YOLOv7
 YOLOv7 copied to clipboard
YOLOv7 copied to clipboard
:fire::fire::fire: Official YOLOv7训练自己的数据集并实现端到端的TensorRT模型加速推断
Hi, do you have the code to run inference not on photos, but on video? Or maybe someone has a solution for yolov7?

out, train_out = model(img, augment=augment) # inference and training outputs ValueError: too many values to unpack (expected 2)
On Chinese: 嗨,当在这里学习是这样的错误,我该怎么办? 我会很感激你的帮助! On English: Hi, when learning here is such a mistake, what should I do? I will be grateful for your help! 
我修改完yolo.py后生成onnx后用你的后处理脚本遇到了一个bug,流程截图如下,通过netron查看是有个红箭头,请问如何解决? 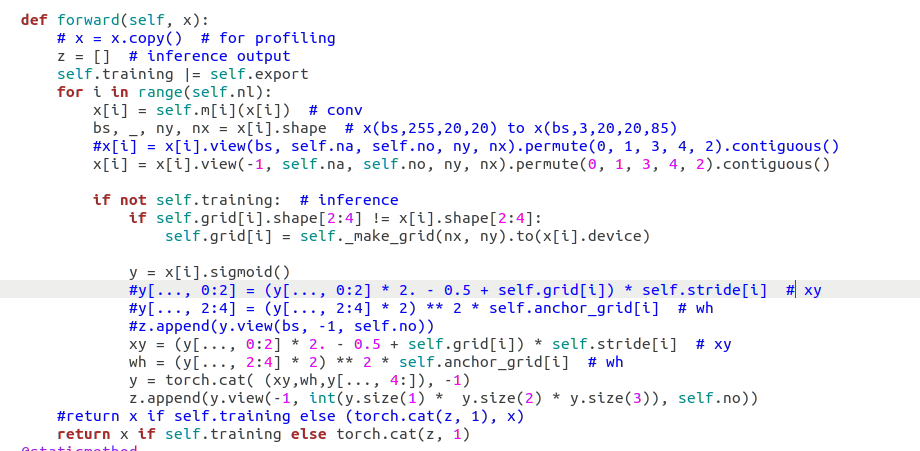   
Metadata
Owner
Metadata
:fire::fire::fire: Official YOLOv7训练自己的数据集并实现端到端的TensorRT模型加速推断