performance enhancement to coargsort
We need to take a look at coargsort to see if we can make it go faster.
@ronawho edit:
The main optimizations that I can think of are:
- [x] merge arrays into a single array and call argsort once -- done in https://github.com/mhmerrill/arkouda/pull/330
- [ ] If merged array is > 32 bytes, call mergedArgsort multiple times instead of falling back to argsort multiple times on each array.
- [ ] limit how much of the KEY is communicated (see https://github.com/mhmerrill/arkouda/issues/296#issuecomment-609063869)
- [ ] enable mergedArgsort for strings as well
- [ ] explore merging into a segmented array instead an array of tuples
- [ ] check if arrays are already sorted, and if so skip putting them in the merged array?
@ronawho this one is more straight forward than the join performance issue.
Sounds good. For both of these a standalone Chapel or Arkouda performance test would be really helpful.
@ronawho I just wanted to get the issue opened... here is more detail. I believe I will write a python test/benchmark because the chapel only version might be a real pain to write. This is a case where the message processing logic is not well factored from the incremental sort logic.
The code path starts here: https://github.com/mhmerrill/arkouda/blob/cf0a92c1e5e19e80c81b1496fcc5a0628ebd82a7/src/ArgSortMsg.chpl#L434
I would focus my attention on the code path which includes regular arrays which goes through here: https://github.com/mhmerrill/arkouda/blob/cf0a92c1e5e19e80c81b1496fcc5a0628ebd82a7/src/ArgSortMsg.chpl#L487-L491
IncrementalArgSort takes a permutation and the next vector to sort and returns a new permutation vector which is the composition of the original permutation and the one from the RadixSortLSD_keys on the next vector
https://github.com/mhmerrill/arkouda/blob/cf0a92c1e5e19e80c81b1496fcc5a0628ebd82a7/src/ArgSortMsg.chpl#L364
@ronawho I was wrong there is already a chapel test/benchmark code, written by @reuster986 the code is here: https://github.com/mhmerrill/arkouda/blob/master/test/UnitTestArgSortMsg.chpl the specific code is here: https://github.com/mhmerrill/arkouda/blob/cf0a92c1e5e19e80c81b1496fcc5a0628ebd82a7/test/UnitTestArgSortMsg.chpl#L90-L134
Here's some quick starting figures for 512 node XC. I'm just using the argsort.py benchmark with ak.argsort(a) replaced with ak.coargsort([a]*iters). I'm using 4 GB arrays (--size=2**29):
| size | argsort(a) | coargsort([a]) | coargsort([a]*2) | coargsort([a]*4) | coargsort([a]*8) |
|---|---|---|---|---|---|
| 2**29 | 96.7 GiB/s | 61.5 GiB/s | 42.6 GiB/s | 26.5 GiB/s | 15.0 GiB/s |
So single array coargsort is 2/3 as performant as argsort, and doubling the number of arrays to sort results in roughly 2/3 as much performance each time.
(and this is probably obvious, but the above isn't a realistic benchmark, since there's no sorting after the first incremental sort. It's probably triggering the isSorted fast path, so the times might just be the IV update and the time to copy the array-to-be-sorted. Times for an actual benchmark would be even slower since we will have sorting/data-movement.)
I think what will end up being important is optimizing repeated calls to radixSortLSD_ranks, and optimizing radixSortLSD_ranks for when the data is mostly sorted. On the first incremental sort the performance will be the performance of just calling radixSortLSD_ranks on the first array. After that though we should have much less data movement and the movement we have will be mostly local.
The current sort really isn't optimized for mostly-sorted data. Sorting a sorted array is only 2x as fast as sorting a random array.
There's also relatively expensive setup for sorting (array allocation, aggregation buffer setup, exchanging meta-data. We should be able to eliminate some of these overheads. Running UnitTestSort.chpl with --elemsPerLocale=1 it takes ~2s to sort, and all of that is the setup time and position calculation.
@ronawho maybe we should use your idea about sorting a tuple of two or maybe three ints. Here is some code where we call the radixSortLSD_ranks on a tuple array for hashed strings if it helps.
https://github.com/mhmerrill/arkouda/blob/55ef6f7cec9b763e75c47a17679ce3eb603004a8/src/SegmentedArray.chpl#L317-L339
Here's a very prototypical branch that merges separate arrays into a combined array and only calls sort once. Currently, it's combining into a 2*uint array to reuse the tuple sorting code you pointed to. Longer term we should combine into an array-of-arrays, or a larger blockdist array that is manually segmented, but to start I just wanted enough to run performance experiments, and so far this shows promise. Here are the results for sorting array(s) whose elements total 8-bytes. Results are for:
-
argsort on 1 8-byte eltType array -
coargsort on 1 8-byte eltType array -
coargsort on 2 4-byte eltType arrays -
coargsort on 4 2-byte eltType arrays
./arkouda_server --logging=false --v=false -nl 256
./benchmarks/coargsort.py --size=$((2**29))
| config | argsort(a8) | coargsort([a8]) | coargsort([a4,b4]) | coargsort([a2,b2,c2,d2]) |
|---|---|---|---|---|
| before | 28.4 GiB/s | 21.3 GiB/s | 14.0 GiB/s | 8.2 GiB/s |
| after | 28.4 GiB/s | 21.4 GiB/s | 21.3 GiB/s | 21.2 GiB/s |
And results for sorting 4 4-byte eltType arrays:
./arkouda_server --logging=false --v=false -nl 256
./benchmarks/argsort.py --size=$((2**29))
| config | coargsort([a4,b4,c4,d4]) |
|---|---|
| before | 6.5 GiB/s |
| after | 11.0 GiB/s |
Ah, and the reason coargsort([a8]) is slower than argsort(a8) isn't because of the time to combine the arrays into one, but because we're exchanging a bigger key (2*uint instead of just int):
https://github.com/mhmerrill/arkouda/blob/23d8052d3efc5d59315063df445400a99c49c304/src/RadixSortLSD.chpl#L198-L208.
I need to look at it more, but I think we should be able to improve that by only copying the KEY bits that we'll need for subsequent iterations. e.g. after we've looked at bits 48-64, we should only need to copy bits 1-48.
I opened a draft PR that implements a cleaned up version of the merged-array approach: https://github.com/mhmerrill/arkouda/pull/330. There are some decent performance improvements for the synthetic workloads I added. Using 256 nodes of an XC with 2**28 element arrays I see:
- 2x speedup for
coargsort([a4, b4])where a4/b4 are int arrays with 32-bit values - 2x speedup for coargsort on 16 arrays with 16-bit values
Can you see how this performs for the workloads you care about? Note that it is only optimizing cases that need 32 or less bytes. (e.g. 8 arrays with 32-bit values), so if you use more bytes we'll need a different strategy.
I'm just now able to steal away and look in detail at your work, @ronawho . I like your strategy, and the performance numbers are very promising!
You mentioned a couple comments ago that the main avenue left for improvement is to copy only the KEY bits needed for subsequent iterations. I agree with that line of thinking, but I'm fairly certain it can be done even more efficiently by only copying the KEY bits needed for the next iteration. I did something like this in SegStringSort.chpl, where I made a version of the radixSortLSD code with a copyDigit subroutine that only copies the next more significant digit according to the current state of the permutation:
https://github.com/mhmerrill/arkouda/blob/a8298ff2d43eb4b32fd1a463741a1c2347ce4fc4/src/SegStringSort.chpl#L158-L198
The code above is designed for segmented arrays, but I think it should be adaptable to an array-of-arrays approach without too much change.
I wish I had time in the coming week to really dig into this and try to prototype something, but with full-time homeschooling and kids being around 24/7, I'm finding it very difficult to do any coding. That said, I'll leave it up to you whether you want to merge your PR as it stands and leave the copy-the-next-digit approach for me to implement later, or whether you want to give it a shot yourself. I'm fine either way.
Ah, interesting. I had been wondering about that myself, but I couldn't convince myself that I only needed to copy the next significant digit instead of all subsequent ones. That's mostly due to me not totally understanding radixsort though. It's not clear to me if each digit is sorted independently, or if the permutation from sorting the previous digit impacts the sorting of the current digit.
A coargsort perf test was added in https://github.com/mhmerrill/arkouda/pull/341. Nightly graphs are available, here's the 16 node XC results
The merged array optimization has been implemented in https://github.com/mhmerrill/arkouda/pull/330. I updated the issue description with remaining optimizations. The most important one is likely minimizing the amount of the KEY that gets communicated. i.e. only communicate the next digit instead of always communicating the entire key. @reuster986 I will likely need help with that one.
Nightly saw the expected speedup from #330. Here's the 16 node XC graphs:
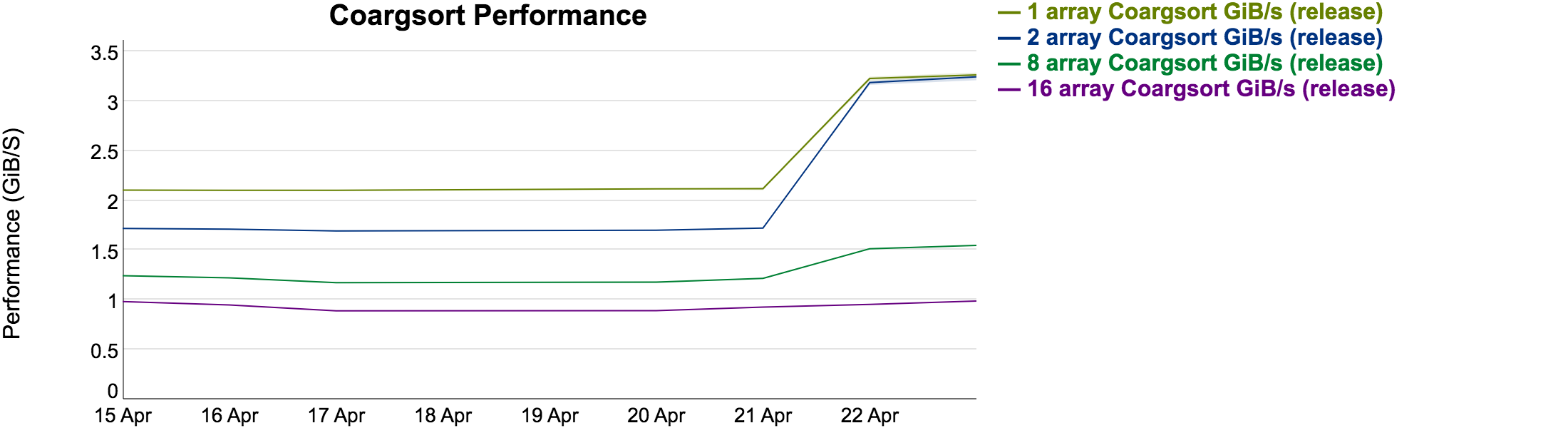
(note that this did increase build time a little, which isn't too surprising especially given that we're stamping out multiple copies for 8, 16, and 32 byte tuples)
@reuster986 @mhmerrill I have been slowly working through my backlog of Arkouda issues. Wanted to check if this one is still important. I think we could make some non-trivial performance improvements for coargsort yet, and I think this is the backbone of groupby, which I think is a key operation for you, but I wanted to check that my understanding is correct.
That's correct: groupby is the most time-consuming kernel for our applications, and coargsort is the majority of groupby, so optimizations to coargsort would help a lot.
I'm interested in @ronawho 's ideas for further optimization, but that might warrant a new issue.
@mhmerrill I'm not sure -- have there been any recent changes? (I'm still catching up after vacation)
So far as I know the first 3 checkboxes in the description are still valid and worth pursuing.
Closing for now, I think there is more that can be done here, but there is no active development. If this becomes a priority again, we can always reopen.