Chinese-Word-Vectors

Chinese-Word-Vectors copied to clipboard
使用Evaluation Toolkit评价腾讯词向量内存不够
你好,我自己训练了一份词向量,利用Evaluation Toolkit工具中的ana_eval_dense.py文件评价得到如下结果:
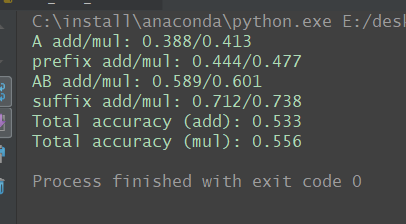 这结果好像比你们提供的几份词向量结果都要好(对比了知乎问答、搜狗新闻词向量)。
然后我现在想用这个工具来检测腾讯词向量效果,无奈文件太大(15.5G),我62.8G内存的机器都不够用,请问ana_eval_dense.py代码中哪里可以优化解决吗?
这结果好像比你们提供的几份词向量结果都要好(对比了知乎问答、搜狗新闻词向量)。
然后我现在想用这个工具来检测腾讯词向量效果,无奈文件太大(15.5G),我62.8G内存的机器都不够用,请问ana_eval_dense.py代码中哪里可以优化解决吗?
https://github.com/Embedding/Chinese-Word-Vectors/blob/46a7b7d86255b35530beb12f765ecd0b23a86c40/evaluation/ana_eval_dense.py#L26 这里的topn设置一下,可以不读取后面的那些低频词,能节省很大的内存。
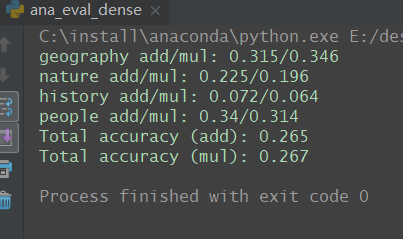
我是用下面这个已经训练好的模型:
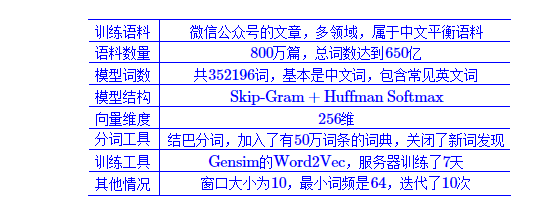 https://kexue.fm/archives/4304
再追加数据(涉政10万文本、涉黄10万文本、正常100万文本)训练得到的
https://kexue.fm/archives/4304
再追加数据(涉政10万文本、涉黄10万文本、正常100万文本)训练得到的
我花了一点时间,支持分块计算了 https://github.com/psy2013GitHub/Chinese-Word-Vectors