Ошибка метода ночной сборки "Новый ЧтениеZipФайла()"
При попытке прочитать zip архив, выдает ошибку что в пути переданном на чтении содержатся недопустимые символы.
Воспроизведение ошибки
-
Запустить код: ZipФайлОбновления = "C:\1cv8.zip"; ФайлZip = Новый ЧтениеZipФайла(ZipФайлОбновления);
-
Увидеть ошибку

Окружение
- ОС: Windows 7
- Версия OS: 1.1.0.325
Дополнительная информация Приложить архив не получается, он более 10 метров, который пытается считать скрипт, но этот архив с сайта 1С обновление на последнюю версию УТ 10.3, и проблема не в нем точно.
Дополнительная информация из телеги - на стабильном движке работает, проблема в ночнике.
Запустил на чистых исходниках develop - ошибки нет. Код примера скопировал из этой задачи. Просьба уточнить способ вопроизведения. У меня нет ошибки на вот этом коде в TestApp.
ZipФайлОбновления = "C:\1cv8.zip";
ФайлZip = Новый ЧтениеZipФайла(ZipФайлОбновления);
Видимо дело в архиве. Можно выложить куда-то на файлообменник и прислать ссылку в личку (в телеграм или на [email protected]
https://yadi.sk/d/iEtjT_N1p-sosA Может конечно и в архиве, но очень странно все, на версии что я указал выше ошибка воспроизводилась, после удаления и установки стабильной версии, стало работать нормально.
Путь в архиве таки содержит недопустимые знаки:
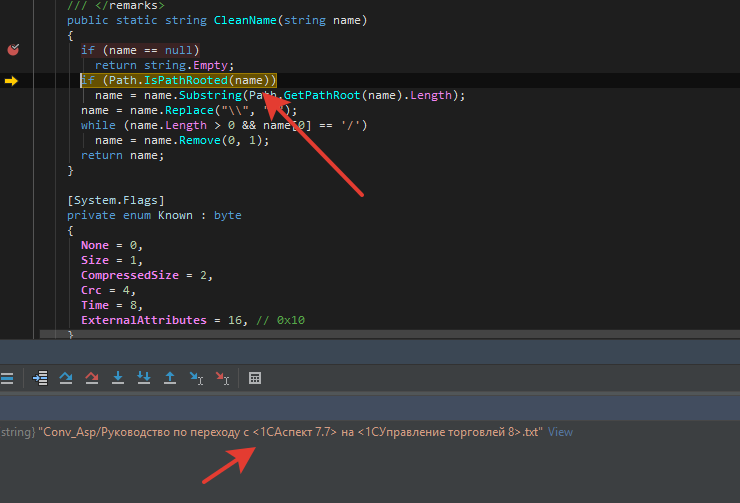
При открытии архива штатными архиваторами видим, что там используется Юникодная кавычка «». Где-то в дебрях ICSharpZibLib она превращается в угловую скобку. Занятно, нечего сказать :)
Encoding.GetEncoding(866).GetString(new byte[]{60}) = "<"
Ну вот как-то так .NET конвертирует символы. Есть ли у кого-то идеи, почему именно так? @dmpas?

интересующее место в строке: индексы 34-36 по переходу с32-60-49САспект
32 - пробел 60 - символ '<' 49 - символ '1'
В архиве от 1С - "по переходу с «1САспект.."
Проблема в исходном архиве, точнее в архиваторе, которым он сделан.
Имена в формате UTF-8 хранятся в zip-архиве в ExtraField, а базовое имя - в кодировке 866.
Архиватор 1С переводит символы, отсутствующие в cp866 по своим правилам, в частности, « и » меняются на < и > соответственно. Из Руководство по переходу с «1САспект 7.7» на «1CУправление торговлей 8» получается Руководство по переходу с <1САспект 7.7> на <1CУправление торговлей 8>.
Видимо, ICSharpZibLib работает только с базовым именем, игнорируя имя в ExtraField.
@Mr-Rm ICSharpZibLib поддерживает флаг Юникода, но отрабатывает его, видимо не всегда. Я уже делал 1 PR и 2 issue в этот проект. Его явно забросили. Нашел актуализированную библиотеку DotNetZip, которую добрые люди портировали под Netstandard.
http://build.oscript.io/job/1Script/job/feature%252Fzip-restore/1/
Запустил сборку на новой (старой) либе. Тест @ViktorErmakov на ней прошел.
Тесты прошли. Кто может проверить на линуксе корректность полученного .deb пакета?
http://build.oscript.io/job/1Script/job/feature%252Fzip-restore/1/artifact/output/onescript-engine_1.1.0_all.deb
@nixel2007 @khorevaa @dmpas @pumbaEO ?
Ubuntu 18.04.1 x64: ФайлZip открывается, но ФайлZip.ИзвлечьВсе создает файл с именем Руководство по переходу с <1САспект 7.7>..., игнорируя имя в UTF-8.
@Mr-Rm а если на убунту поставить просто сам движок из приведенного выше deb - там пакет корректный? В нем русские файлы в папке lib - нормальные?
Именно из того пакета и поставил. Посмотрел в lib. Нет, русские имена в неверной кодировке.
Просмотрел исходники и DotNetZip, и ICSharpZibLib. В них никак не обрабатывается Unicode Path Extra Field. Все флаги работы с кодовыми страницами и Юникодом действуют только на основное имя файла. Поэтому обе библиотеки с такими zip-файлами будут поступать согласно с https://github.com/EvilBeaver/OneScript/blob/75fd033e328292c1365ea7419badd72beb5a0962/src/ScriptEngine.HostedScript/Library/Zip/ZipReader.cs#L49
Ну этот камент был актуален до 8.3.9. После в 1С появилось-таки управление кодировкой в зипе. И у нас даже задачка на это есть.
@EvilBeaver я не совсем понимаю, как я могу помочь в проверке :) единственное, на что я натыкался в линуксе - это битая установка opm из деба. перезапускал вчера сборку ovm, который тянет последний ночник на трависе - он все так же падает :(
Ну собственно, так и помочь: Объяснить мне - какой файл при каких действиях выглядит неправильно. С такой помощью, я быстрее войду в контекст и смогу починить
- скачиваем deb пакет с ночника
- ставим его через dpkg -i
- пробуем вызвать opm
- получаем ошибку, что "не найдена библиотека ../core
- заходим в каталог opm/src/core
- видим, что вместо Классы и Модули папки называются кодировочными кракозябрами
- переименовываем папки
- opm работает
Установка из zip при этом (через ovm) названия папок делает корректные.
Мне кажется, изначальная проблема с ЧтениеZipФайла() не решена и не решается без исправления в библиотеке.
С DotNetZip.dll то же самое. Выполняем в 1С:
КаталогTMP=КаталогВременныхФайлов();
ФайлТест = КаталогTMP+"«test».txt";
ФайлTXT = Новый ФайловыйПоток(ФайлТест, РежимОткрытияФайла.Создать);
ФайлTXT.Закрыть();
ZipФайлТест = КаталогTMP+"testUTF8.zip";
ФайлZip = Новый ЗаписьZipФайла(ZipФайлТест,,,,,,КодировкаИменФайловВZipФайле.UTF8);
ФайлZip.Добавить(ФайлТест);
ФайлZip.Записать();
Получаем файл testUTF8.zip, 196 байт (посмотрите в hex-редакторе, будет понятна проблема). Выполняем в OneScript:
КаталогTMP=КаталогВременныхФайлов();
ZipФайлТест = КаталогTMP+"testUTF8.zip";
ФайлZip = Новый ЧтениеZipФайла(ZipФайлТест);
ФайлZip.ИзвлечьВсе(КаталогTMP);
ФайлZip.Закрыть();
Получаем Ошибка в строке: 4 / Внешнее исключение (System.ArgumentException): Illegal characters in path.} ФайлZip.ИзвлечьВсе(КаталогTMP);
Прочие архиваторы извлекают «test».txt.
Поведение 1С тоже сомнительно, т.к. для КодировкаИменФайловВZipФайле не различаются UTF8 и КодировкаОСДополнительноUTF8, а Авто как раз соответствует нормальному UTF-8.
И с этим всем надо как-то работать.
На свежем ночнике 1.1 сценарий не воспроизводится. Файл, созданный 1С-кой с угловыми кавычками «» распаковывается 1Скриптом корректно, с учетом угловых кавычек.
C каким значением последнего параметра (Кодировка) создавался файл в 1С? Размер полученного файла? Сценарий, приведенный выше падает, как и раньше. 1C 8.3.14.1779 OneScript 1.1 develop (a7176cb) DotNetZip.dll 1.13.3.506f11
C каким значением последнего параметра (Кодировка) создавался файл в 1С? Размер полученного файла?
я скопипастил пример из комментария выше. Значит, параметр был КодировкаИменФайловВZipФайле.UTF8.
Размер полученного файла: 200 байт, 1С 8.3.12.1469
Нашел. Это, фактически, баг в 1С - разное поведение при разной разрядности платформы.
В тестовом сценарии:
При параметре КодировкаИменФайловВZipФайле.Авто 1С x32 и x64 выдают файлы длиной 200 байт (отличающиеся!), которые OneScript успешно распаковывает.
При КодировкаИменФайловВZipФайле.КодировкаОСДополнительноUTF8 обе 1С выдают файлы длиной 196 байт (тоже отличающиеся), на которых OneScript падает.
А вот при КодировкаИменФайловВZipФайле.UTF8 1С x32 работает как при КодировкаОСДополнительноUTF8, а 1С x64 - как при Авто.
Отсюда и расхождение в воспроизведении ошибки. Я проверял на 32-разрядной. В приведенном коде надо написать.
ФайлZip = Новый ЗаписьZipФайла(ZipФайлТест,,,,,,КодировкаИменФайловВZipФайле.КодировкаОСДополнительноUTF8);
и будет падать всегда. Из-за DotNetZip.dll. Локально, у себя я исправлял библиотеку, чтоб работало.
Локально, у себя я исправлял библиотеку, чтоб работало
Как именно? Может им пулреквест сделать, чтобы вошло в библиотеку?
@Mr-Rm Огонь!
а вот эту магию откуда брали? https://github.com/Mr-Rm/DotNetZip.Semverd/blob/c480bdd4ad8cc4abf23856ce69c3412a951617cf/src/Zip.Shared/ZipEntry.Read.cs#L798-L804