chunjun

chunjun copied to clipboard
hive2starrocks
读取不到hive数据 配置如下(配置为太阿生成) h2star.json.txt
err.log
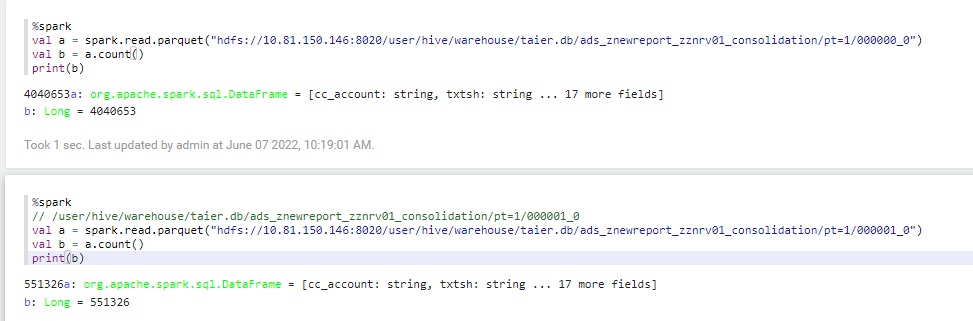
使用spark可以读取
另外window本地测试有个小bug BaseHdfsInputFormat 136行 文件分隔符为\ 导致后边报错数组越界
hdfs reader 配置可能有问题,麻烦参考下,再试试
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFs": "hdfs://namenode.xxxx.net:9000",
"path": "/home/hdp-dir-test/warehouse/dwd/sjptb/pday=20201010",
"fileType": "text",
"fieldDelimiter": "\t",
"column": [
{
"name": "m2",
"type": "string",
"index": 0
},
{
"name": "new_type",
"type": "string",
"index": 1
},
{
"name": "web_pv",
"type": "int",
"index": 2
},
{
"name": "web_dur",
"type": "double",
"index": 3
},
{
"name": "web_pv_movie",
"type": "int",
"index": 4
},
{
"name": "web_dur_movie",
"type": "double",
"index": 5
},
{
"name": "web_pv_sex",
"type": "int",
"index": 6
},
{
"name": "web_dur_sex",
"type": "double",
"index": 7
},
{
"name": "web_pv_novel",
"type": "int",
"index": 8
},
{
"name": "web_dur_novel",
"type": "double",
"index": 9
},
{
"name": "web_pv_illegal",
"type": "int",
"index": 10
},
{
"name": "web_dur_illegal",
"type": "double",
"index": 11
},
{
"name": "pday",
"type": "string",
"index": 12,
"isPart":true
}
],
"hadoopConfig": {
"fs.defaultFS": "hdfs://namenode.xxxx.net:9000",
"dfs.client.failover.proxy.provider.ns": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"hadoop.user.name": "xxxx",
"fs.hdfs.impl.disable.cache": "true",
"fs.hdfs.impl": "org.apache.hadoop.hdfs.DistributedFileSystem"
}
}
}