Online:When using load data to import data in CSV format, the empty string in the data will become null
Bug Description
When using load data to import data in CSV format, the empty string in the data will become null
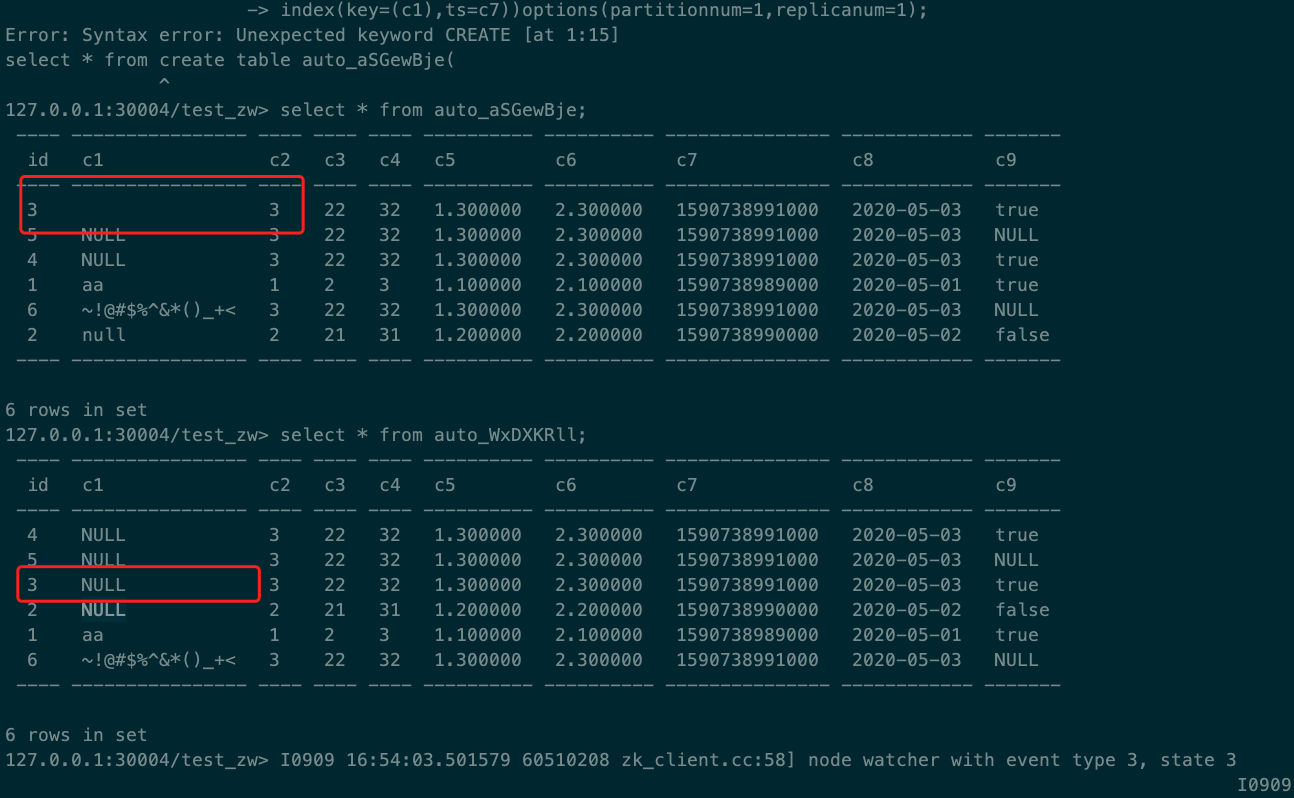
select into result:
Expected Behavior
Relation Case test_select_into_load_data.yaml id:0-1. 0-2
Steps to Reproduce
create table auto_YuMSwEvO(
id int,
c1 string,
c2 smallint,
c3 int,
c4 bigint,
c5 float,
c6 double,
c7 timestamp,
c8 date,
c9 bool,
index(key=(c1),ts=c7))options(partitionnum=1,replicanum=1);
insert into auto_YuMSwEvO values
(3,'',3,22,32,1.3,2.3,1590738991000,'2020-05-03',true);
create table auto_FwREKcjN(
id int,
c1 string,
c2 smallint,
c3 int,
c4 bigint,
c5 float,
c6 double,
c7 timestamp,
c8 date,
c9 bool,
index(key=(c1),ts=c7))options(partitionnum=1,replicanum=1);
set @@SESSION.execute_mode = "online";
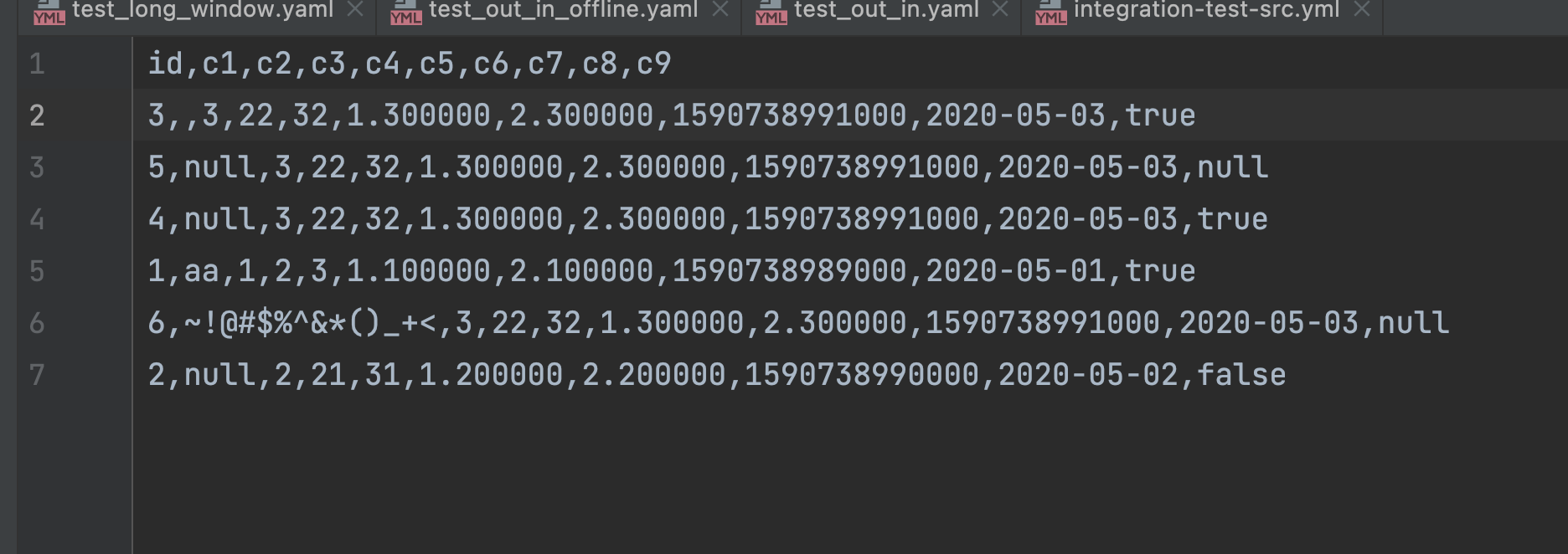
select * from auto_YuMSwEvO into outfile '/Users/zhaowei/code/4paradigm/OpenMLDB/auto_YuMSwEvO.csv' ;
LOAD DATA INFILE 'file:///Users/zhaowei/code/4paradigm/OpenMLDB/auto_YuMSwEvO.csv' into table auto_FwREKcjN options(mode='append');
spark simple test:
c1, c2
"", null
, null
The line 2 will be read as null,null in spark. So we write it to openmldb.
test code:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
path = "string.csv"
df = spark.read.option("header","true").option("nullValue","null").csv(path)
df.show()
result:
>>> df.show()
+----+----+
| c1| c2|
+----+----+
| |null|
|null|null|
+----+----+
Since Spark 2.4, empty strings are saved as quoted empty strings "". ref https://spark.apache.org/docs/3.3.0/sql-migration-guide.html#upgrading-from-spark-sql-23-to-24
We should make online select into save empty string as "". Keep consistent with offline select into.
- [ ] But if we support csv write
"",abc, we can't read it as<empty_string>,abcin standalone mode.
c1,c2
"",null
,null
"",abc
,abc
if no quote option, it will be loaded in openmldb standalone as
---- ------
c1 c2
---- ------
abc
NULL
"" abc
"" NULL
---- ------
if we set quote to '"', it will be all empty string, ,,(blank value) is empty string too:
---- ------
c1 c2
---- ------
abc
abc
NULL
NULL
---- ------
But quote to '"', it will saved as
c1,c2
"","abc"
"","abc"
"",null
"",null
P.S.
I can't find a way to make spark read ,,(blank value) to empty string. And https://stackoverflow.com/questions/54579273/spark-2-read-csv-empty-values can't find too. So we'd better to make online select into saved "", even quote is '\0'.
In Spark 3.2 or earlier, nulls were written as empty strings as quoted empty strings, "". So if we write df to csv file without nullValue option, it'll be
"",""
"",""
Parquet is fine. Be caution of it. It's better to set nullValue to null, if we save csv file. It's the default setting of selectintoplan.
Focus on online mode(spark write to online): if csv is
c1, c2
,
we load data online to openmldb, the online result is:
------ ------
c1 c2
------ ------
NULL NULL
------ ------
So it's empty string in csv, after load to online, it's null. But spark don't treat , as two empty string.
scripts:
create database db;
use db;
set @@execute_mode='online';
set @@sync_job=true;
create table empty_string(c1 string, c2 string);
load data infile 'file:///<>/empty_string.csv' into table empty_string options(mode='append');
select * from empty_string;