failure saving multi session trials df to hdf5
when i run visual_behavior.ophys.io.create_multi_session_mean_df. get_multi_session_mean_df(experiment_ids, cache_dir, conditions=['cell_specimen_id', 'change_image_name', 'trial_type'])
I get this error. It doesn't happen for any other input conditions. I have assumed that it is because this dataframe ends up being much larger than others, but it could also be an issue with data types.
C:\Anaconda\lib\site-packages\pandas\core\generic.py:1471: PerformanceWarning: your performance may suffer as PyTables will pickle object types that it cannot map directly to c-types [inferred_type->mixed-integer,key->block1_values] [items->['change_image_name', 'trial_type', 'mean_trace', 'sem_trace', 'mean_responses', 'experiment_container_id', 'targeted_structure', 'specimen_driver_line', 'cre_line', 'reporter_line', 'full_genotype', 'session_type', 'stage', 'experiment_date', 'project_id', 'rig', 'image_set']]
return pytables.to_hdf(path_or_buf, key, self, **kwargs)
Traceback (most recent call last):
File "C:/Users/marinag/Documents/Code/visual_behavior_analysis/visual_behavior/ophys/io/create_multi_session_mean_df.py", line 127, in
@matchings did this error show up on the cluster as well? If it only happens on windows it may be related to this: https://stackoverflow.com/questions/38314118/overflowerror-python-int-too-large-to-convert-to-c-long-on-windows-but-not-ma
@nickponvert error shows up on cluster also. here is a cluster job record that failed: "\allen\programs\braintv\workgroups\nc-ophys\Marina\ClusterJobs\JobRecords2\12686038.qmaster2.corp.alleninstitute.org.err"
however I did finally get the thing to save, by removing some of the conditions that went in to the dataframe and effectively making it smaller. This doesn't solve the actual problem of course, but it is a temporary solution.
i am a bit confused because i was running this code to check data types and they are mostly strings or floats:
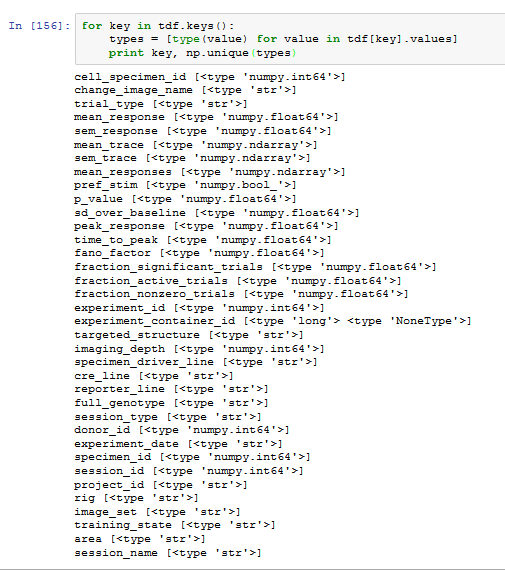
but when i look for types a different way, most are objects:

hopefully there is a hint in there somewhere.
You can check out the dataframe that I got to save here: "\allen\programs\braintv\workgroups\nc-ophys\visual_behavior\visual_behavior_production_analysis\multi_session_summary_dfs\mean_trials_change_image_name_trial_type_df.h5"
And the code to generate it is in visual_behavior.ophys.io.create_multi_session_mean_df.
you can see the function call in the main at the bottom of that script. it is specifically giving problems when i try to run it with trial_type as a condition, presumably because it results in a larger dataframe, with this function call: get_multi_session_mean_df(experiment_ids, cache_dir, conditions=['cell_specimen_id', 'change_image_name', 'trial_type'])