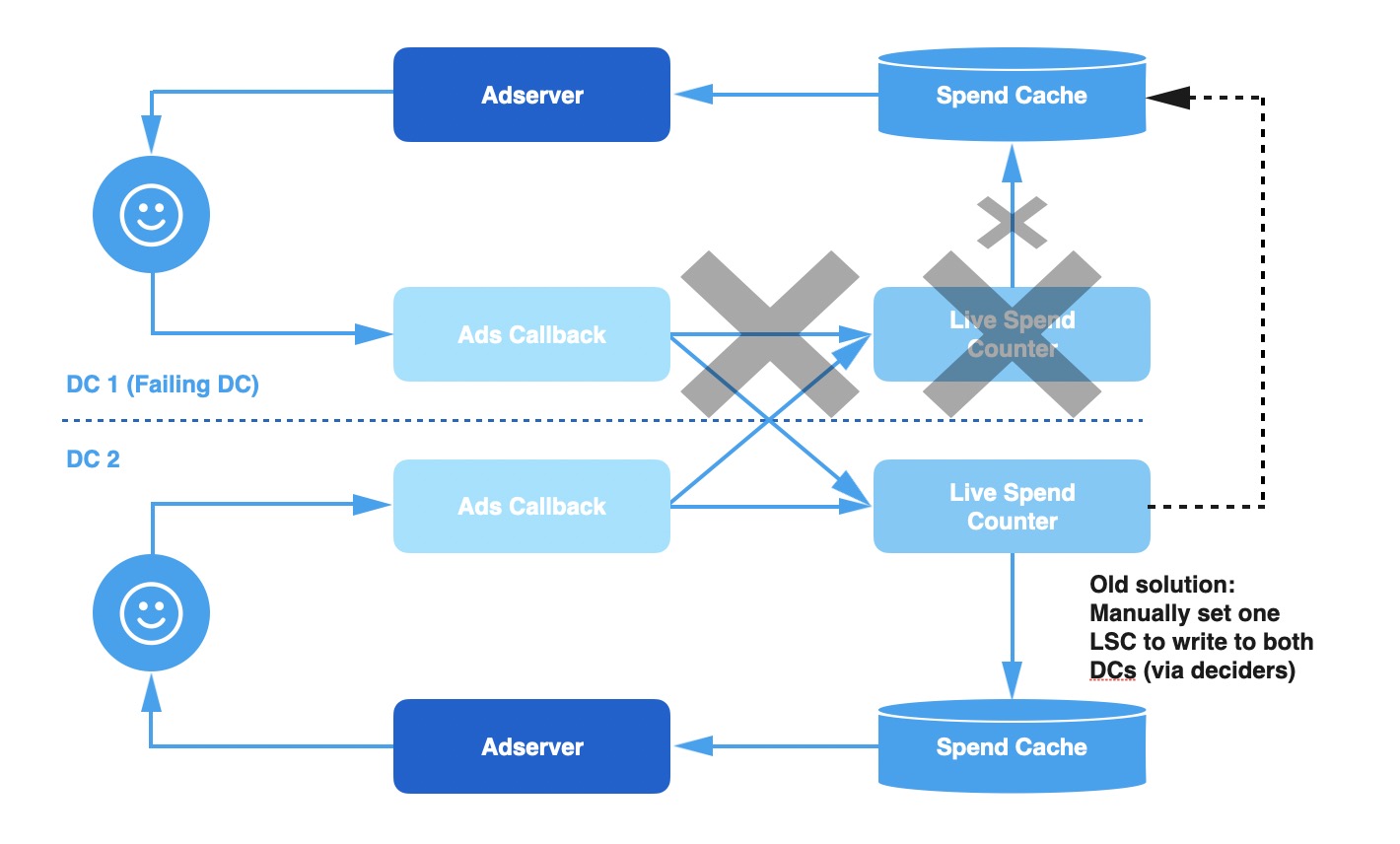 这种方法可以暂时性的避免超支,但有几个主要缺点:
这种方法可以暂时性的避免超支,但有几个主要缺点:
- 需要手动切换双写:启用Live Spend Counter跨DC写是需要手动处理的,其中需要按一定顺序做很多配置的变更。我们最终把这部分工作脚本化了,但oncall的值班工程师仍然需要手动跑脚本
- 需要手动选择DC:需要手动选择哪一个DC是健康的,哪一个DC可以安全做跨DC写入。当Ads Callback延迟问题修复后还需要把配置改回来,这也需要很多个oncall值班人协作处理,这中间可能还涉及跨团队沟通。
- 运维负担重:因为出问题的是个Callback服务,由于需要很多手动操作来维护这套方案,所以有很高的操作成本
跨DC写入方案(Cross Data Center Writes Solution)
由于当前架构存在很多问题,我们重新设计了数据流。目标是在更有弹性(resilient)的应对故障、更少的人工介入(operator intervention)。这个方案包含两个主要的组件:
- 跨DC写入(Cross Data Center Writes):Live Spend Counter一直保持双写Spend Cache,一个是写入同DC的Spend Cache,另一个是写入备用(alternate)DC的Spend Cache,在图中就是Alt-DC-Spend Data。同时也写入描述当前数据健康状况的元数据(metadata)。每个Live Spend Counter实例维护了两个不同的数据集,一个通过本地信息计算出来,另一个通过远程实例的信息计算出来。
- 数据集健康检查(Dataset Health Check):当我们处理一个广告请求的时候,Ad Server数据流读取两上述两个版本的数据,自动基于数据集的健康状况选择一个
在正常情况下系统和之前的运行方式一样,当本地的Spend Cache数据落后了,Ad Server就可以检测到故障,然后自动使用由远程DC写入的数据集。当故障被解决了或者在两份数据健康状况相同的情况下,Ad Server会自动切换回由本地写入的数据版本
如何做数据集的健康检查?
我们决定数据健康的标准是从以下两种常见的故障中总结出来的:
- 延迟(Lag):事件量超出Ads Callback或Live Spend Counter的最大吞吐量就会出现lag。事件是根据写入顺序有序处理的,所以我们倾向于处理过最近事件的数据集。
- 消息丢失(Missing Event):在一些故障case中,有可能消息完全丢了。比如其中一个Ads Callback中做跨DC复制的Queue写入失败了,那么就会有一个DC的丢了一些远程消息。而我们的系统中每个DC都处理全量消息,我们就应该选择处理消息总数最大的数据集
为了构建一个兼顾两种因素的健康检查策略,我们引入一个叫做**消耗直方图(spend histogram)**的概念
消耗直方图(spend histogram)
假设我们有一个滑动窗口(rolling window),它描述的是给定时间内每个DC中的Live Spend Counter处理的实时广告交互事件总数。我们将滑动窗口的范围设置为:保留最近1min内每毫秒处理了多少消息,超出滑动窗口范围的累加值就丢弃。这样我们可以根据其中的数据得出一个消耗直方图,直方图描述的是Live Spend Counter在最近60s内处理的事件总数。假如直方图画出来应该是像下面这样:(纵坐标是消息总数,横坐标最近0-60秒)
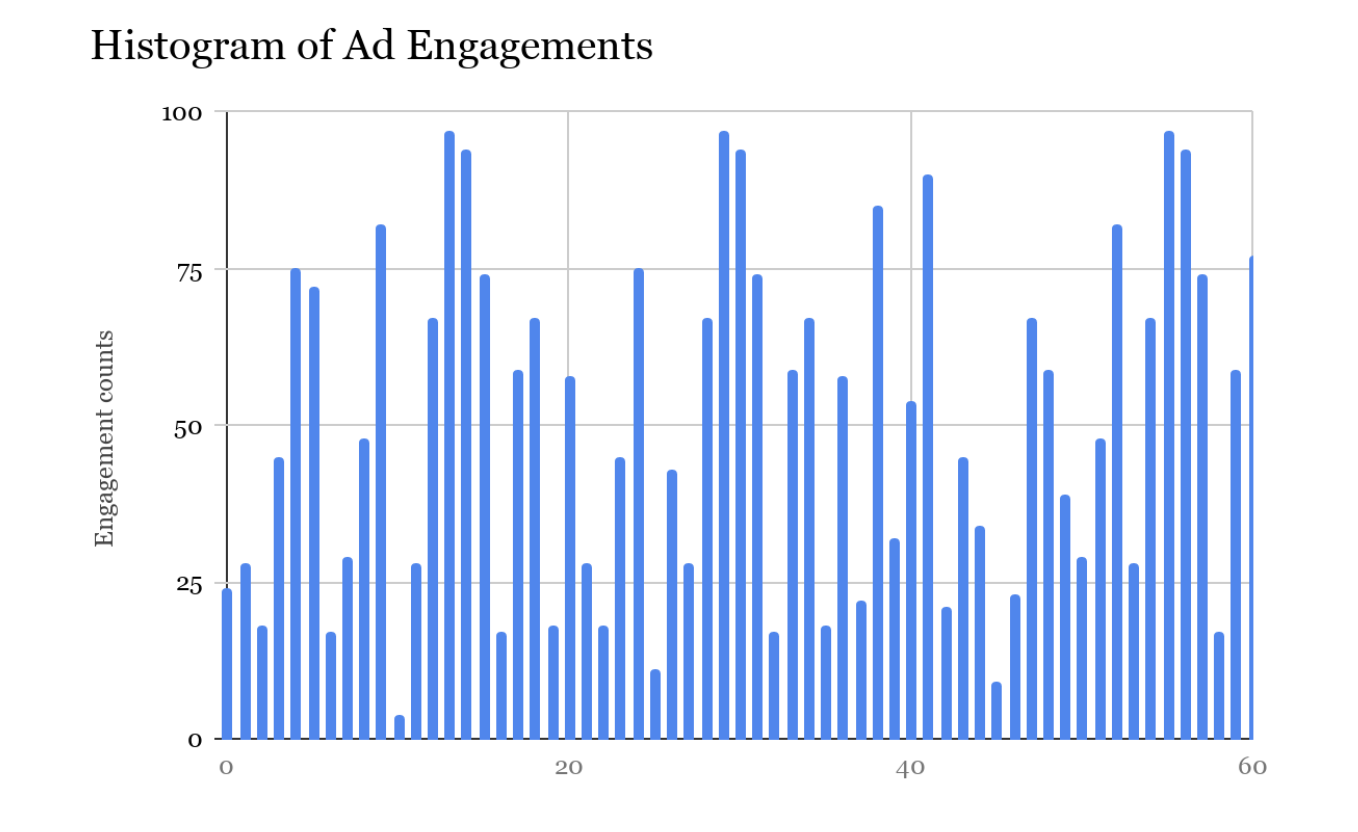 在ads serving侧可以根据这个直方图和最近的消息时间戳来决定哪一个最佳的消耗数据集。Live Spend Counter会把这个信息作为元数据,然后把这个元数据和消耗数据一起写入到Spend Cache中
在ads serving侧可以根据这个直方图和最近的消息时间戳来决定哪一个最佳的消耗数据集。Live Spend Counter会把这个信息作为元数据,然后把这个元数据和消耗数据一起写入到Spend Cache中
Live Spend Counter不会在执行写操作的时候做整个直方图的序列化/反序列化。在写操作之前,它就会持续加总和聚合时间窗口中count值。使用一个近似的count就足够了,它只是用作表示当前DC的Live Spend Count健康状况的signal。为什么用它做signal呢?因为假如Live Spend Counter或Ads Callback出现严重故障,那么这个count就会显著下降。如果故障不严重,那么count值相差也不会很多。
刚刚提到的元数据结构如下所示:
struct SpendHistogram {
i64 approximateCount;
i64 timestampMilliSecs;
}
当处理一个请求的时候,Ad Server读取本地和远程的数据集,然后根据下面的DC选择策略使用Spend Histogram判断使用哪一个消耗数据集
DC选择策略(Data Center Selection)
选择数据集的逻辑如下所示:
- 从两个DC中获取Spend Histogram
- 倾向于使用选择时间戳近的、count数大的
- 如果两份数据集很相近,或他们都处于健康状态,那么更倾向于使用本地数据集。这样做是为了避免因为很小的延迟就在两个数据集间反复切换(PS:这个问题可能挺严重的,数据集如果反复切换可能丢消息)
以上逻辑可以用下面这个真值表(truth table)来描述:
- x = 本地时间戳- 远程时间戳 = LocalTimestampMilliSecs - RemoteTimeStamp
- y = 本地Count - 远程Count = LocalApproxCount - RemoteApproxCount
- ts = 时间戳阈值 = ThresholdTimeStamp
- tc = Count阈值 = ThresholdApproxCountPercent
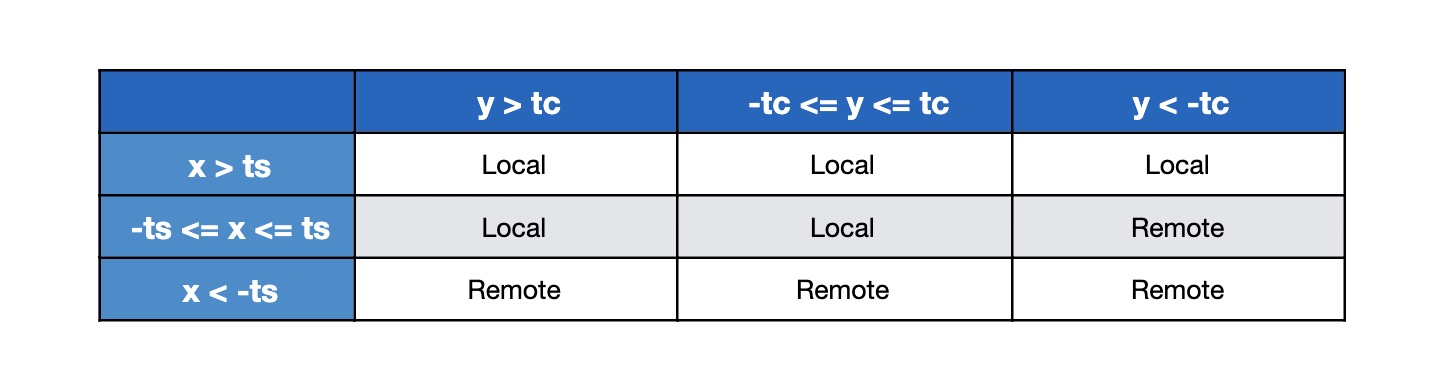 我们使用
我们使用ts和tc决定切换数据源的阈值。如你所见,在阈值内我们更偏向(bias)使用本地数据集。阈值需要能够让我们在切换数据集之前尽早的检测到故障,为此我们做了一些实验。每次处理广告请求的时候Ad Server都需要执行DC选择策略,所以我们把这个阈值放到本地缓存每秒刷新一次,避免频繁查询导致影响整体性能。
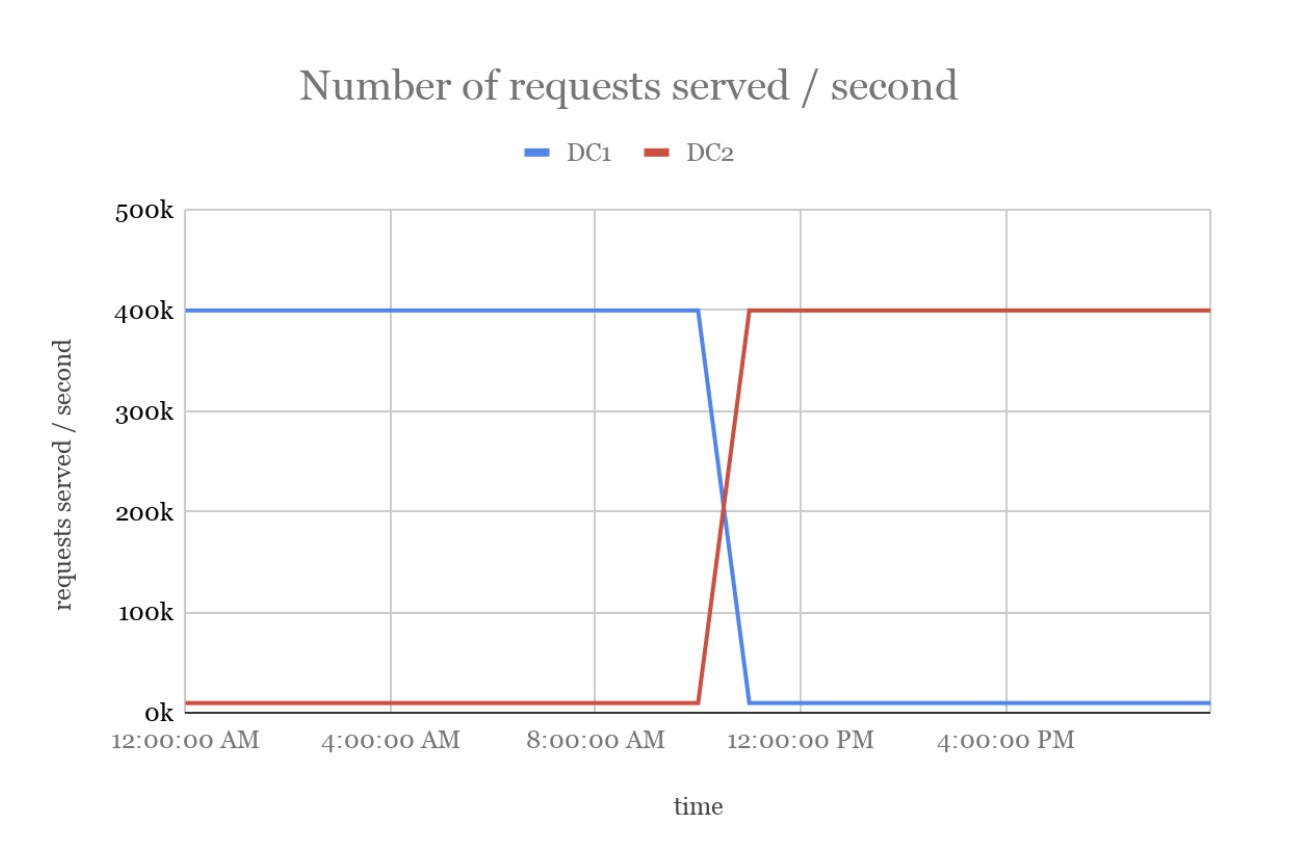
通过下图以可视化的方式展现了从一个DC切换到另一个DC是如何发生的。当前DC1中的LSC发生故障,Ad Server自动选择DC2中的数据集
扩展到N个DC(Extension for n-DCs)
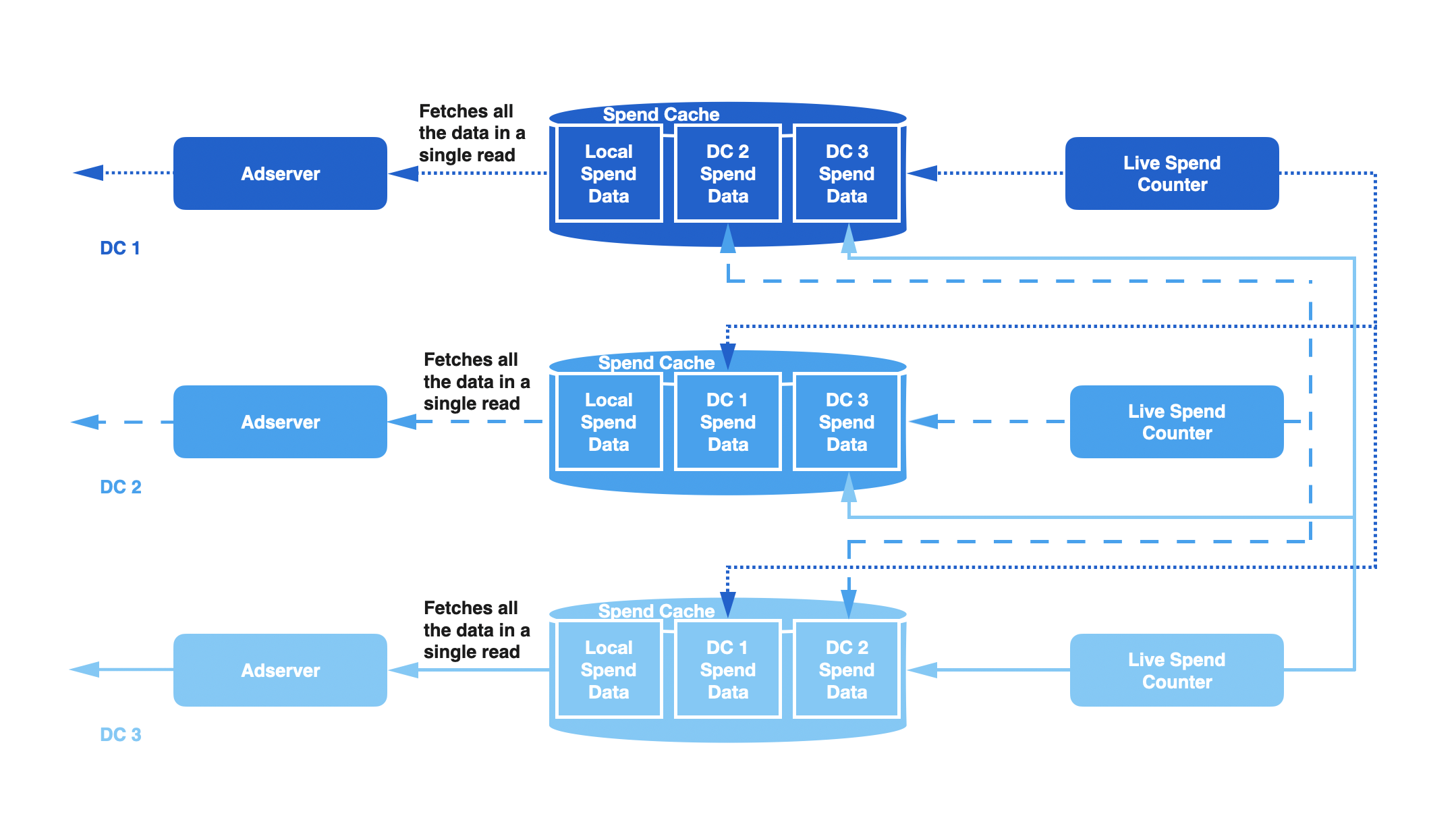
我们目前讨论只涉及2个DC。通过在跨DC写入(cross data center)组件中引入**复制因子(Replication Factor)**把这个方法扩展到N个DC。Replication Factor控制的是Live Spend Cache写入的远程DC数。在Ad Server读取链路上逻辑相同,仍然选择最健康的数据集,但需要在一个读操作(批量读)中获取所有数据
举个例子,假设我们把Replication Factor设置为2,DC1中的LSC将会写入DC1、DC2、DC3的Spend Cache;DC2的LSC将会写入DC2、DC3、DC4;DC3的LSC将会写入DC3、DC4、DC1,以此类推。下图展示了3个DC的写入过程。在每个DC中,Ad Server会读取3份Spend Histogram的拷贝从中选择最适合的。基于网络和存储限制,在实际场景中我们设置的Replication Factor = 2。
影响和结论
在完成了这些升级之后,我们立刻发现团队的运维成本负担下降了。我们从过去每个季度都会有几个超支的线上事故,到最近半年事故数已经降到了0。这解放了大量用于运维问题的工程时间,也避免了由于架构问题导致的广告主赔付(returning credits)
通过定义系统健康指标、并根据这些指标设计足够简单且可自动化的的工程方案,我们最终解决了一个影响数据流正确性的问题。这不仅提供了系统容错性和弹性,也解放了工程资源。