feapder
 feapder copied to clipboard
feapder copied to clipboard
🚀🚀🚀feapder is an easy to use, powerful crawler framework | feapder是一款上手简单,功能强大的Python爬虫框架。内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。且支持断点续爬...
chrome 的渲染有个问题, selenium + chrome 访问 https://baijiahao.baidu.com/s?id=1739368224007714423 时,浏览器会一直加载一个 js 文件,造成该标签页卡住,然后浏览器就无法响应其他行为(刷新,获取页面源码,访问其他url……),feapder 是否可以加一个参数来禁止加载 js。 如果以上链接失效,请访问以下任意链接: https://baijiahao.baidu.com/s?id=1739304797053642547&wfr=spider&for=pc https://baijiahao.baidu.com/s?id=1739377098661725506&wfr=spider&for=pc https://baijiahao.baidu.com/s?id=1739377692137820326&wfr=spider&for=pc https://baijiahao.baidu.com/s?id=1739377788266450267&wfr=spider&for=pc
https://boris.org.cn/feapder/#/usage/TaskSpider feapder官方文档
日志重复输出

 控制台会重复输出相同的日子
有一个问题哈,scrapy的http/https连接是可以复用的,如图,并发数设为30他就会开30条连接,不会在每次爬取时反复断开重连,非常稳定 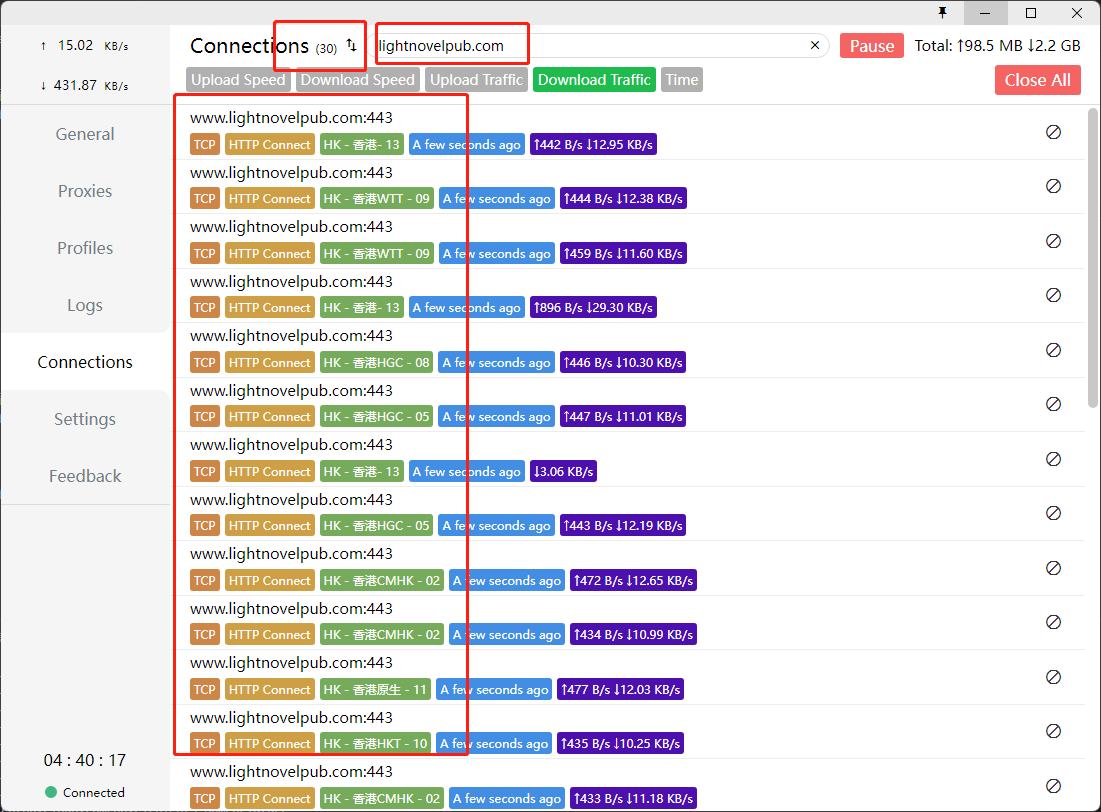 但是feapder的连接,无论我把keep-alive设为true,还是说添加session,都没有办法让请求复用,会不断地断开重连(这个可能是requests库的问题),如图,图中部分线程的连接自动释放掉了,每波任务都会产生30次tcp连接/断开,这个数量始终在波动,并发数高了非常容易报代理错误 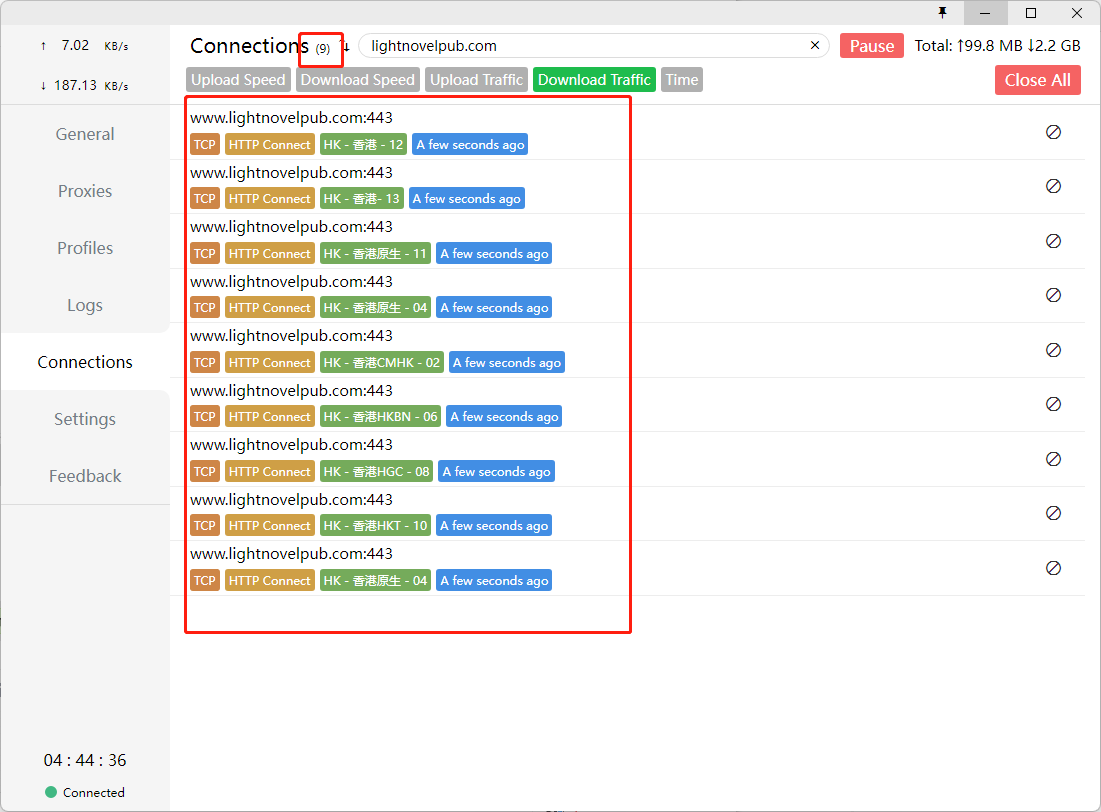 我的代理池是使用负载均衡方式自建的本地隧道代理,差不多每十波左右的任务就会报一次错误,由于连接不断重连/释放,对本地的代理软件也不友好,日志记录飞起,如果开启日志,我的clash能吃掉半个核心和2g的内存 
https://boris.org.cn/feapder/#/source_code/dedup Description
https://boris.org.cn/feapder/#/README Description
就像scrapy的信号机制那样? 我的项目实际运行过程中有两个问题, 代理和token都有限制, 我需要在middleware中先判断两者是否有效, 都有效时修改url/headers/proxies等参数正常请求. 其中一个无效都需要停掉爬虫等待定时任务下次启动. 这个项目又用到batch_spider, 目前的解决方案有些复杂. 检测到代理或token失效时, 把task表中所有非1的任务更新成-1, 让爬虫以为本批次全部完成正常结束; 下次定时任务再把-1改0, 同时还要把record中的完成状态改0, 让爬虫启动~
Metadata
Owner
Metadata
🚀🚀🚀feapder is an easy to use, powerful crawler framework | feapder是一款上手简单,功能强大的Python爬虫框架。内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。且支持断点续爬...